MIT Researchers Open-Sourced ‘MADDNESS’: An AI Algorithm That Speeds Up Machine Learning Using Approximate Matrix Multiplication (AMM)

Matrix multiplication is one of the essential operations in machine learning (ML). However, these operations are extensively computationally costly due to the extensive use of multiply-add instructions. Therefore, many studies have focused on estimating matrix multiplies effectively.
GPU and TPU chips perform matrix multiplication faster than CPUs because they can execute many multiply-adds in parallel. This makes them particularly attractive for ML applications. However, they may be too expensive or unavailable for researchers on a tight budget or in resource-constrained applications like IoT. To this end, numerous studies have looked at AMM algorithms, which trade-off matrix multiplication precision for speed.
Earlier this year, researchers from MIT’s Computer Science & Artificial Intelligence Lab (CSAIL) has introduced Multiply-ADDitioN-lESS (MADDNESS). This algorithm does not require multiply-add operations and speeds up ML by employing approximate matrix multiplication (AMM). MADDNESS runs 10x quicker than other approximation algorithms and 100x faster than accurate multiplication. This algorithm is now made open-sourced.
MADDNESS Algorithm
Most AMM algorithms use multiply-add operations. MADDNESS, on the other hand, employs a collection of highly efficient learning hash functions to attain coding rates of 100GB/second with just one CPU thread. The hash functions convert input data into an index into a lookup database with pre-calculated dot-products. Although the approach introduces some output error, the authors show that the error has a theoretical upper bound that can be paid off against speed.
The MADDNESS algorithm makes various assumptions common in ML applications about the matrices that are multiplied, including that they are “large, somewhat dense, and resident in a single computer’s memory.” One matrix, for instance, has fixed values; this may be the weights in an image classification model. The other matrix represents the input data, which may be the image pixels to be classified.
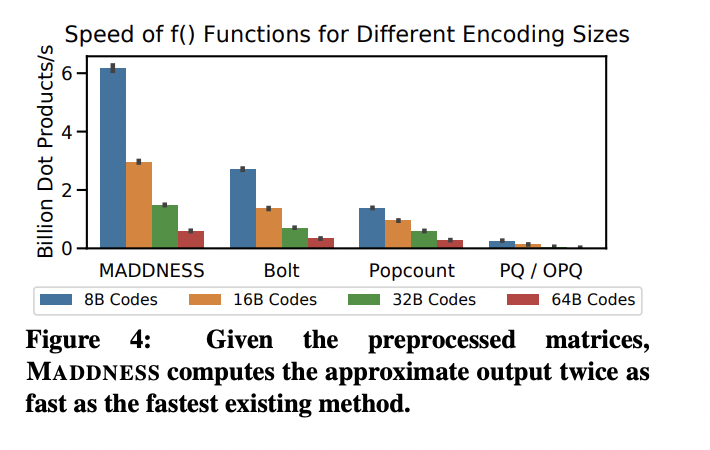
MADDNESS is based on the product quantization (PQ) algorithm, which is a vector quantization approach. PQ analyses a vast number of input vectors to generate a limited number of prototype vectors. Each prototype vector’s products with the fixed weight vector are computed in advance. Then, using a hash function, any new input vector is mapped to its most comparable prototype. This provides an index to the pre-computed product.

MADDNESS uses the pre-processing step to building high-speed hash functions that don’t need multiply-add operations. The functions are built on binary regression trees, with each tree having 16 leaves that represent hash buckets. To map an input vector to a prototype, all that is required is a comparison to the tree splits’ threshold values. MADDNESS also incorporates two-speed enhancements:
- A prototype optimization that selects a set of prototypes that minimizes the original matrix’s reconstruction error
- A fast 8-bit aggregation that aggregates several products using hardware-specific averaging instructions rather than addition.
MADDNESS was compared to six different AMM algorithms, including PCA and Bolt and exact matrix multiplication using BLAS. The AMM methods were used as part of an image classifier, trained and validated on the CIFAR datasets. The findings show that MADDNESS surpassed all other approaches, delivering a much better speed-accuracy trade-off while being 10x faster. The researchers also used kernel classifiers trained on the UCR Time Series Archive datasets to compare MADDNESS to the other methods. The results from these tests suggest that MADDNESS is much faster than alternatives at a given level of accuracy.

Paper: https://arxiv.org/pdf/2106.10860.pdf
GitHub: https://github.com/dblalock/bolt
Source: https://www.infoq.com/news/2021/10/mit-matrix-multiplication/
Suggested
Credit: Source link
Comments are closed.