MIT Researchers Propose A New Multimodal Technique That Blends Machine Learning Methods To Learn More Similarly To Humans
Artificial intelligence is revolutionary in all the major use cases and applications we encounter daily. One such area revolves around a lot of audio and visual media. Think about all the AI-powered apps that can generate funny videos, and artistically astounding images, copy a celebrity’s voice, or note down the entire lecture for you with just one click. All of these models require a huge corpus of data to train. And most of the successful systems rely on annotated datasets to teach themselves.
The biggest challenge is to store and annotate this data and transform it into usable data points which models can ingest. Easier said than done; companies need help gathering and creating gold-standard data points every year.
Now, researchers from MIT, the MIT-IBM Watson AI Lab, IBM Research, and other institutions have developed a groundbreaking technique that can efficiently solve these issues by analyzing unlabeled audio and visual data. This model has a lot of promise and potential to improve how current models train. This method resonates with many models, such as speech recognition models, transcribing and audio creation engines, and object detection. It combines two self-supervised learning architectures, contrastive learning, and masked data modeling. This approach follows one basic idea: replicate how humans perceive and understand the world and then replicate the same behavior.
As explained by Yuan Gong, an MIT Postdoc, self-supervised learning is essential because if you look at how humans gather and learn from the data, a big portion is without direct supervision. The goal is to enable the same procedure in machines, allowing them to learn as many features as possible from unlabelled data. This training becomes a strong foundation that can be utilized and improved with the help of supervised learning or reinforcement learning, depending on the use cases.
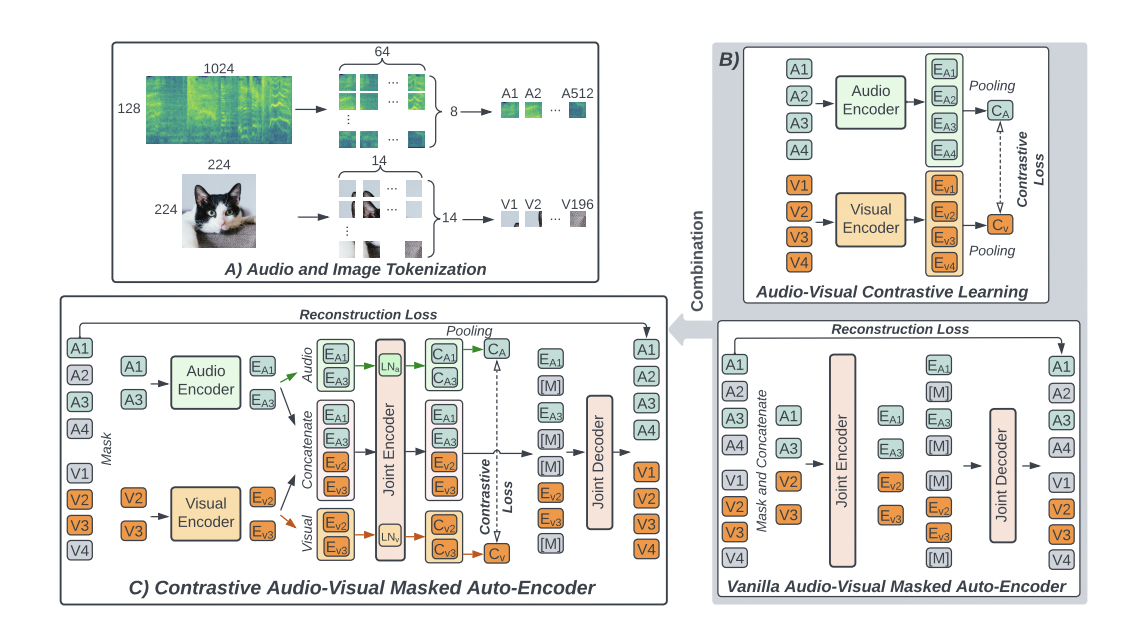
The technique used here is contrastive audio-visual masked autoencoder (CAV-MAE), which uses a neural network to extract and map meaningful latent representations from audio and visual data. The models can be trained on large datasets of 10-second YouTube clips, utilizing audio and video components. The researchers claimed that CAV-MAE is much better than any other previous approaches because it explicitly emphasizes the association between audio and visual data, which other methods don’t incorporate.
The CAV-MAE method incorporates two approaches: masked data modeling and contrastive learning. Masked data modeling involves:
- Taking a video and its matched audio waveform.
- Converting the audio to a spectrogram.
- Masking 75% of the audio and video data.
The model then recovers the missing data through a joint encoder/decoder. The reconstruction loss, which measures the difference between the reconstructed prediction and the original audio-visual combination, is used to train the model. The main aim of this approach is to map similar representations close to one another. It does so by associating the relevant parts of audio and video data, such as connecting the mouth movements of spoken words.
The testing of CAV-MAE-based models with other models proved to be very insightful. The tests were conducted on audio-video retrieval and audio-visual classification tasks. The results demonstrated that contrastive learning and masked data modeling are complementary methods. CAV-MAE outperformed previous techniques in event classification and remained competitive with models trained using industry-level computational resources. In addition, multi-modal data significantly improved fine-tuning of single-modality representation and performance on audio-only event classification tasks.
The researchers at MIT believe that CAV-MAE represents a breakthrough in progress in self-supervised audio-visual learning. They envision that its use cases can range from action recognition, including sports, education, entertainment, motor vehicles, and public safety, to cross-linguistic automatic speech recognition and audio-video generations. While the current method focuses on audio-visual data, the researchers aim to extend it to other modalities, recognizing that human perception involves multiple senses beyond audio and visual cues.
It will be interesting to see how this approach performs over time and how many existing models try to incorporate such techniques.
The researchers hope that as machine learning advances, techniques like CAV-MAE will become increasingly valuable, enabling models to understand better and interpret the world.
Check Out The Paper and MIT Blog. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Anant is a Computer science engineer currently working as a data scientist with experience in Finance and AI products as a service. He is keen to build AI-powered solutions that create better data points and solve daily life problems in an impactful and efficient way.
Credit: Source link
Comments are closed.