MIT Researchers Propose DIFFDOCK: A Diffusion Generative Model Tailored to the Task of Molecular Docking
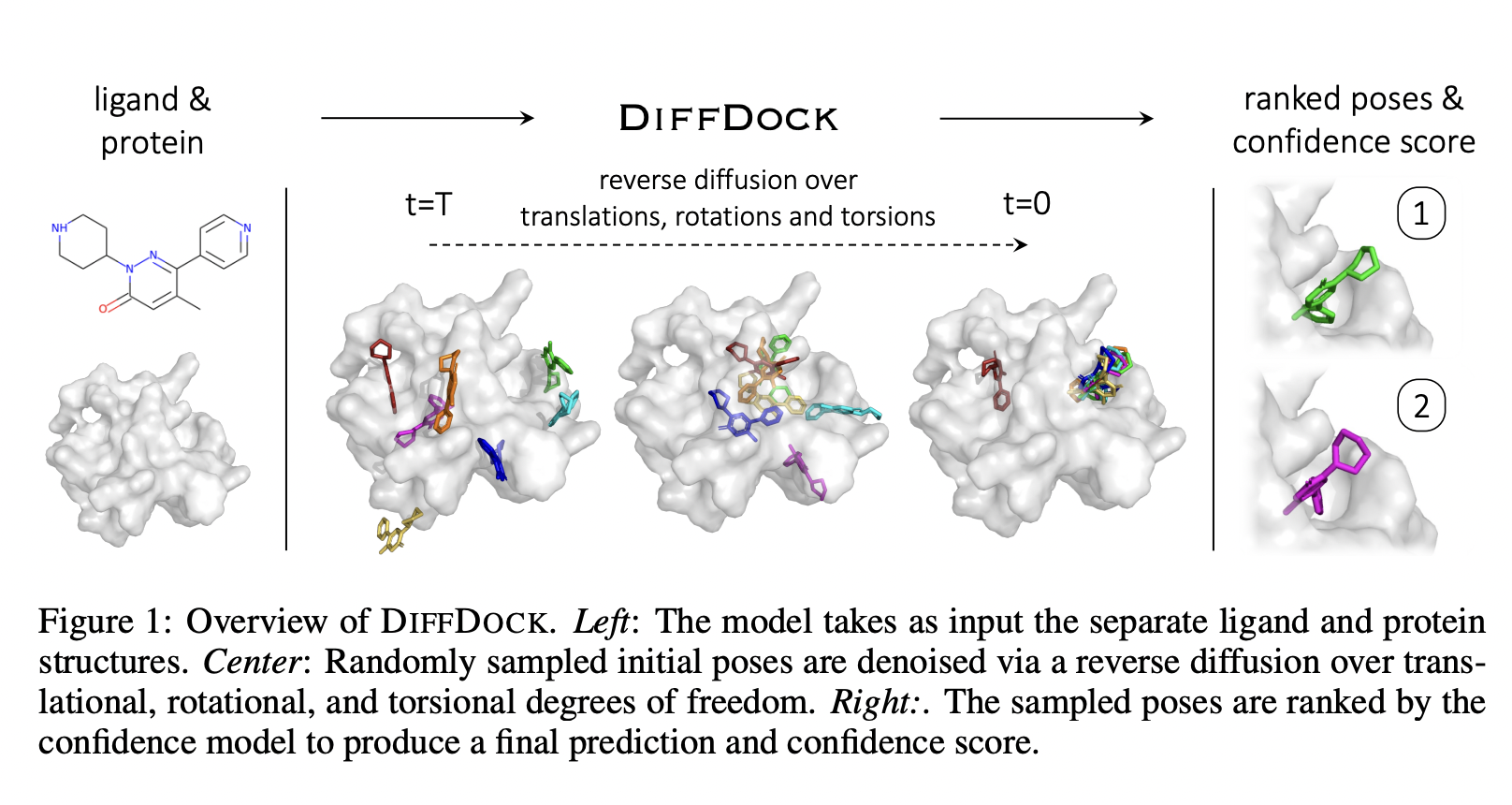
Molecular docking is essential in computational drug design since it allows one to predict the location, orientation, and conformation of a ligand when attached to a target protein and, thus, the potential action of the ligand. In conventional docking methods, an estimation of the accuracy of a proposed structure or posture is made using a scoring function, and an optimization technique is used to find the global maximum of the scoring function. However, these approaches are typically excessively sluggish and imprecise, especially for high-throughput operations, due to the search space’s size and the scoring functions’ complexity.
Docking has been viewed as a regression problem in recent research, leading to the development deep-learning models that can predict the binding pose in a single iteration. However, despite their faster speed compared to search-based approaches, these methods have not yet proven to be more accurate. Researchers claim that standard accuracy measurements more closely approximate the likelihood of the data under the predictive model than a regression loss. This indicates that the regression-based paradigm does not exactly align with the goals of molecular docking.
Based on these, researchers from the CSAIL team at MIT investigate molecular docking as a generative modeling issue, wherein they are given the structures of a ligand and a target protein and asked to learn a distribution over possible poses for the ligand.
A diffusion process over the degrees of freedom involved in docking includes the position of the ligand relative to the protein (finding the binding pocket), the orientation of the ligand within the pocket, and the torsion angles characterizing its shape. This led to the creation of DIFFDOCK, a DGM for molecular docking that diffuses throughout the space of ligand positions. DIFFDOCK takes a random sample from the learned (reverse) diffusion process, which converts a noisy, uninformed prior distribution over ligand positions into a more accurate model distribution over a series of iterative steps.

The team defines the degree of docking freedom (M) as the space of postures reachable via a set of permitted ligand pose transformations. Using this notion, the elements of M are translated into the product space of the groups responsible for those transformations, where a DGM can be easily built and trained. A confidence model is trained to provide confidence estimates for the poses taken from the DGM and to select the most likely sample, as many docking model applications only need a specific number of predictions and a confidence score over these. This two-step procedure can be seen as a compromise between the extremes of brute-force search and one-shot prediction, as it’s still possible to explore and compare several different positions without dealing with the complications of a high-dimensional search.
The results show that DIFFDOCK empirically achieves nearly double the performance of the previous state-of-the-art deep learning model (20%) on the classic blind docking benchmark PDBBind. DIFFDOCK is 3–12 times faster on GPU than even the best state-of-the-art search-based approaches (23%). In addition, it delivers a reliable confidence score of its forecasts, with an RMSD2A of 83% for the third of previously unseen complexes in which it has the highest faith.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'DIFFDOCK: DIFFUSION STEPS, TWISTS, AND TURNS FOR MOLECULAR DOCKING'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Tanushree Shenwai is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Bhubaneswar. She is a Data Science enthusiast and has a keen interest in the scope of application of artificial intelligence in various fields. She is passionate about exploring the new advancements in technologies and their real-life application.
Credit: Source link
Comments are closed.