MIT Researchers Propose Patch-Based Inference to Reduce the Memory Usage for Tiny Deep Learning

Machine learning provides researchers with excellent tools for identifying and predicting patterns and behavior. These tools are also capable of learning, optimizing, and performing tasks. These applications’ algorithms and architectures are growing to become powerful and efficient. However, they often demand a lot of memory, processing, and data to train and form inferences.
Simultaneously, researchers are striving to shrink the size and complexity of the devices on which these algorithms may run, all the way down to a microcontroller unit (MCU) present in billions of internet-of-things (IoT) machines. MCU is a memory-limited minicomputer that runs simple commands in a tiny integrated circuit. These are low-cost edge devices with low power, compute, and bandwidth requirements. Furthermore, they provide numerous chances to include AI technology to boost their value, increase privacy, and democratize their use. TinyML is a field that encompasses all of this.
The restricted memory size of microcontroller units (MCUs) makes little deep learning difficult. The unbalanced memory distribution in convolutional neural network (CNN) designs is blamed for the memory bottleneck. CNNs are biologically inspired models that analyze and detect visual elements within the footage, such as a person walking through a video frame.
A group of MIT researchers working in the MIT-IBM Watson AI Lab’s TinyML field have devised a method to reduce the amount of memory required even more while increasing picture recognition accuracy in live videos. To improve TinyML’s efficiency, researchers looked into how memory is used on microcontrollers running different convolutional neural networks (CNNs).
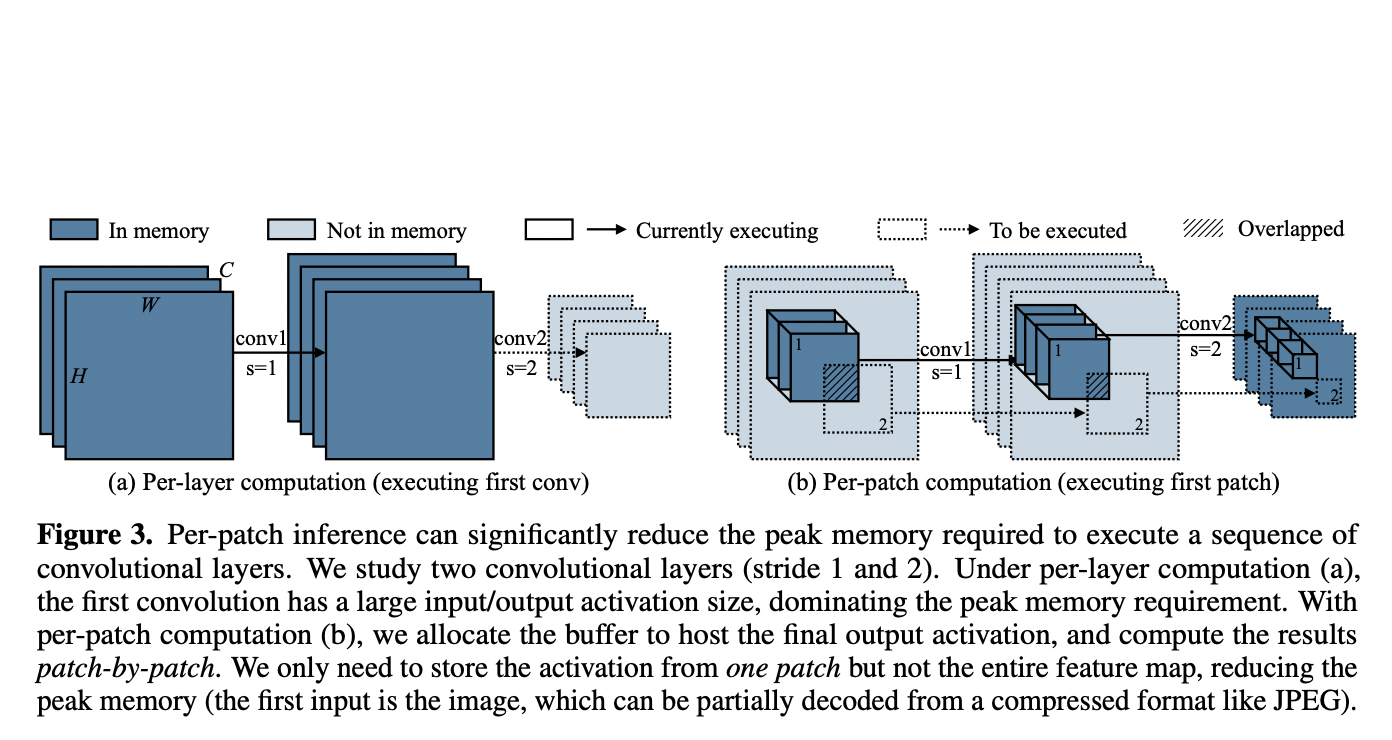
Small MCU memory and digital storage, on the other hand, limit AI applications. Therefore efficiency is a significant hurdle. The team wanted to make the most of it, so they studied the MCU memory utilization of CNN designs. It is an idea that has previously been disregarded. According to the data, the first five convolutional blocks out of around 17 had the highest memory utilization. Each block has several interconnected convolutional layers that aid in detecting certain features in an input picture or video, resulting in a feature map as an output.
The researchers devised a patch-by-patch inference scheduling method that only operates on a tiny spatial section of the feature map. The peak memory is significantly reduced using this strategy.
However, a simple approach results in overlapping patches and additional computation time. To alleviate this challenge, the researchers propose receptive field redistribution, which would move the receptive field and FLOPs to a later stage and reduce computation overhead.
Another issue that arises is the difficulty of manually redistributing the receptive field. Consequently, a need appears to automate the process with neural architecture search to concurrently optimize neural architecture and inference scheduling, which led to MCUNetV2. MCUNetV2 beat prior machine learning methods operating on microcontrollers in terms of detection accuracy, allowing for new vision applications not before available. Furthermore, the study team anticipates its use in various disciplines, including healthcare monitoring and joint mobility and sports.
TinyML data is processed on the local device rather than sent to the cloud for processing. The robustness is excellent since the computation is speedy and has low latency. TinyML approaches can enable AI to operate off-grid, reducing carbon emissions and making AI greener, better, faster, and more accessible.
The long-term goal is to bring the research’s findings to large-scale, real-world applications. As a result, it paves the way for a completely new approach to micro AI and mobile vision.
Paper: https://arxiv.org/abs/2110.15352
Slides: https://mcunet.mit.edu/
Reference: https://news.mit.edu/2021/tiny-machine-learning-design-alleviates-bottleneck-memory-usage-iot-devices-1208
Suggested
Credit: Source link
Comments are closed.