MLOps Spanning Whole Machine Learning Life Cycle: Paper Summary
This AI paper provides an extensive examination of the field of MLOps. MLOps is an emerging discipline that focuses on automating the entire machine learning lifecycle. The survey covers a broad range of topics, including MLOps pipelines, challenges, and best practices. It delves into the various phases of the machine learning process, starting from model requirements analysis, data collection, data preparation, feature engineering, model training, evaluation, system deployment, and model monitoring. Additionally, it discusses important considerations such as business value, quality, human value, and ethics throughout the entire lifecycle.
The paper aims to present a comprehensive survey of MLOps, emphasizing its significance in automating the machine learning life cycle. The survey covers multiple topics, including MLOps pipelines, challenges, best practices, and various stages of the machine learning process.
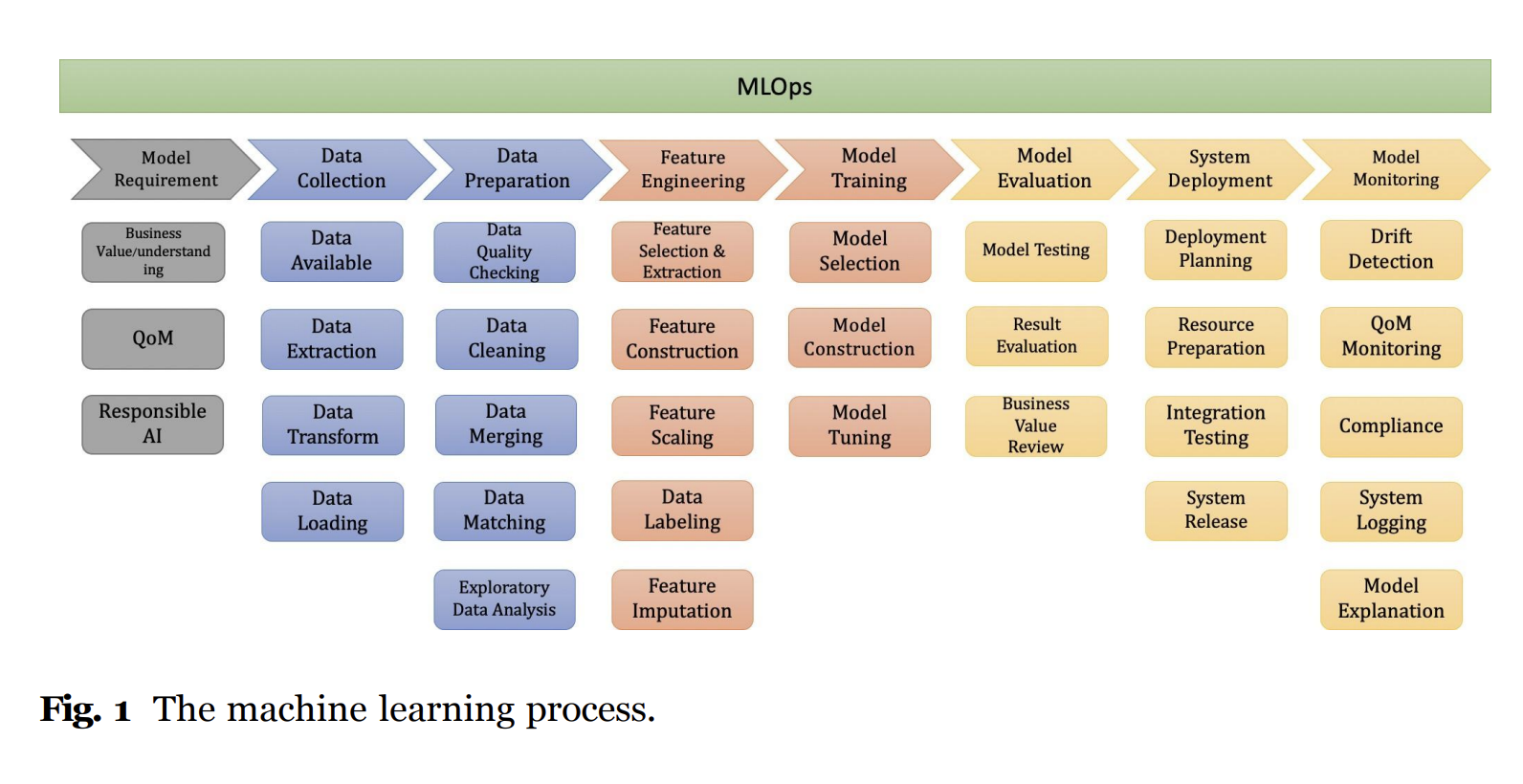
This paper provides a big picture summarized in the figure below:

Model Requirements Analysis
To kickstart a machine learning project, stakeholders must analyze and identify model requirements. This section outlines the four fundamental dimensions for consideration: business value, model quality, human value (privacy, fairness, security, and accountability), and ethics. Stakeholders are encouraged to define objectives, assess tools for identifying values and problems, prioritize requirements, involve relevant stakeholders, and determine the necessary functions.
Data Collection and Preparation
The data preparation phase plays a vital role in ensuring high-quality data for machine learning tasks. This section addresses data collection, data discovery, data augmentation, data generation, and the ETL (Extract, Transform, Load) process. It emphasizes the importance of data quality checking, data cleaning, data merging, data matching, and conducting Exploratory Data Analysis (EDA) to gain insights into the dataset.
Feature Engineering
Feature engineering is crucial for improving predictive modeling performance. This section highlights techniques such as feature selection and extraction, feature construction, feature scaling, data labeling, and feature imputation. Specific algorithms and methods associated with each technique are mentioned, including Principle Component Analysis (PCA), Independent Component Analysis (ICA), and Standardization and Normalization.
Model Training
The model training phase covers different types of machine learning models, including supervised, unsupervised, semi-supervised, and reinforcement learning. The section discusses model selection, which involves choosing the appropriate model for a specific problem. It also explores methods for model selection, such as cross-validation, bootstrapping, and random split. Hyperparameter tuning, the process of optimizing a model’s parameters, is also addressed.
Model Evaluation
Model evaluation focuses on assessing a model’s performance using various metrics. This section presents common evaluation metrics such as accuracy, precision, recall, F-score, and area under the ROC curve (AUC). It emphasizes the importance of considering both the model’s performance and its business value.
System Deployment
System deployment involves selecting an appropriate ML model operating platform, integrating the system, conducting system integration testing, and releasing the system to end users. Deployment strategies, including canary deployment and blue-green deployment, are explained. Challenges associated with deploying ML systems are also discussed, along with tips for a smooth deployment process.
Model Monitoring
The paper emphasizes the significance of model monitoring in ML systems. It highlights the lack of knowledge and experience among developers in ML model monitoring and maintenance. The section explores various aspects of model monitoring, including drift detection, quality of model monitoring, compliance, system logging, and model explanation (XAI). It provides insights into monitoring changes in data distribution, ensuring model performance, complying with industry-specific standards and regulations, system logging for ML pipelines, and achieving model transparency.
Conclusion
The paper concludes by discussing the future of MLOps and the challenges that need to be addressed to enhance scalability and reliability. It emphasizes the importance of continuous monitoring and maintenance of ML models for long-term success.
In summary, this comprehensive survey covers the entire machine learning life cycle within the domain of MLOps. It provides valuable insights into MLOps pipelines, challenges, best practices, model requirements analysis, data preparation, feature engineering, model training, evaluation, system deployment, and model monitoring. By examining these topics in detail, this survey aims to assist researchers and practitioners in gaining a holistic understanding of MLOps and its practical implications.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Ivo Medeiros received his B.Sc. in 2008 from UFPA, M.Sc. in 2011 from ITA and Ph.D. in 2019 from INPE, at Brazil. Ivo studies applied AI since 2005; he worked for Vale (mining), Embraer (aerospace), Loggi (logistics), Konduto (fraud detection); and currently for Americanas (retail). Besides that, he worked as independent consultant in challenges ranging from essay scoring to behavioural analytics.
edge with data: Actionable market intelligence for global brands, retailers, analysts, and investors. (Sponsored)
Credit: Source link
Comments are closed.