Model Collapse: The Hidden Threat to LLMs and How to Keep AI Rea
With the craze of LLMs, such as widely popular GPT engines, every company, big or small, is in the race to either develop a model better than the existing ones or use the current models in an innovatively packaged way that solves a problem.
Now while finding the use cases and building a product around it is fine, what is concerning is how we will train a model, which is better than existing models, what its impact will be, and what kind of technique we will use. By highlighting all these questions and raising a concerning issue, this paper discusses everything we need to know.
The current GPT engines such as chatGPT or any other large language model, be it general or a specific niche-based system, have been trained data on the internet publically and widely accessible.
So this gives us an idea of where the data is coming from. The source is common folks who read, write, tweet, comment and review information.
There are two widely accepted ways to increase how efficiently a model will work and how magical a non-tech person will find it. One is to increase the data you are training your model onto. And second one is to increase the number of parameters it will consider. Consider parameters as unique data points or characteristics of the topic the model is learning about.
So far, the models have been working with data in any form, audio, video, image, or text, which humans developed. If treated as a huge corpus, this corpus has data that was authentic in terms of semantics, constituted of variety and uncommon occurrence, which we often refer to as variety in data, was there. All the vivid flavors were intact. Hence these models could develop a realistic data distribution and train on predicting not only the most probable (Common) class but also less occurring classes or tokens.
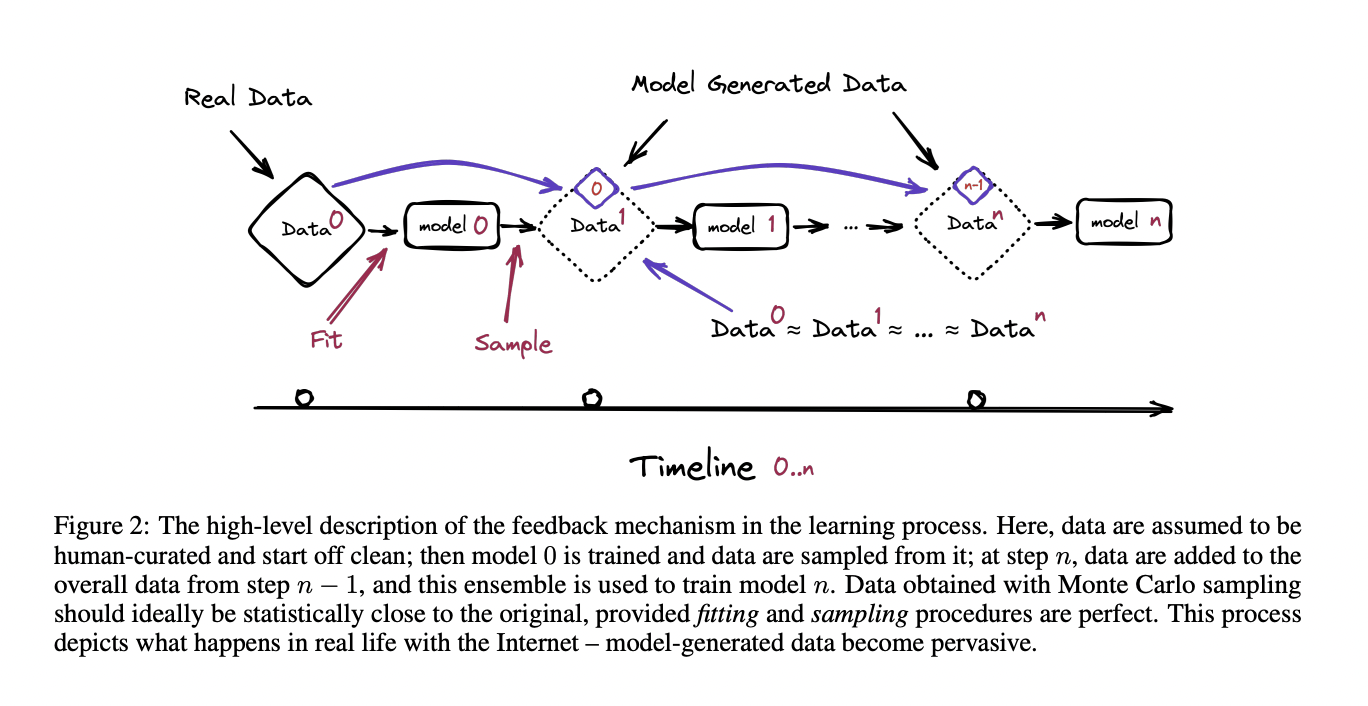
Now, this variety is under threat with the infusion of machine-generated data, for example, an article written by an LLM or an image generated by an AI. And this problem is bigger than it looks at first glance as it compounds over time.
Now according to the researchers of this paper, this issue is quite prevalent and hazardously impactful in models that follow a continual learning process. Unlike traditional machine learning, which seeks to learn from a static data distribution, continual learning attempts to learn from a dynamic one, where data are supplied sequentially. Approaches like this tend to be task-based, providing data with delineated task boundaries, e.g., classifying dogs from cats and recognizing handwritten digits. This task is more similar to task-free continual learning, where data distributions gradually change without the notion of separate tasks.
Model Collapse is a degenerative process affecting generations of learned generative models, where generated data pollutes the training set of the next generation of models; being trained on polluted data, they misperceive reality. All of this leads to Model Collapse, which is a direct cause of data poisoning. While data poisoning, in broader terms, means anything that can lead to the creation of data that doesn’t accurately depict reality. The researchers have used various manageable models that mimic the mathematical models of LLMs to showcase how real this problem is and how it grows over time. Almost every LLM suffers from that, as shown in the results.
Now that we know what the issue is and what is causing it, the obvious question is how do we solve it? The answer is quite simple and is suggested by the paper as well.
- Maintain the authenticity of the content. Keep it real
- Add more collaborators to review the training data and ensure realistic data distribution.
- Regulate the usage of machine-generated data as training data.
With all these, this paper highlights how concerning this insignificant-looking problem can be because it is very costly to train LLMs from scratch, and most organizations use pretrained models as a starting point to some extent.
Now even the critical services such as Life science use cases, supply chain management, and even the entire content industry are rapidly moving onto LLMs for their regular tasks and suggestion; it would be interesting to see how LLMs developers will keep it realistic and improve the model continuously.
Check Out The Paper. Don’t forget to join our 23k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club

Anant is a Computer science engineer currently working as a data scientist with experience in Finance and AI products as a service. He is keen to build AI-powered solutions that create better data points and solve daily life problems in an impactful and efficient way.
Credit: Source link
Comments are closed.