Motion TRansformer (MTR): A Novel Framework For Motion Prediction in Autonomous Driving Scenarios
Modern autonomous driving systems rely heavily on motion predictions. It has gotten more attention since understanding driving environments and making safe judgments is critical for robotic cars. Motion forecasting necessitates anticipating future traffic participant actions by combining observed agent states and road maps, which is difficult owing to the agent’s intrinsic multimodal behaviors and diverse scene surroundings. Existing approaches mostly fall into two categories to cover all possible future actions of the agent: goal-based methods and direct-regression methods.
Instead of employing objective candidates, direct-regression algorithms anticipate a set of trajectories based on the encoded agent characteristic, adaptively covering the agent’s future behavior. The goal-based approaches use dense goal candidates to protect all of the agent’s possible destinations, estimating the likelihood of each candidate being a true destination and then completing the whole trajectory for each picked candidate. Although these target candidates lessen the load of model optimization by minimizing trajectory uncertainty, their density substantially influences their performance: fewer candidates reduce performance, while more candidates significantly increase computation and memory cost.
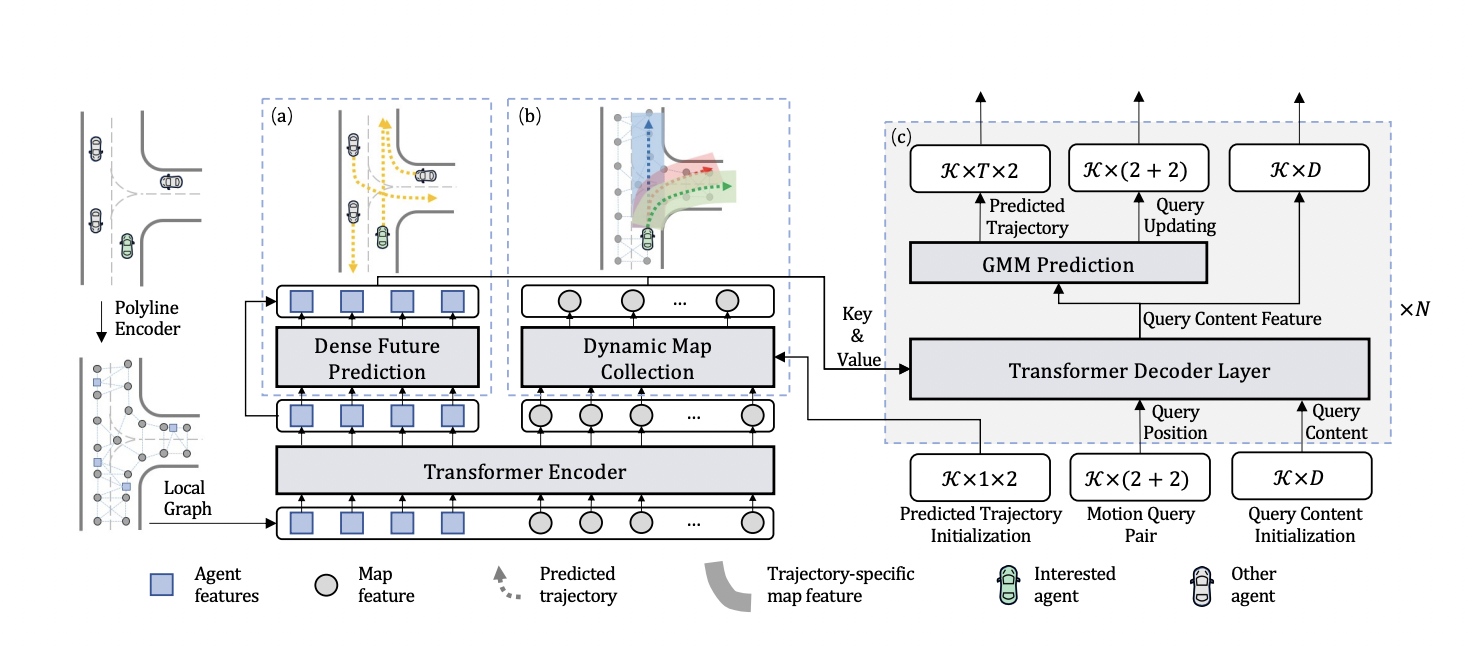
Despite their versatility in predicting a wide range of agent behaviors, they often converge slowly since different motion modes must be regressed from the same agent feature without using spatial priors. They also tend to forecast the most common methods of training data since these frequent modes dominate agent feature optimization. They provide a unified framework, Motion TRansformer (MTR), in this research that combines the best of both types of approaches. They use a small collection of innovative motion question pairs in our proposed MTR to describe motion prediction as the combined optimization of two tasks: The first global intention localization goal tries to identify an agent’s intention to maximize efficiency. In contrast, the second local movement refinement job aims to revise each intention’s anticipated trajectory to optimize accuracy adaptively. Their method stabilizes the training process without relying on dense goal candidates and allows for flexible and adaptable prediction by allowing for local refinement for each motion mode. Each motion query pair comprises two parts: a static intention query and a dynamic searching query.
They present static intention queries for global intention localization, where they formulate them based on a small number of geographically dispersed intention locations. Each static intention query is the learnable positional embedding of an intention point for generating the trajectory of a specific motion mode. It not only stabilizes the training process by explicitly using different queries for different ways but also eliminates reliance on dense goal candidates by requiring each query to take charge of a large region. The dynamic searching queries are used for local movement refinement; they are likewise initialized as learnable embeddings of the intention points, but they are responsible for retrieving fine-grained regional characteristics surrounding each intention point.

The dynamic searching queries are dynamically changed according to the expected trajectories for this purpose, which can adaptively obtain current trajectory information from a deformable local region for iterative motion refining. These two questions are complementary and have successfully predicted multimodal future motion. In addition, they offer a dense future prediction module. Existing studies mainly focus on simulating agent interaction over previous trajectories while disregarding interaction over future courses. To compensate for this information, they use a simple auxiliary regression head to densely forecast each agent’s future trajectory and velocity, which are stored as different future context characteristics to assist our interested agent’s future motion prediction. Experiments demonstrate that this essential auxiliary task works effectively and significantly enhances multimodal motion prediction ability.
They provide three contributions:
- They present a novel motion decoder network with a unique notion of motion query pair, which models motion prediction as a simultaneous optimization of global intention localization and local movement refining. It stabilizes the training with mode-specific motion query pairs and allows for adaptive motion refinement by repeatedly accumulating fine-grained trajectory information.
- They provide an auxiliary dense future prediction job to allow our interested agents to engage with other agents in the future. It makes our approach to forecasting more scene-compliant trajectories for interacting agents easier.
- These methodologies offer the MTR framework for multimodal motion prediction, which investigates the transformer encoder-decoder structure.
Their technique outperforms prior best ensemble-free approaches on both the marginal and joint motion prediction benchmarks of the Waymo Open Motion Dataset (WOMD), with +8.48% mAP gains for marginal motion prediction and +7.98% mAP increases for standard motion prediction. As of May 19, 2022, our technique is ranked first on the WOMD marginal and joint motion prediction leaderboards. The code implementation will be soon released on their GitHub page.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Motion Transformer with Global Intention Localization and Local Movement Refinement'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.