MusicMagus: Harnessing Diffusion Models for Zero-Shot Text-to-Music Editing
Music generation has long been a fascinating domain, blending creativity with technology to produce compositions that resonate with human emotions. The process involves generating music that aligns with specific themes or emotions conveyed through textual descriptions. While developing music from text has seen remarkable progress, a significant challenge remains: editing the generated music to refine or alter specific elements without starting from scratch. This task involves intricate adjustments to the music’s attributes, such as changing an instrument’s sound or the piece’s overall mood, without affecting its core structure.
Models are primarily divided into autoregressive (AR) and diffusion-based categories. AR models produce longer, higher-quality audio at the cost of longer inference times, and diffusion models excel in parallel decoding despite challenges in generating extended sequences. The innovative MagNet model merges AR and diffusion advantages, optimizing quality and efficiency. While models like InstructME and M2UGen demonstrate inter-stem and intra-stem editing capabilities, Loop Copilot facilitates compositional editing without altering the original models’ architecture or interface.
Researchers from QMU London, Sony AI, and MBZUAI have introduced a novel approach named MusicMagus. This approach offers a sophisticated yet user-friendly solution for editing music generated from text descriptions. By leveraging advanced diffusion models, MusicMagus enables precise modifications to specific musical attributes while maintaining the integrity of the original composition.
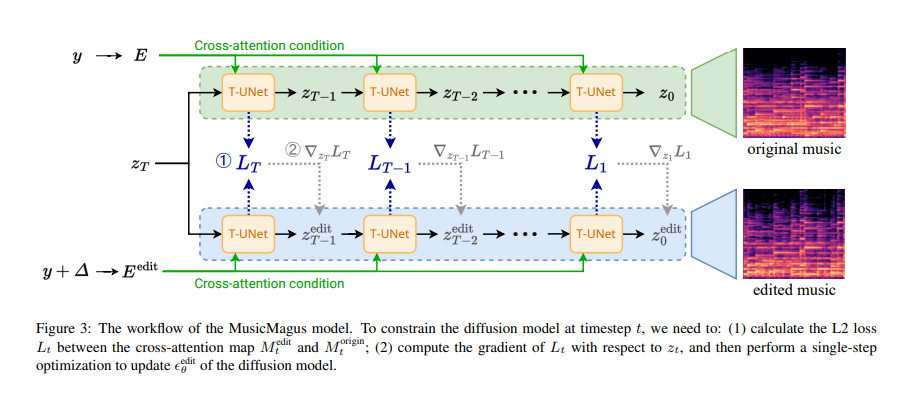
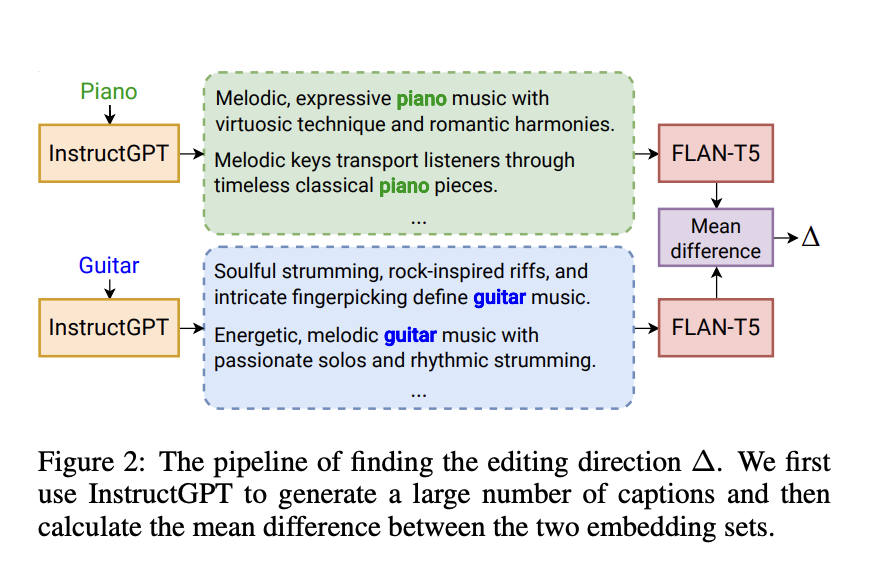
MusicMagus showcases its unparalleled ability to edit and refine music through sophisticated methodologies and innovative use of datasets. The system’s backbone is built upon the prowess of the AudioLDM 2 model, which utilizes a variational autoencoder (VAE) framework for compressing music audio spectrograms into a latent space. This space is then manipulated to generate or edit music based on textual descriptions, bridging the gap between textual input and musical output. The editing mechanism of MusicMagus leverages the latent capacities of pre-trained diffusion-based models, a novel approach that significantly enhances its editing accuracy and flexibility.
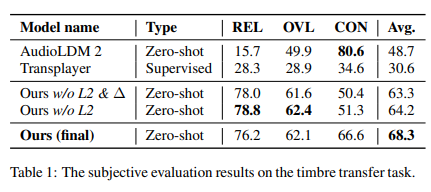
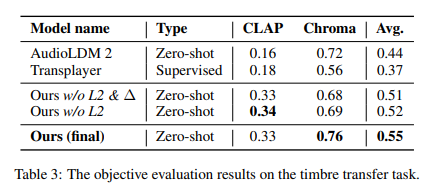
Researchers conducted extensive experiments to validate MusicMagus’s effectiveness, which involved critical tasks such as timbre and style transfer, comparing its performance against established baselines like AudioLDM 2, Transplayer, and MusicGen. These comparative analyses are grounded in utilizing metrics such as CLAP Similarity and Chromagram Similarity for objective evaluations and Overall Quality (OVL), Relevance (REL), and Structural Consistency (CON) for subjective assessments. Results reveal MusicMagus outperforming baselines with a notable CLAP Similarity score increase of up to 0.33 and Chromagram Similarity of 0.77, indicating a significant advancement in maintaining music’s semantic integrity and structural consistency. The datasets employed in these experiments, including POP909 and MAESTRO for the timbre transfer task, have played a crucial role in demonstrating MusicMagus’s superior capabilities in altering musical semantics while preserving the original composition’s essence.
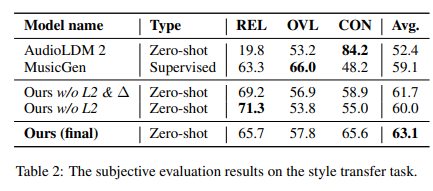
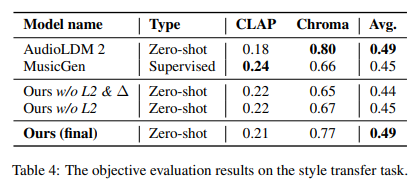
In conclusion, MusicMagus introduces a pioneering text-to-music editing framework adept at manipulating specific musical aspects while preserving the integrity of the composition. Although it faces challenges with multi-instrument music generation, editability versus fidelity trade-offs, and maintaining structure during substantial changes, it marks a significant advancement in music editing technology. Despite its limitations in handling long sequences and being confined to a 16kHz sampling rate, MusicMagus significantly advances the state-of-the-art style and timbre transfer, showcasing its innovative approach to music editing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.