New Amazon AI Study Introduces Pyramid-BERT To Reduce Complexity via Successive Core-set based Token Selection
This Article is written as a summay by Marktechpost Staff based on the paper 'Pyramid-BERT: Reducing complexity via successive core-set based token selection'. All Credit For This Research Goes To The Researchers of This Project. Check out the paper and post. Please Don't Forget To Join Our ML Subreddit
In recent years, transformers have become a significant component in many machine learning models, achieving state-of-the-art results on various natural language processing tasks such as machine translation, question answering, text classification, semantic role labeling, and so on. Pre-training, fine-tuning, or inferring such models, on the other hand, necessitates a significant amount of computer resources. Transformers’ complexity stems mostly from a pipeline of encoders, each having a multi-head self-attention layer. The self-attention process is a major bottleneck for long-sequence data as they grow quadratically with the length of the input sequence.
Many studies have attempted to address this problem by compressing and speeding Transformers to lower the expense of pre-training and fine-tuning.
A recent Amazon study proposes a novel Select approach that tries to gradually reduce sequence length in the encoder pipeline. As the researchers mention in their paper “Pyramid-BERT: Reducing Complexity via Successive Core-set based Token Selection,” the sequence-level NLP tasks such as text classification and ranking have influenced this research.
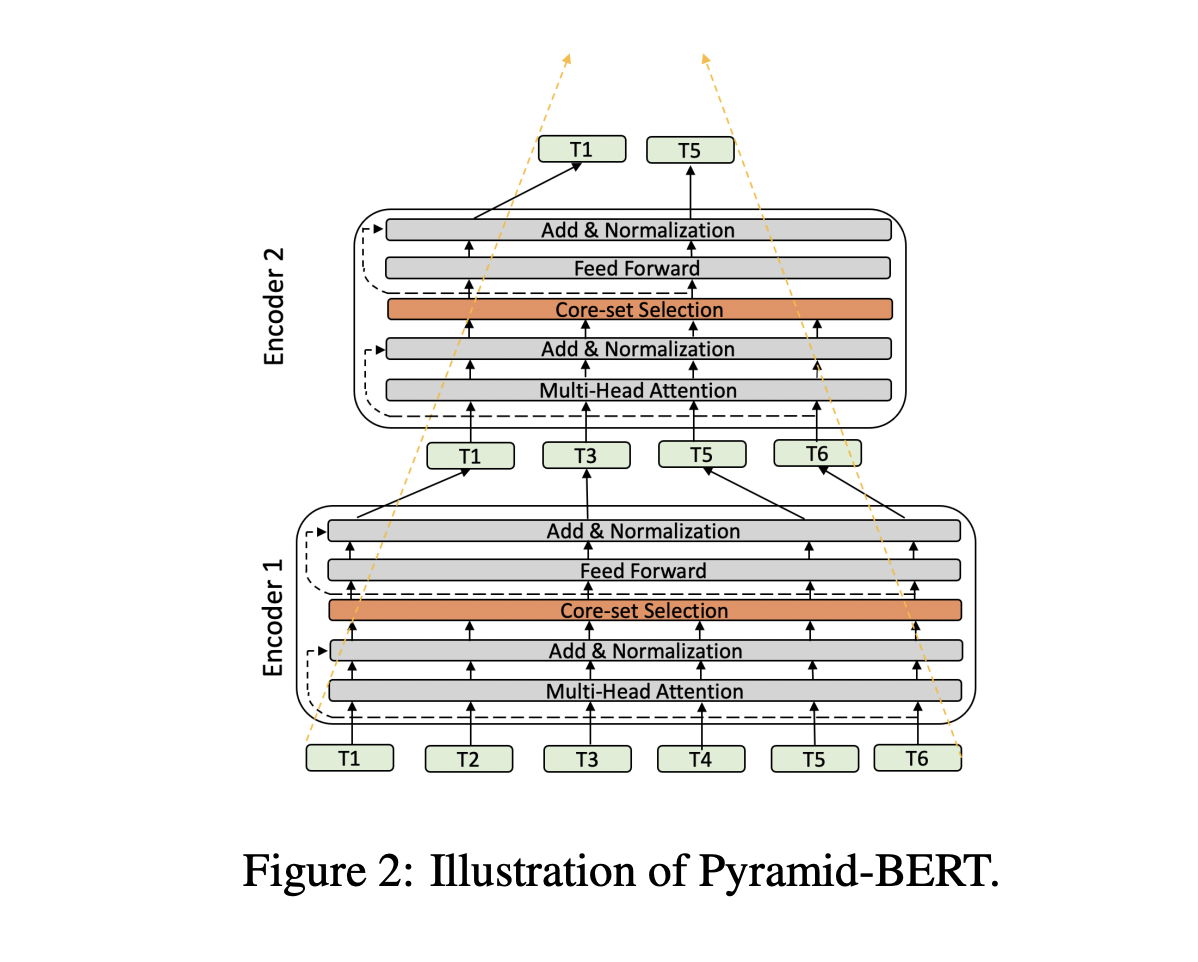
The existing SOTA Transformer models predict using a single embedding from the top encoder layer, such as the CLS token. Keeping the full-length sequence until the last encoder adds additional complexity in this situation.
Their work is divided into two categories: Select: a mechanism for reducing the length of a sequence, either through pruning or pooling. Train-Select is a mechanism-specific training or fine-tuning approach.
The token representations in the top layers are becoming increasingly redundant. According to the researchers, a compact core-set, made up of a subset of the tokens, can naturally represent a collection of tokens with high redundancy. Their approach for Select is based on the concept of core sets, which was inspired by this.
Previous research has provided heuristic strategies for reducing sequence length, but they are time-consuming to learn. In contrast, their approach becomes more successful as the representation’s redundancy grows.

Some of the Train-Select approaches require a comprehensive pre-training approach. Because of the great quality of their Select solution, they may simply skip the additional training process. In contrast, others require fine-tuning on the full uncompressed model, which means keeping all tokens till the final encoder layer. The impact of this simplification is significant, which improves the speed and memory efficiency of not only the inference but also the training process, allowing normal hardware (and training scripts) to be used in the training method even for very long sequences.
The researchers compared Pyramid-BERT to many state-of-the-art strategies for making BERT models more efficient. Their findings show that their method can speed up inference by 3- to 3.5-fold while sacrificing only 1.5 percent accuracy, whereas the best available method loses 2.5 percent accuracy at the same speeds.
Furthermore, they claim that when their method is applied to Performers––variations on BERT models specifically developed for long texts––the models’ memory footprint is reduced by 70% while accuracy is increased. The best existing technique suffers a 4% accuracy dropoff at that compression rate.
Overall, their approach provides a theoretically justified technique for reducing sequence length. Their results demonstrate a speedup and memory reduction for both transformer training and inference. At the same time, the model suffers much less in terms of predictive performance when compared to other existing techniques.
Credit: Source link
Comments are closed.