New Machine Learning Research from MIT Proposes Compositional Foundation Models for Hierarchical Planning (HiP): Integrating Language, Vision, and Action for Long-Horizon Tasks Solutions
Think about the challenge of preparing a cup of tea in a strange home. An efficient strategy for completing this task is to reason hierarchically at several levels, including an abstract level (for example, the high-level steps required to heat the tea), a concrete geometric level (for example, how they should physically move to and through the kitchen), and a control level (for example, how they should move their joints to lift a cup). An abstract plan to search cabinets for tea kettles must also be physically conceivable at the geometric level and executable given the actions they are capable of. This is why it is crucial that reasoning at each level is consistent with one another. In this study, they investigate the development of unique long-horizon task-solving bots capable of employing hierarchical reasoning.
Large “foundation models” have taken the lead in tackling problems in mathematical reasoning, computer vision, and natural language processing. Creating a “foundation model” that can address unique and long-horizon decision-making problems is an issue that has attracted much attention in light of this paradigm. In several earlier studies, matched visual, linguistic, and action data were gathered, and a single neural network was trained to handle long-horizon tasks. However, it is expensive and challenging to scale up the coupled visual, linguistic, and action data collection. Another line of earlier research uses task-specific robot demonstrations to refine large language models (LLM) on visual and linguistic inputs. This is a concern since, in contrast to the wealth of material available on the Internet, examples of coupled vision and language robots are difficult to find and expensive to compile.
Furthermore, because the model weights are not open-sourced, it is currently difficult to finetune high-performing language models like GPT3.5/4 and PaLM. The foundation model’s major feature is that it requires far less data to solve a new problem or adapt to a new environment than if it had to learn the job or domain from the start. In this work, they seek a scalable substitute for the time-consuming and expensive process of collecting paired data across three modalities to build a foundation model for long-term planning. Can they do this while still being reasonably effective at solving new planning tasks?
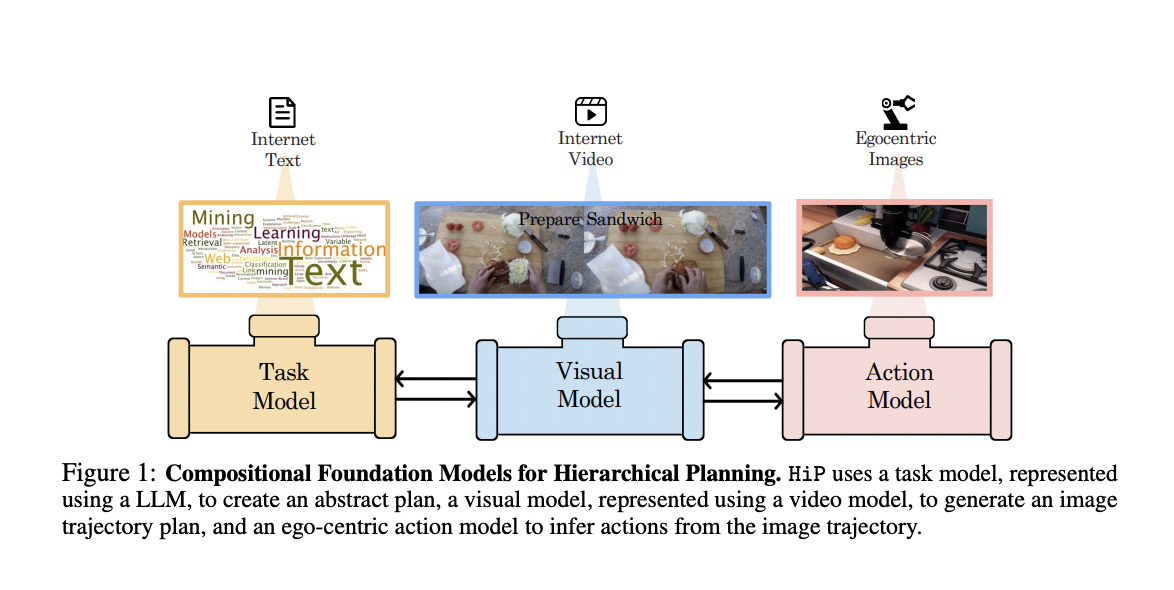
Researchers from Improbable AI Lab, MIT-IBM Watson AI Lab and Massachusetts Institute Technology suggest Compositional Foundation Models for Hierarchical Planning (HiP), a foundation model made up of many expert models independently trained on language, vision, and action data. The amount of data needed to build the foundation models is significantly decreased since these models are introduced separately (Figure 1). HiP employs a big language model to discover a series of subtasks (i.e., planning) from an abstract language instruction specifying the intended task. HiP then develops a more intricate plan in the form of an observation-only trajectory using a large video diffusion model to gather geometric and physical information about the environment. Finally, HiP employs a sizable inverse model that has been previously trained and converts a series of egocentric pictures into actions.
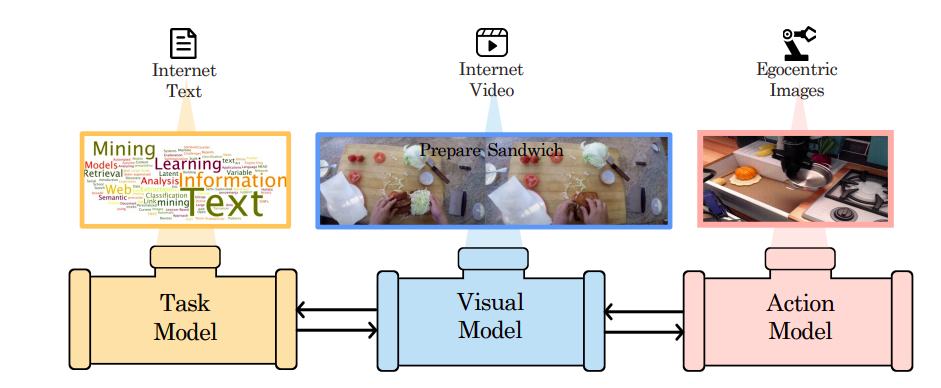
Figure 1: Compositional Foundation Models for Hierarchical Planning are shown above. HiP employs three models: a task model (represented by an LLM) to produce an abstract plan, a visual model (represented by a video model) to produce an image trajectory plan; and an ego-centric action model to deduce actions from the image trajectory.
Without needing to gather costly paired decision-making data across modalities, the compositional design choice enables various models to reason at different levels of the hierarchy and jointly make expert conclusions. Three separately trained models can generate conflicting results, which might fail in the whole planning process. For instance, choosing the output with the highest likelihood at each stage is a naive method for building models. A step in a plan, such as looking for a tea kettle in a cabinet, may have a high chance under one model but a zero likelihood under another, such as if the house does not contain a cabinet. Instead, it’s crucial to sample a strategy that jointly maximizes likelihood across all professional models.
They provide an iterative refinement technique to assure consistency, utilizing feedback from the downstream models to develop consistent plans across their diverse models. The output distribution of the language model’s generative process incorporates intermediate feedback from a likelihood estimator conditioned on a representation of the current state at each stage. Similarly, intermediate input from the action model improves video creation at each stage of the development process. This iterative refinement process fosters consensus across the many models to create hierarchically consistent plans that are both responsive to the objective and executable given the existing state and agent. Their suggested iterative refinement method does not need extensive model finetuning, making training computationally efficient.
Additionally, they don’t need to know the model’s weights, and their strategy applies to all models that provide input and output API access. In conclusion, they provide a foundation model for hierarchical planning that uses a composition of foundation models independently acquired on various Internet and egocentric robotics data modalities to create long-horizon plans. On three long-horizon tabletop manipulation situations, they show promising outcomes.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.