New MIT Research Suggests That Training An AI Model With Mathematically “Diverse” Teammates Can Improve Its Ability To Collaborate With Other AI It Has Never Worked With Before
The prevalence of superhuman artificial intelligence (AI) in competitive games such as chess, Atari, StarCraft II, DotA, and poker is growing.
Recent advances in deep reinforcement learning contribute significantly to the success of competitive AI. In contrast, cooperative AI, in which autonomous agents must interact with humans or separately-trained agents to achieve a common goal, is comparatively understudied within reinforcement learning.
As artificial intelligence improves at previously human-exclusive jobs, such as driving automobiles, many consider teaming intelligence the next frontier. In this imagined future, humans and AI are true partners in high-stakes occupations, such as conducting sophisticated surgery or guarding against missiles.
Recent research indicates that variety is a crucial factor in making AI a more effective team member.
Numerous researchers use Hanabi as a testing environment for cooperative AI development. Hanabi requires players to work cooperatively to arrange cards in sequence, but they can only view their teammates’ cards and provide little hints as to which cards they hold.
Researchers evaluated one of the most effective Hanabi AI models with humans in a prior experiment. They were astonished that humans disliked interacting with this AI model, describing it as a confusing and unreliable teammate. The conclusion was that Researchers are missing something about human preference, and they are not yet proficient at creating models that may function in the actual world.
For AI to be a good collaborator, it may be necessary for it to care not only about maximizing reward when cooperating with other AI agents but also about something more intrinsic: understanding and responding to the strengths and preferences of others. In other words, it must adapt and learn from diversity.
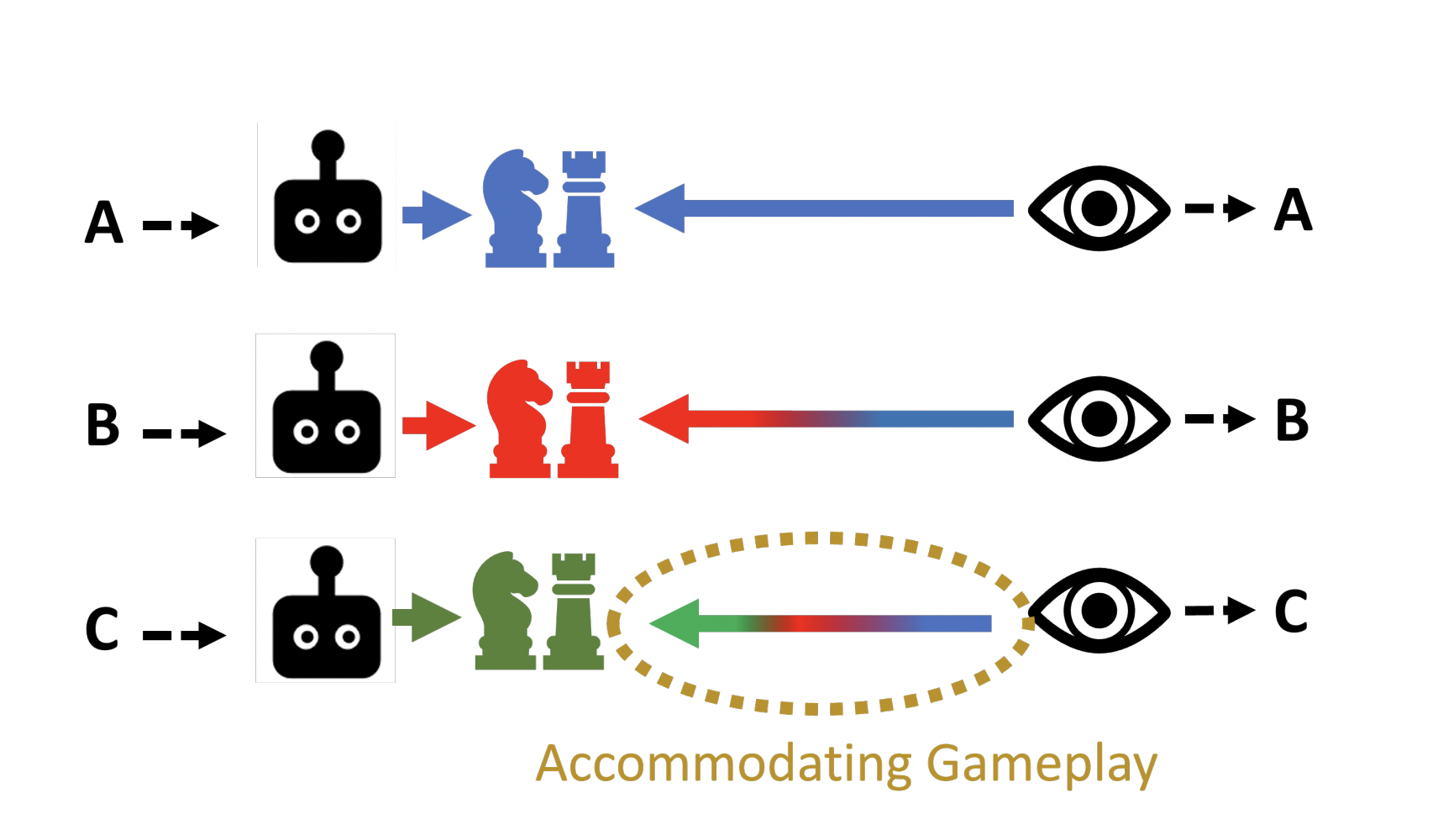
The researchers developed Any-Play. Any-Play enhances the process of training an AI Hanabi agent by adding an objective and maximizing the game score: the AI must accurately identify the play style of its training partner.
Although this way of creating diversity is not novel in the realm of AI, the team expanded the notion to collaborative games by employing these various behaviors as diverse gameplay styles.
The team added the Any-Play training procedure to the Hanabi model (which had been tested on people in a previous experiment) developed previously. To determine if the strategy increased collaboration, the researchers paired the model with “strangers” — more than 100 additional Hanabi models that it had never encountered before and trained by separate algorithms — in millions of two-player games.
Any-Play pairings surpassed all other teams composed of algorithmically distinct mates. It also rated higher when paired with its untrained version.
Inter-algorithm cross-play is considered by the researchers to be the most accurate predictor of how cooperative AI would behave in the real world alongside humans. Inter-algorithm cross-play contrasts with evaluations that compare a model against replicas of itself or models trained by the same algorithm.
Researchers contend that these other indicators can be deceptive and unduly inflate the apparent performance of some algorithms. Instead, researchers want to see how well you can communicate when thrown together with a partner without a prior understanding of their playing style. Researchers believe this review method is the most realistic when assessing cooperative AI with other AI in the absence of human testers.

Human testing of Any-Play was not conducted in this study. Simultaneously with the lab’s findings, DeepMind published research employing a similar diversity-training strategy to create an AI entity capable of playing the cooperative game Overcooked with people. This outcome leads us to believe that this technique, which is even more generalizable, might also work well with humans. Facebook similarly exploited variety in training to promote collaboration among Hanabi AI agents but employed a more involved method that required adjustments to the Hanabi game rules to be tractable.
It is still a theory about whether inter-algorithm cross-play ratings are accurate indications of human preference. To reintroduce the human perspective into the process, the researchers intend to attempt a correlation between a person’s attitudes toward an AI, such as mistrust or perplexity, and the specific training objectives used to develop the AI. The discovery of these links could expedite the field’s progress.
The difficulty with developing AI to work more effectively with people is that scientists cannot have humans in the training loop telling AI what they like and dislike. However, if a scientist could develop a quantifiable proxy for human choice and diversity in training may be such a proxy, this could be a solution.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Any-Play: An Intrinsic Augmentation for Zero-Shot Coordination'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github and post. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.