New Models For More Precise Speech AI Are Now Available On Google Cloud

This Article Is Based On The Google Article 'Google Cloud launches new models for more accurate Speech AI'. 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Early adopters have already experienced the advantages of the new models. “Spotify and Google cooperated to bring a new voice interface, ‘Hey Spotify,’ mobile apps, and Car Thing. The current models’ quality enhancements, especially noise robustness, and Spotify’s work on NLU and AI allow these services to run well for so many users.
With voice continuing to be the new frontier in human-computer interaction, many businesses may aim to improve their technology and provide customers with speech recognition systems that are more reliable and accurate. Better speech recognition allows users to communicate with their apps and devices.
This opens the door to many new applications, ranging from hands-free driving to voice assistants on smart devices. Furthermore, accurate voice recognition enables live subtitles in video meetings, insights from live and recorded conversations, and more and provides machine command. Client interest in Speech-to-Text (STT) API has grown in the five years since its introduction, with the API now processing over 1 billion minutes of speech every month. That’s enough for about 4.6 million times each month, and it’s equivalent to listening to Wagner’s 15-hour Der Ring des Nibelungen over 1.1 million times.

Improved accuracy and comprehension with new models
The new model’s design is based on cutting-edge machine learning techniques, allowing us to better exploit our speech training data and achieve better results.
So, how does this model vary from the current one?
ASR approaches have been based on independent acoustic, pronunciation, and language models. Traditionally, each of these three components was trained independently and then combined to perform speech recognition.
When adopting the STT API, both businesses and developers will see immediate quality improvements. It can also modify the model for improved performance. It also allows for the implementation of voice technologies in applications more quickly, easily, and efficiently.
For making speech control interfaces for intelligent devices and apps, these enhancements will allow users to talk more naturally and in longer sentences to these interfaces. Users can form better relationships with the machines and applications they can interact with the company as the brand driving the experience—without worrying about whether their voice will be appropriately captured.
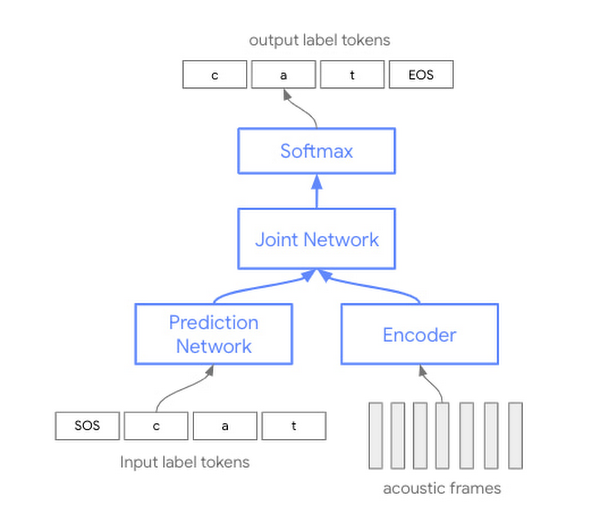
The STT API is now introducing these models under a new identifier—”latest”—to support these models while still preserving the existing ones. As we continue to update, customers will gain access to the latest conformer models if they select “latest long” or “latest short” as we continue to correct them. Like the existing “video” format, “Latest long” is built exclusively for long-form spontaneous speech. On the other hand, “latest short” provides excellent quality and speed for brief utterances like orders and phrases.
It is committed to keeping these models up to date so that users can get the most up-to-date Google voice recognition research. These models may differ slightly from current ones like “default” or “command and search,” but they’re all covered by the same GA STT API stability and support assurances as the rest of the GA STT API services.
To learn further, refer here.
Source: https://cloud.google.com/blog/products/ai-machine-learning/google-cloud-updates-speech-api-models-for-improved-accuracy
Documentation: https://cloud.google.com/speech-to-text/docs/languages
Credit: Source link
Comments are closed.