No, no, Let’s Not Put it There! This AI Method Can Do Continuous Layout Editing with Diffusion Models
At this point, everyone is familiar with text-to-image models. They made their way in with the release of stable diffusion last year, and since then, they have been used in many applications. More importantly, they kept getting better and better to the point where it was challenging to differentiate AI-generated images from real ones.
Text-to-image models are a groundbreaking technology that bridges the gap between language and visual understanding. They possess a remarkable capability to generate realistic images based on textual descriptions. This unlocks a new level of content generation and visual storytelling.
These models leverage the power of deep learning and large-scale datasets.
They represent a cutting-edge fusion of natural language processing (NLP) and computer vision (CV). They use deep neural networks and advanced techniques to translate the semantic meaning of words into visual representations.
The process begins with the text encoder, which encodes the input textual description into a meaningful latent representation. This representation serves as a bridge between the language and image domains. The image decoder then takes this latent representation and generates an image that aligns with the given text. Through an iterative training process, where the model learns from vast datasets of paired text-image examples, these models gradually refine their ability to capture the details expressed in textual descriptions.
Though, the major problem of text-to-image models is the limitation in their control of image layouts. Despite recent advancements in the field, accurately expressing precise spatial relationships through text remains challenging. A significant obstacle in continuous layout editing is the need to preserve the visual properties of the original image while rearranging and editing the positions of objects within it.
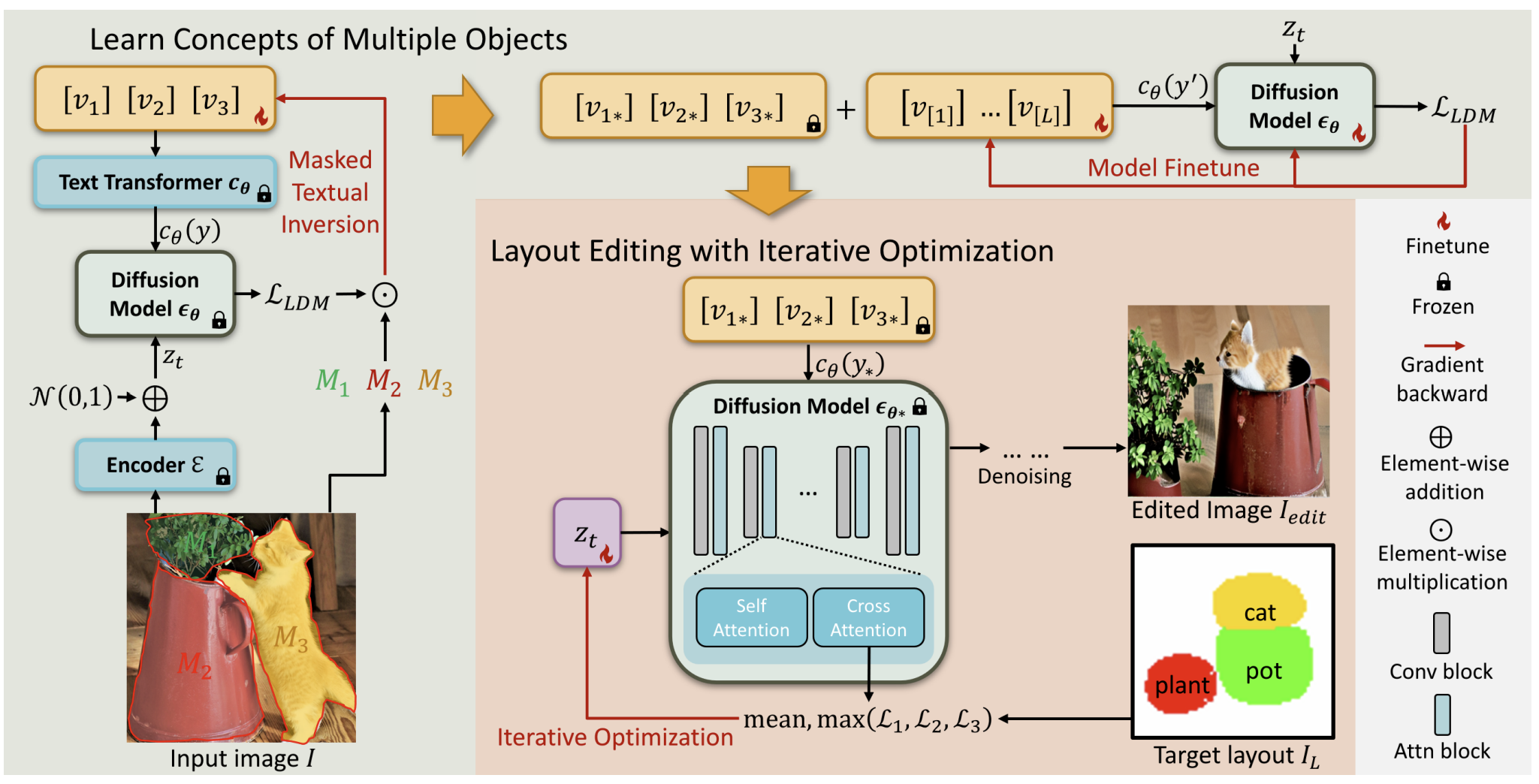
What if there was a way to overcome this limitation? Time to meet with Continuous Layout Editing. It is a new research that proposes a novel layout editing for single-input images.
Traditional methods have struggled to learn concepts for multiple objects within a single image. One of the reasons is that textual descriptions often leave room for interpretation, making it difficult to capture specific spatial relationships, fine-grained details, and nuanced visual attributes. Moreover, traditional methods often struggle to accurately align objects, control their positions, or adjust the overall scene layout based on the provided text input.
To overcome these limitations, Continuous Layout Editing uses a novel method called masked textual inversion. By disentangling the concepts of different objects and embedding them into separate tokens, the proposed method effectively captures the visual characteristics of each object through the corresponding token embedding. This breakthrough empowers precise control over object placement, facilitating the generation of visually appealing layouts.
It uses a training-free optimization method to achieve layout control with diffusion models. The core idea is to optimize the cross-attention mechanism during the diffusion process iteratively. This optimization is guided by a region loss that prioritizes the alignment of specified objects with their designated regions in the layout. By encouraging stronger cross-attention between an object’s text embedding and its corresponding region, the method enables precise and flexible control over object positions, all without requiring additional training or fine-tuning of pre-trained models.
Continuous Layout Editing outperforms other baseline techniques in editing the layout of single images. Moreover, it includes a user interface for interactive layout editing, enhancing the design process and making it more intuitive for users.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 26k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Ekrem Çetinkaya received his B.Sc. in 2018, and M.Sc. in 2019 from Ozyegin University, Istanbul, Türkiye. He wrote his M.Sc. thesis about image denoising using deep convolutional networks. He received his Ph.D. degree in 2023 from the University of Klagenfurt, Austria, with his dissertation titled “Video Coding Enhancements for HTTP Adaptive Streaming Using Machine Learning.” His research interests include deep learning, computer vision, video encoding, and multimedia networking.
Credit: Source link
Comments are closed.