Nomic AI Introduces Nomic Embed: Text Embedding Model with an 8192 Context-Length that Outperforms OpenAI Ada-002 and Text-Embedding-3-Small on both Short and Long Context Tasks
Nomic AI released an embedding model with a multi-stage training pipeline, Nomic Embed, an open-source, auditable, and high-performing text embedding model. It also has an extended context length supporting tasks such as retrieval-augmented-generation (RAG) and semantic search. The existing popular models, including OpenAI’s text-embedding-ada-002, lack openness and auditability. The model addresses the challenge of developing a text embedding model that outperforms current closed-source models.
Current state-of-the-art models dominate long-context text embedding tasks. However, their closed-source nature and unavailability of training data for auditability pose limitations. The proposed solution, Nomic Embed, provides an open-source, auditable, and high-performing text embedding model. Nomic Embed’s key features include an 8192 context length, reproducibility, and transparency.
Nomic Embed is built through a multi-stage contrastive learning pipeline. It starts with training a BERT model with a context length of 2048 tokens, named nomic-bert-2048, with modifications inspired by MosaicBERT. The training involves:
- Rotary position embeddings,
- SwiGLU activations,
- Deep speed and FlashAttention,
- BF16 precision.
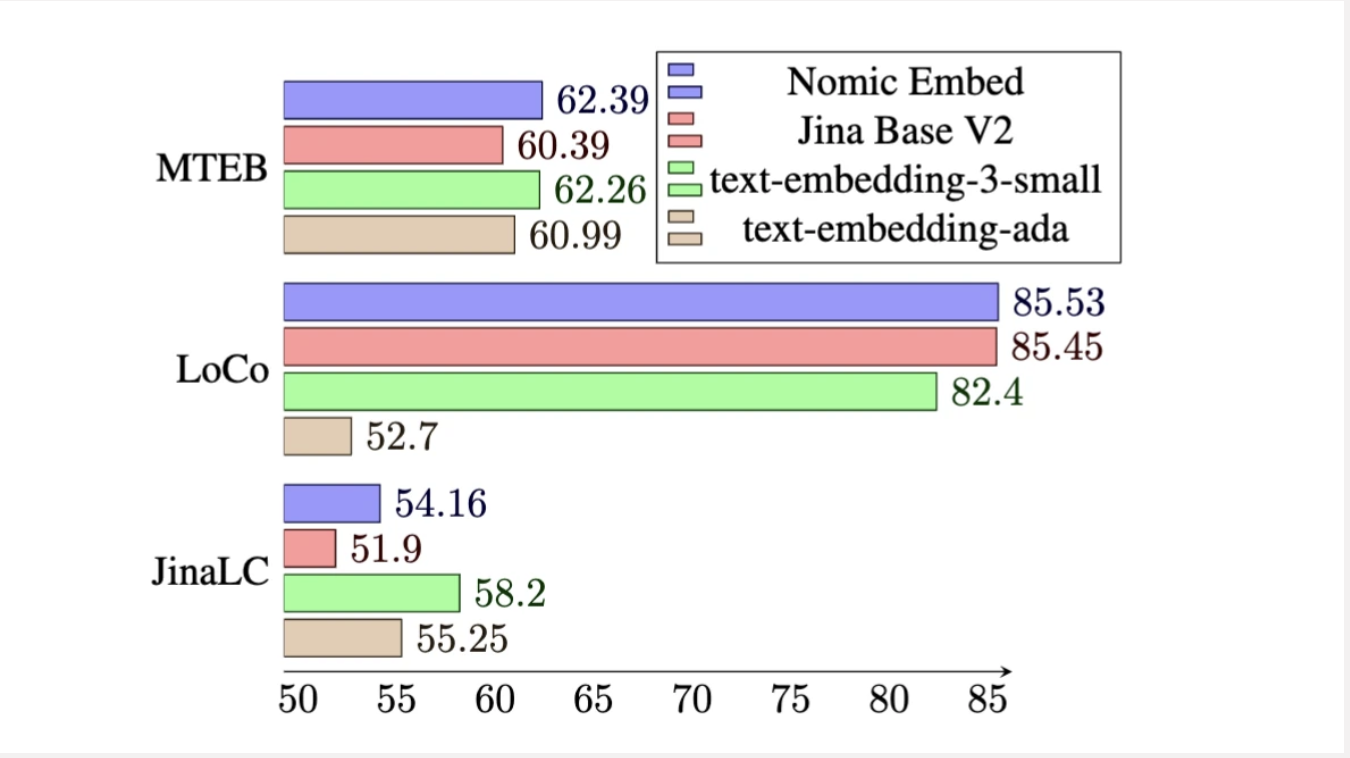
It used vocabulary with increased size and a batch size of 4096. The model is then contrastively trained with ~235M text pairs, ensuring high-quality labeled datasets and hard-example mining. Nomic Embed outperforms existing models on benchmarks like the Massive Text Embedding Benchmark (MTEB), LoCo Benchmark, and the Jina Long Context Benchmark.
Nomic Embed not only surpasses closed-source models like OpenAI’s text-embedding-ada-002 but also outperforms other open-source models on various benchmarks. The emphasis on transparency, reproducibility, and the release of model weights, training code, and curated data showcase a commitment to openness in AI development. Nomic Embed’s performance on long-context tasks and the call for improved evaluation paradigms underscore its significance in advancing the field of text embeddings.
![]()
Pragati Jhunjhunwala is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Kharagpur. She is a tech enthusiast and has a keen interest in the scope of software and data science applications. She is always reading about the developments in different field of AI and ML.
Credit: Source link
Comments are closed.