Nomic AI Releases the First Fully Open-Source Long Context Text Embedding Model that Surpasses OpenAI Ada-002 Performance on Various Benchmarks
In the evolving landscape of natural language processing (NLP), the ability to grasp and process extensive textual contexts is paramount. Recent advancements, as highlighted by Lewis et al. (2021), Izacard et al. (2022), and Ram et al. (2023), have significantly propelled the capabilities of language models, particularly through the development of text embeddings. These embeddings serve as the backbone for a plethora of applications, including retrieval-augmented generation for large language models (LLMs) and semantic search. They transform sentences or documents into low-dimensional vectors, capturing the essence of semantic information, which in turn facilitates tasks like clustering, classification, and information retrieval.
However, a glaring limitation has been the context length that these models can handle. The majority of widely recognized open-source models on the MTEB benchmark, such as E5 by Wang et al. (2022), GTE by Li et al. (2023), and BGE by Xiao et al. (2023), are confined to a context length of 512 tokens. This restriction undermines their utility in scenarios where understanding the broader document context is crucial. In contrast, models capable of surpassing a context length of 2048, like Voyage-lite-01-instruct by Voyage (2023) and text-embedding-ada-002 by Neelakantan et al. (2022), remain behind closed doors.
Amid this backdrop, the introduction of nomicembed-text-v1 marks a significant milestone. This model is not only open-source but also boasts an impressive sequence length of 8192, outperforming its predecessors in both short and long-context evaluations. What sets it apart is its comprehensive approach, merging the strengths of open weights, open data, and a 137M parameter design under an Apache-2 license, ensuring accessibility and transparency.
The journey to achieving such a feat involved meticulous stages of data preparation and model training. Initially, a Masked Language Modeling Pretraining phase utilized resources like BooksCorpus and a Wikipedia dump from 2023, employing the bert-base-uncased tokenizer to create data chunks suited for long-context training. This was followed by Unsupervised Contrastive Pretraining, leveraging a vast collection of 470 million pairs across diverse datasets to refine the model’s understanding through consistency filtering and selective embedding.
The architecture of nomicembed-text-v1 reflects a thoughtful adaptation of BERT to accommodate the extended sequence length. Innovations such as rotary positional embeddings, SwiGLU activation, and the integration of Flash Attention highlight a strategic overhaul to enhance performance and efficiency. The model’s training regimen, characterized by a 30% masking rate and optimized settings, further underscores the rigorous effort to achieve optimal results.
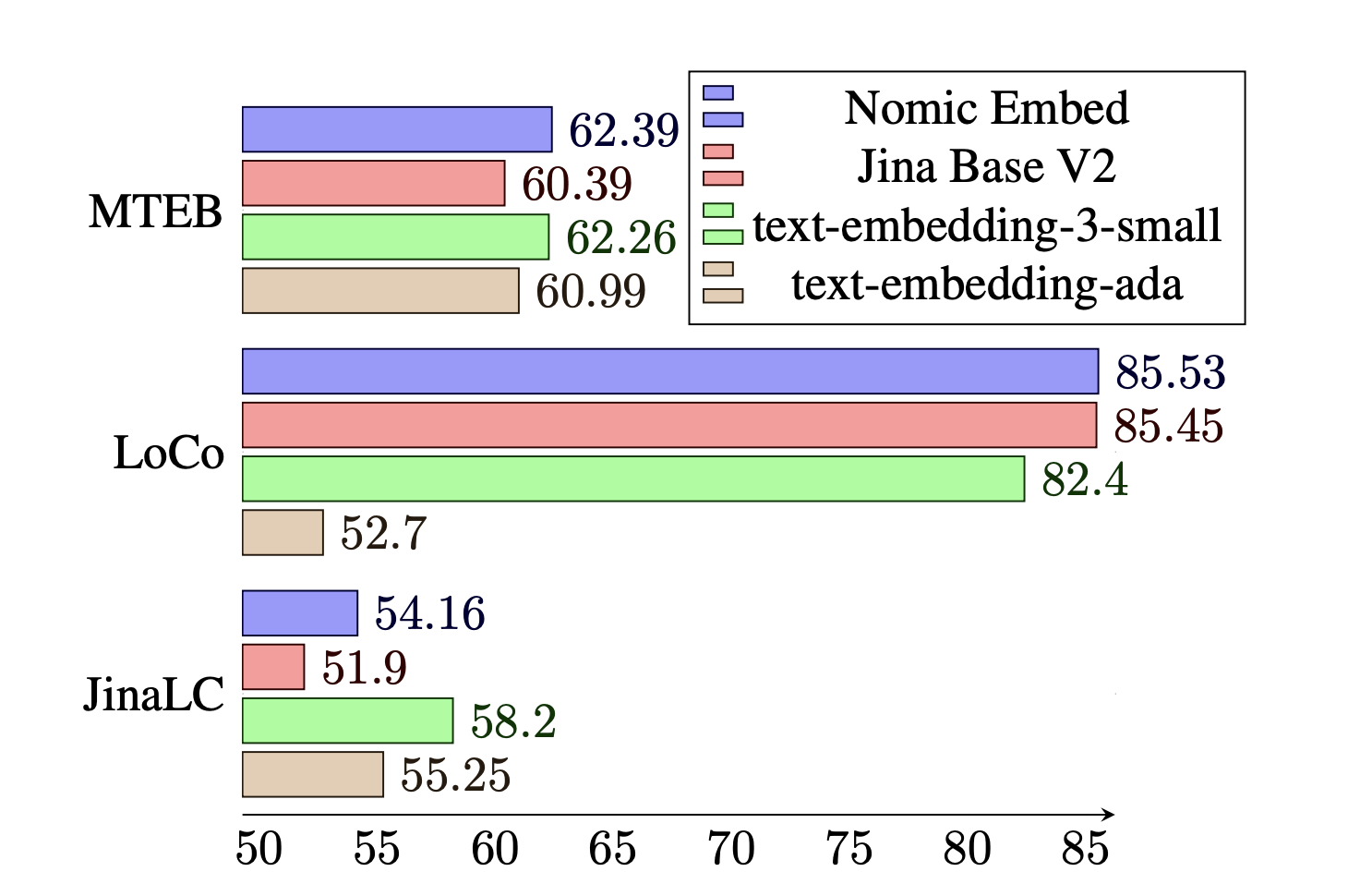
When subjected to the rigors of benchmarks like GLUE, MTEB, and specialized long-context assessments, nomicembed-text-v1 demonstrated exceptional prowess. Notably, its performance in the JinaAI Long Context Benchmark and the LoCo Benchmark underscores its superiority in handling extensive texts, an area where many predecessors faltered.
Yet, the journey of nomicembed-text-v1 extends beyond mere performance metrics. Its development process, emphasizing end-to-end auditability and the potential for replication, sets a new standard for transparency and openness in the AI community. By releasing the model weights, codebase, and a curated training dataset, the team behind nomicembed-text-v1 invites ongoing innovation and scrutiny.
In conclusion, nomicembed-text-v1 emerges not just as a technological breakthrough but as a beacon for the open-source movement in AI. It dismantles barriers to entry in the domain of long-context text embeddings, promising a future where the depth of understanding matches the breadth of human discourse.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 37k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.