NTU Researchers Propose ‘NOAH’: Neural Prompt Search for Large Vision Models
The scale of vision models has increased tremendously in recent years, from tens of millions to hundreds of millions, if even billions, for Transformers. The first is that fine-tuning becomes more difficult, as huge model sizes can easily lead to overfitting in a typical-sized dataset, not to mention the rise in computing and storage costs.
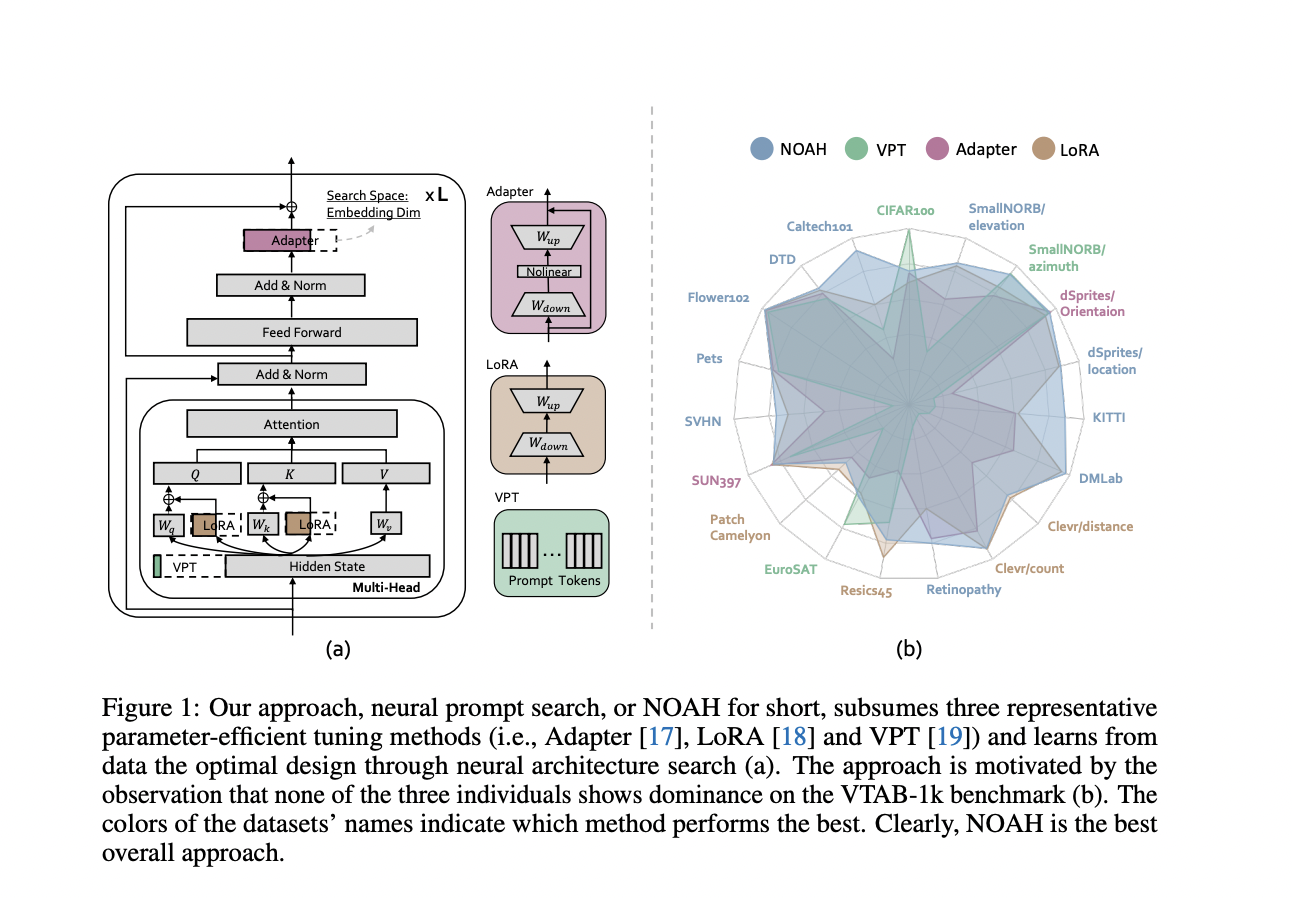
There has been a surge in interest in creating parameter-efficient tuning algorithms in recent years. The essential concept is to add a small trainable module to a big pre-trained model and only tweak its parameters by maximizing task-specific losses such as cross-entropy for classification issues. Adapter, Low-Rank Adaptation (LoRA), and Visual Prompt Tuning are the most representative ways (VPT). VPT prepends additional tokens to the input of a Transformer block, which can be seen as adding learnable “pixels.” An adapter is a bottleneck-shaped neural network appended to a network block’s output; LoRA is a “residual” layer consisting of rank-decomposition matrices, and VPT is a “residual” layer consisting of rank-decomposition matrices.
The three parameter-efficient tuning approaches, on the other hand, have a handful of serious flaws. To begin with, none of the three techniques consistently perform well across all datasets. The findings show that, for a given dataset, a thorough study of several tuning strategies is required in order to determine the best appropriate one. Second, the choice of model parameters, such as the Adapter’s feature dimension or the token length in VPT, is discovered to affect performance.
In a recent paper, researchers from Nanyang Technological University in Singapore interpreted existing parameter-efficient tuning approaches as prompt modules and proposed using a neural architecture search (NAS) algorithm to automatically search for the best prompt design from data. They proposed the Neural prOmpt seArcH (NOAH) approach for large vision models, especially those incorporating the Transformer block. Subsuming Adapter, LoRA, and VPT into each Transformer block creates the search space.

Researchers tested a variety of vision datasets over a wide range of visual domains, including objects, scenes, textures, and satellite photography. On 10 of the 19 datasets, NOAH significantly outperforms individual prompt modules, while performance on the remaining datasets is extremely competitive. They also tested NOAH against hand-crafted prompt modules in terms of few-shot learning and domain generalization, with the findings confirming NOAH’s superiority.
Conclusion
In order to reach a given learning capacity, model size in neural networks has been expanded in tandem with the spread of large-scale pre-training data. The significant rise in model size, on the other hand, has sparked interest in developing effective transfer learning approaches. Researchers from Nanyang Technological University in Singapore recently published data on how recently proposed parameter-efficient tuning approaches, or prompt modules, perform in computer vision tasks. The results also highlight a major issue: hand-designing an appropriate prompt module for any unique downstream dataset is incredibly difficult. In order to fully utilize NOAH’s potential, more labels would be required. For future study, the team intends to delve deeper into the mechanics behind NOAH in order to better comprehend the exciting results and apply NOAH to areas other than computer vision, such as natural language processing (NLP).
This Article is written as a summary article by Marktechpost Staff based on the paper 'Neural Prompt Search'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.