NVIDIA AI Research Releases HelpSteer: A Multiple Attribute Helpfulness Preference Dataset for STEERLM with 37k Samples
In the significantly advancing field of Artificial Intelligence (AI) and Machine Learning (ML), developing intelligent systems that smoothly align with human preferences is crucial. The development of Large Language Models (LLMs), which seek to imitate humans by generating content and answering questions like a human, has led to massive popularity in AI.
SteerLM, which has been recently introduced as a technique for supervised fine-tuning, gives end users more control over model responses during inference. In contrast to traditional methods like Reinforcement Learning from Human Feedback (RLHF), SteerLM uses a multi-dimensional collection of expressly stated qualities. This gives users the ability to direct AI to produce responses that satisfy preset standards, such as helpfulness, and allow customization based on particular requirements.
The criterion differentiating more helpful responses from less helpful ones is not well-defined in the open-source datasets currently available for training language models on helpfulness preferences. As a result, models trained on these datasets sometimes unintentionally learn to favor specific dataset artifacts, such as giving longer responses more weight than they actually have, even when those responses aren’t that helpful.
To overcome this challenge, a team of researchers from NVIDIA has introduced a dataset called HELPSTEER, an extensive compilation created to annotate many elements that influence how helpful responses are. This dataset has a large sample size of 37,000 samples and has annotations for verbosity, coherence, accuracy, and complexity. It also has an overall helpfulness rating for every response. These characteristics go beyond a straightforward length-based preference to offer a more nuanced view of what constitutes a truly helpful response.
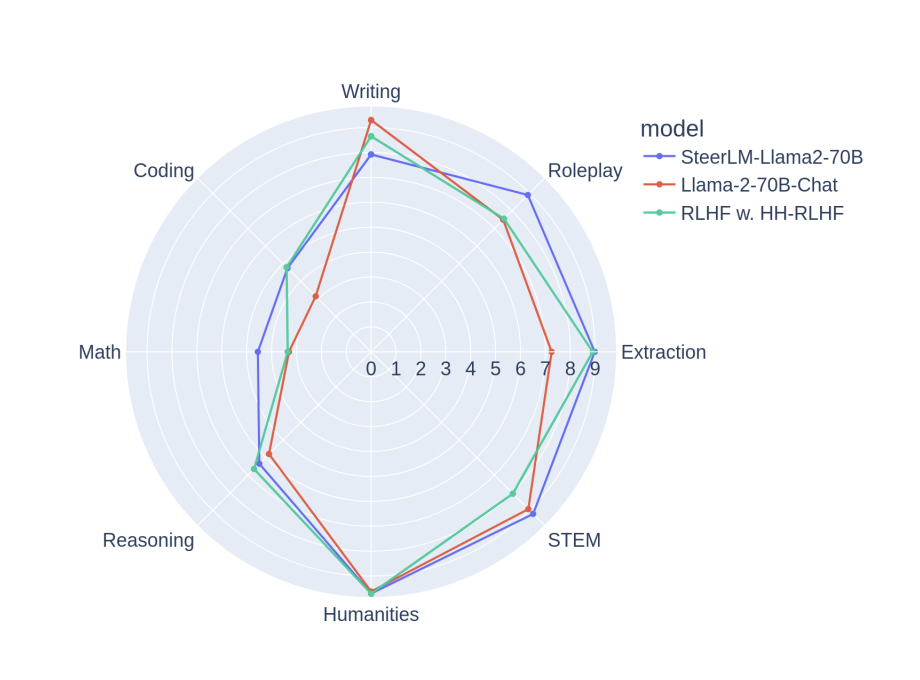
The team has used the Llama 2 70B model with the STEERLM approach to train language models efficiently on this dataset. The final model has outperformed all other open models without using training data from more complex models such as GPT-4, achieving a high score of 7.54 on the MT Bench. This demonstrates how well the HELPSTEER dataset works to improve language model performance and solve issues with other datasets.
The HELPSTEER dataset has been made available by the team for use under the International Creative Commons Attribution 4.0 Licence. This publicly available dataset can be used by language researchers and developers to continue the development and testing of helpfulness-preference-focused language models. The dataset can be accessed on HuggingFace at https://huggingface.co/datasets/nvidia/HelpSteer.
The team has summarized their primary contributions as follows,
- A 37k-sample helpfulness dataset has been developed consisting of annotated responses for accuracy, coherence, complexity, verbosity, and overall helpfulness.
- Llama 2 70B has been trained using the dataset, and it has achieved a leading MT Bench score of 7.54, outperforming models that do not rely on private data, including GPT4.
- The dataset has been made publicly available under a CC-BY-4.0 license to promote community access for further study and development based on the findings.
In conclusion, the HELPSTEER dataset is a great introduction as it bridges a significant void in currently available open-source datasets. The dataset has demonstrated efficacy in educating language models to give precedence to characteristics such as accuracy, consistency, intricacy, and expressiveness, leading to enhanced outcomes.
Check out the Paper and Dataset. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Tanya Malhotra is a final year undergrad from the University of Petroleum & Energy Studies, Dehradun, pursuing BTech in Computer Science Engineering with a specialization in Artificial Intelligence and Machine Learning.
She is a Data Science enthusiast with good analytical and critical thinking, along with an ardent interest in acquiring new skills, leading groups, and managing work in an organized manner.
Credit: Source link
Comments are closed.