NVIDIA Researchers Introduce Audio Flamingo: A Novel Audio Language Model with Few-Shot Learning and Dialogue Abilities
The exploration of augmenting large language models (LLMs) with the capability to understand and process audio, including non-speech sounds and non-verbal speech, is a burgeoning field. This area of research aims to extend the applicability of LLMs from interactive voice-responsive systems to sophisticated audio analysis tools. The challenge, however, lies in developing models that can effectively comprehend audio inputs beyond mere speech transcription. It involves recognizing and interpreting a wide range of sounds, including music, environmental noises, and non-verbal vocalizations, which carry rich information critical for various applications.
Current research trends focus on transcribing speech or identifying specific sounds within an audio file. Techniques such as CNNs and transformers extract audio features, though they often need more temporal nuances. Data augmentation and in-context learning (ICL) strategies are being developed to enhance model adaptability. Retrieval-augmented generation (RAG) leverages external knowledge to improve output quality, underscoring the diverse approaches explored to deepen LLMs’ understanding across various modalities.
A team of researchers at NVIDIA has introduced Audio Flamingo, a novel audio language model. It demonstrates enhanced audio comprehension, quick adaptation to new tasks using in-context learning and retrieval, and effective multi-turn dialogue management. Through unique training methods, architectural innovations, and strategic data use, Audio Flamingo significantly improves performance on diverse audio tasks, establishing new standards in the domain.
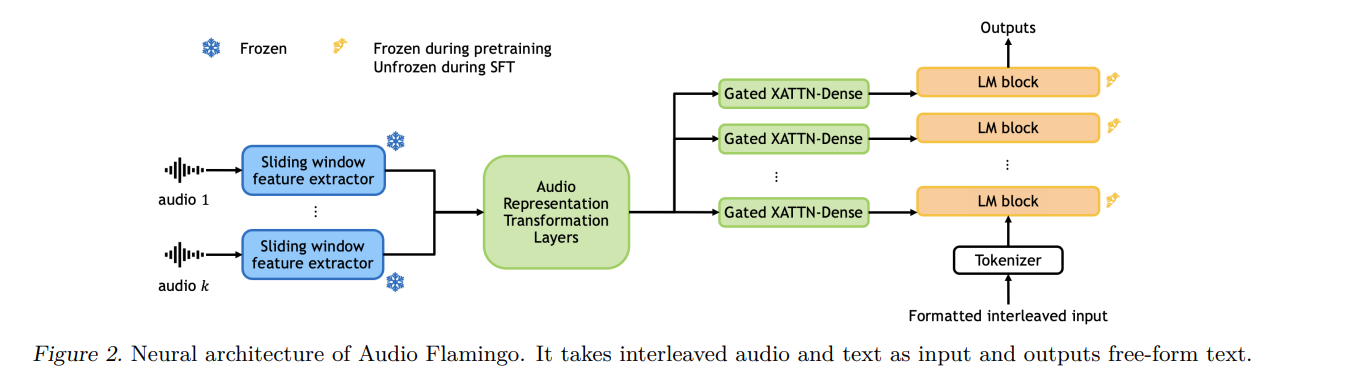
Audio Flamingo employs ICL datasets from kNN computations on audio embeddings to improve the model’s learning and retrieval processes. The methodology distinguishes between pre-training and supervised fine-tuning stages, using varied datasets selected based on specific criteria. It also outlines structured templates for data samples and creates two multi-turn dialogue datasets via GPT-4. Experiments are conducted to assess Audio Flamingo’s efficacy, exploring its performance, ICL-based RAG’s impact, dialogue capabilities, and optimal setup.
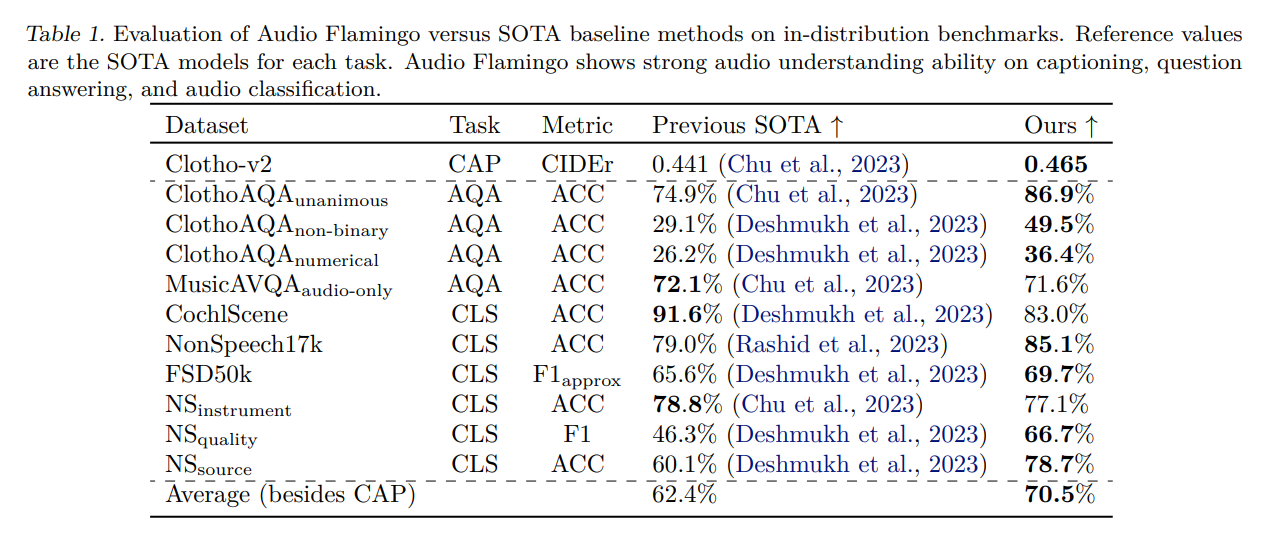
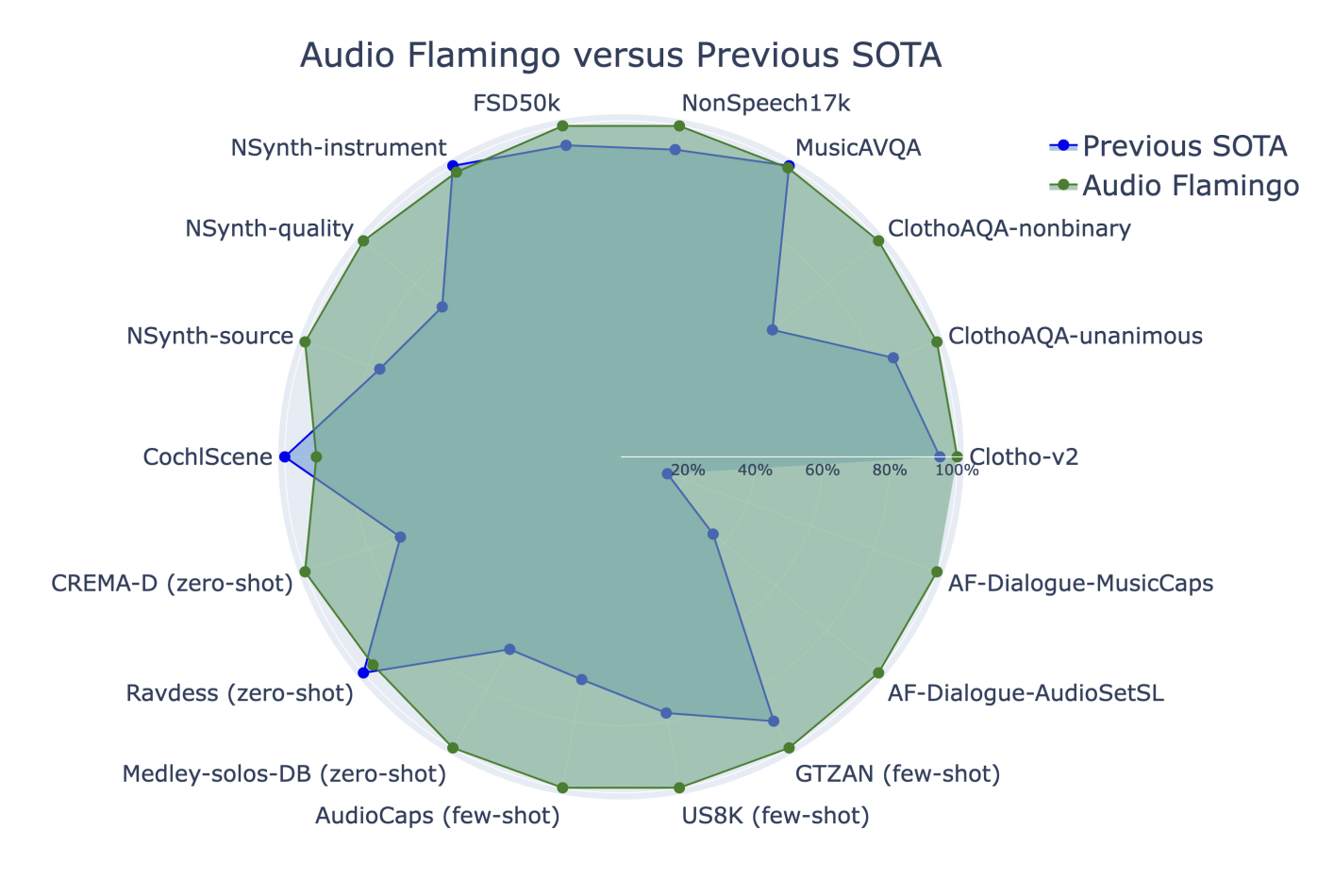
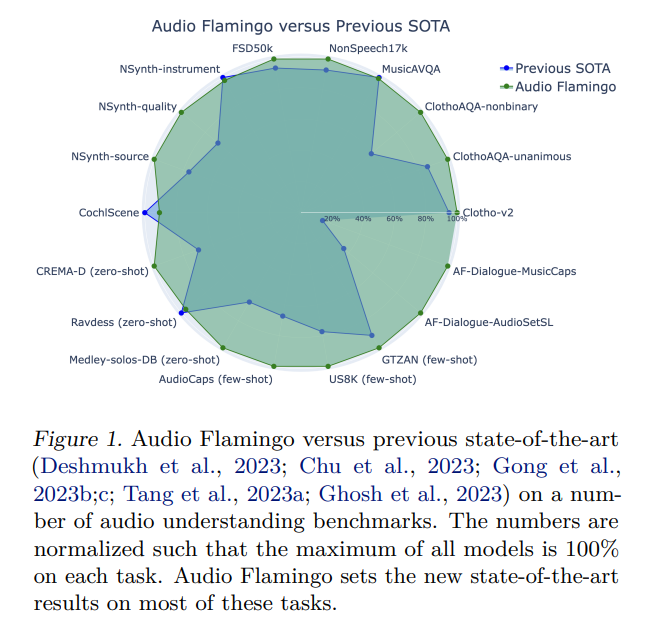
The model demonstrates strong audio understanding abilities and the ability to adapt to unseen tasks quickly via in-context learning and retrieval. It also exhibits strong multi-turn dialogue abilities, outperforming baseline methods in terms of results. Audio Flamingo sets new state-of-the-art benchmarks in various audio understanding tasks, confirming its efficacy. The model shows strong generalization ability and performs better than most zero-shot methods on multiple tasks.
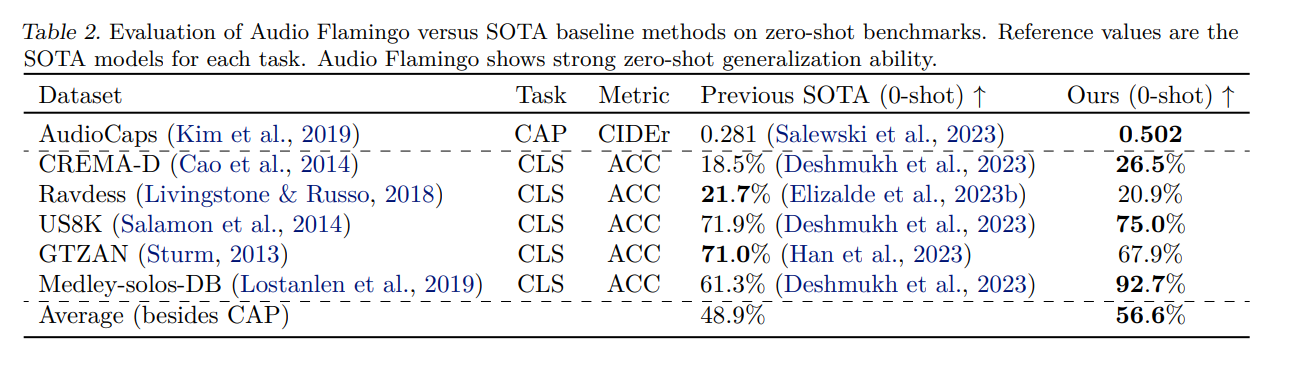
In summary, the introduction of Audio Flamingo is a significant advancement in audio understanding within large language models. By addressing the critical challenges of feature extraction, adaptability to new tasks, and dialogue processing, the research team has presented a comprehensive solution that broadens the scope of audio comprehension technologies. Audio Flamingo’s remarkable performance across diverse benchmarks underscores its potential to transform real-world applications, from interactive systems to analytical tools, through a deeper, more nuanced understanding of audio environments.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and Google News. Join our 36k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our Telegram Channel
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.