NVIDIA Researchers Present ‘RANA,’ a Novel Artificial Intelligence Framework for Learning Relightable and Articulated Neural Avatars of Humans
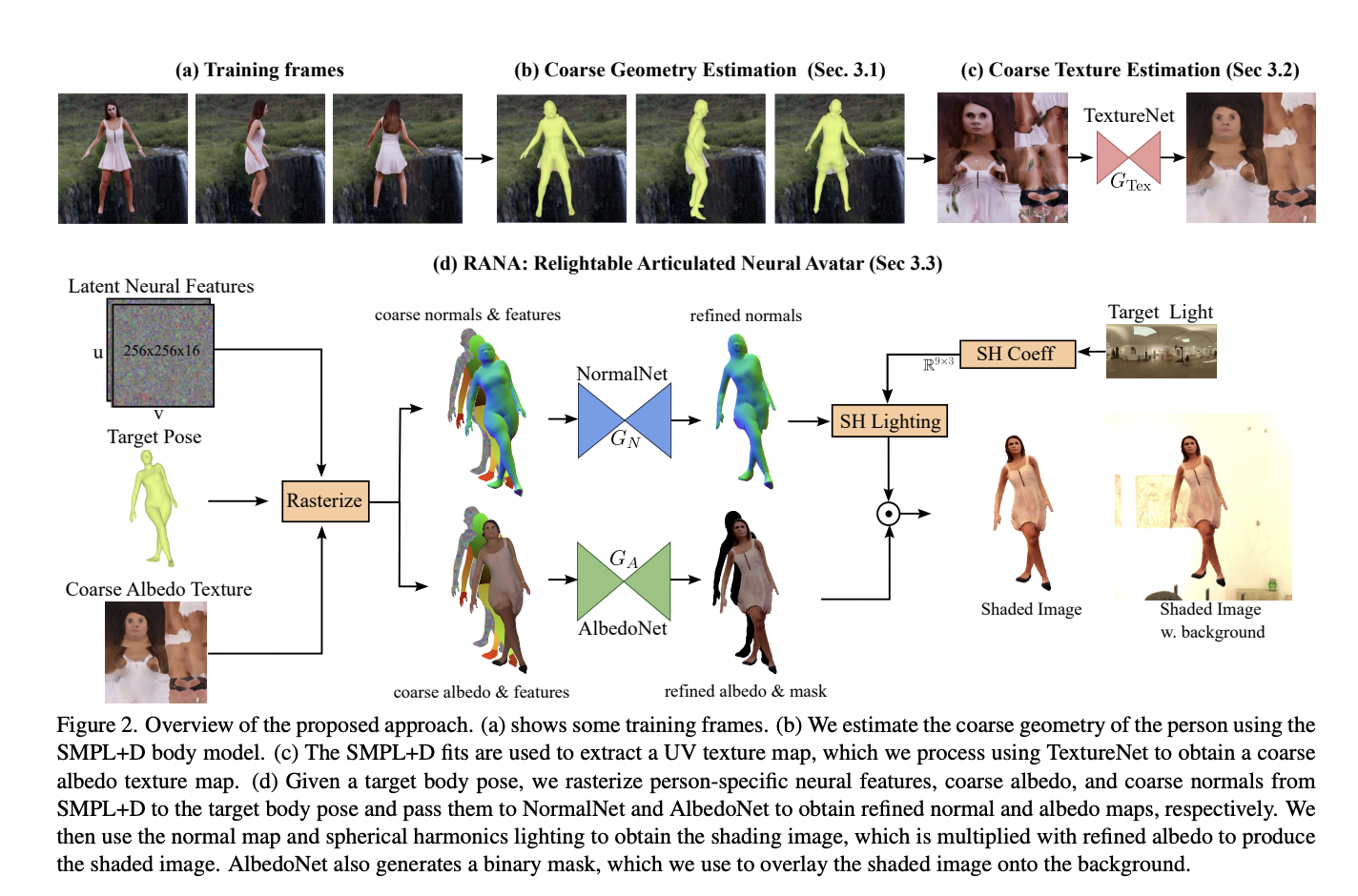
Human-like articulated neural avatars have several uses in telepresence, animation, and visual content production. These neural avatars must be simple to create, simple to animate in new stances and views, capable of rendering in photorealistic picture quality, and simple to relight in novel situations if they are to be widely adopted. Existing techniques frequently use monocular films to teach these neural avatars. While the method permits movement and photorealistic image quality, the synthesized images are constantly constrained by the training video’s lighting conditions. Other studies specifically address the relighting of human avatars. However, they do not provide the user control over the body stance. Additionally, these methods frequently need multiview photos captured in a Light Stage for training, which is only permitted in controlled environments.
Some contemporary techniques seek to relight dynamic human beings in RGB movies. However, they lack control over body posture. They need a brief monocular video clip of the person in their natural location, attire, and body stance to produce an avatar. Only the target novel’s body stance and illumination information are needed for inference. It is difficult to learn relightable neural avatars of active individuals from monocular RGB films captured in unfamiliar surroundings. Here, they introduce the Relightable Articulated Neural Avatar (RANA) technique, which enables photorealistic human animation in any new body posture, perspective, and lighting situation. It first needs to simulate the intricate articulations and geometry of the human body.
The texture, geometry, and illumination information must be separated to enable relighting in new contexts, which is a difficult challenge to tackle from RGB footage. To overcome these difficulties, they first use a statistical human shape model called SMPL+D to extract canonical, coarse geometry, and texture data from the training frames. Then, they suggest a unique convolutional neural network trained on artificial data to exclude the shading information from the coarse texture. They add learnable latent characteristics to the coarse geometry and texture and send them to their proposed neural avatar architecture, which uses two convolutional networks to produce fine normal and albedo maps of the person underneath the goal body posture.
They construct the final shaded image using spherical harmonics (SH) illumination based on the normal map, albedo map, and lighting data. Since the lighting of the surroundings is unknown during training, they jointly optimize it with the person’s look. They suggest new regularisation terms to stop sunlight from seeping into the albedo texture. Additionally, they suggest employing synthetic photorealistic data combined with ground-truth normal and albedo maps to pre-train the avatar. With distinct neural features for every subject, they simultaneously train a single avatar model for several individuals during pretraining. This enhances the neural avatar’s capacity to adapt to new body positions and trains it to dissociate texture and geometry information.
They only learn a fresh set of neural features to capture fine-grained person-specific characteristics for a new subject. In their research, it is possible to realize an avatar for a novel issue after 15k training repetitions. To their knowledge, RANA is the first technique to make it possible for neural avatars to be relightable and articulated. As a result, they also provide a brand-new photorealistic synthetic dataset, Relighting Humans (RH), comprising ground truth albedo, normals, and lighting information, to assess the effectiveness of their strategy quantitatively. A simultaneous evaluation of the performance in terms of new posture and novel light synthesis is possible with the help of the Relighting Humans dataset.
On the People Snapshot dataset, they also evaluate RANA qualitative to compare with other baselines. The following is a summary of their contributions:
• They introduce RANA, a cutting-edge system for relightable, articulated neural avatar learning from brief, unrestricted monocular films. The suggested method is very simple to teach and does not need prior familiarity with the setting of the training video.
• The suggested method can create photorealistic photographs of people in everybody’s stance, from any angle, with any illumination. Additionally, it may be used to relight footage of animated people.
• To further this study, they provide a brand-new photorealistic synthetic dataset for quantitative analysis.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.