NVIDIA Researchers Propose Global Context Vision Transformer (GC ViT): A Novel Architecture That Enhances Parameter And Compute Utilization
Vision Transformer (ViT) has become one of the most cutting-edge architectures for computer vision (CV) problems in contemporary transformer architectures associated with natural language processing. Compared to traditional CNN techniques, this transformer-based model demonstrates exceptional capabilities in modeling short and long-range information. The quadratic computing complexity ViT demands, which makes modeling high-resolution images prohibitively expensive, is the fundamental limitation on further ViT development and application. A team of NVIDIA researchers has proposed a unique yet straightforward hierarchical ViT design named Global Context Vision Transformer (GC ViT). This architecture’s global self-attention and token generation modules enable effective modeling without expensive computations while providing cutting-edge performance across various computer vision tasks. The team has proposed this architecture in their recent paper titled Global Context Vision Transformers.
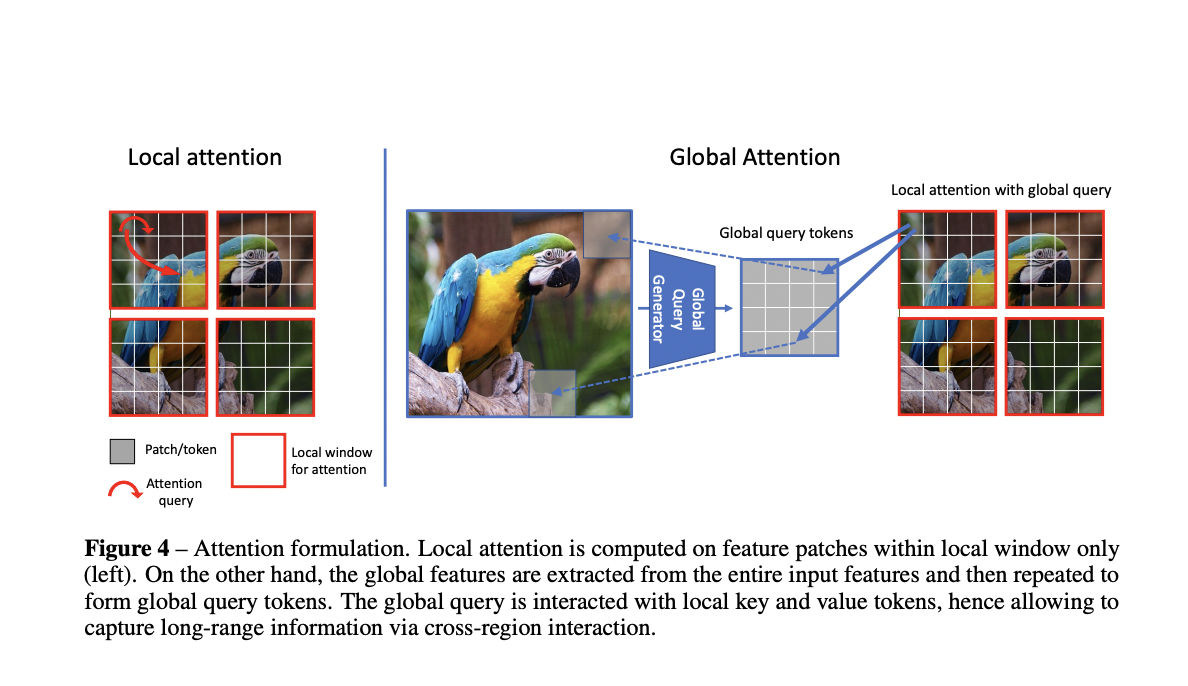
The GC ViT architecture has a hierarchical framework that easily captures feature representations at various resolutions. When given an input image, the model applies a predefined convolutional layer with the proper padding to produce overlapping patches. According to the research team, this approach can be used as a general framework for various computer vision tasks, including classification, detection, and instance segmentation. The model’s simple construction, which enables the modeling of short- and long-range connections by capturing global contextual information, reduces the need for complex computations. The proposed GC ViT outperforms both CNN and ViT-based models by a wide margin, achieving new state-of-the-art benchmarks on the ImageNet-1K dataset for various model sizes and FLOPs. GC ViT also achieves SOTA performance on the MS COCO and ADE20K datasets for object detection and semantic segmentation.

Each GC ViT processing stage alternates between local and global self-attention modules to extract spatial features. The global self-attention mechanism accesses the innovative Global Token Generator’s features. The generated features are then transmitted through average pooling and linear layers to provide an embedding for subsequent tasks. In their empirical experiments, the researchers tested the proposed GC ViT on CV tasks such as image classification, objection detection, instance segmentation, and semantic segmentation. The team’s proposed architecture can be summarised to efficiently capture the overall context and achieve SOTA performance on CV tasks. Although GC ViT does not increase the computational cost, training is still somewhat expensive regardless of the transformer architecture. The researchers add that strategies like reduced precision or quantization might make GC ViT training more effective. The GC ViT code can also be accessed on the project’s GitHub page.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'Global Context Vision Transformers'. All credit for this research goes to researchers on this project. Checkout the paper, github. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.