OneFormer: An Universal Image Segmentation Framework That Unifies Segmentation With A Multi-Task Train-Once Design
Pixels are divided into many segments during the process of image segmentation. Such categorization may be instance-based or semantic (e.g., road, sky, building). A unique research effort was put into these two segmentation tasks in earlier segmentation systems, which used specialized structures. In a recent attempt to combine semantic and instance segmentation, Kirillov et al. suggested panoptic segmentation, with pixels sorted into discrete segments for objects with well-defined shapes and an amorphous segment for amorphous background areas. However, rather than bringing together the earlier projects, this endeavor produced unique, specialized panoptic structures (see Figure 1a).
Recent developments in panoptic topologies like K-Net, MaskFormer, and Mask2Former have changed the study focus to integrating picture segmentation. With such panoptic architectures, it is possible to train them for all three jobs and achieve great performance without altering the design. To perform at their best, however, they must get individualized training for each duty (see Figure 1b). The individual training policy generates unique sets of model weights for each task while requiring more training time. They can only be viewed as a semi-universal strategy in that sense.
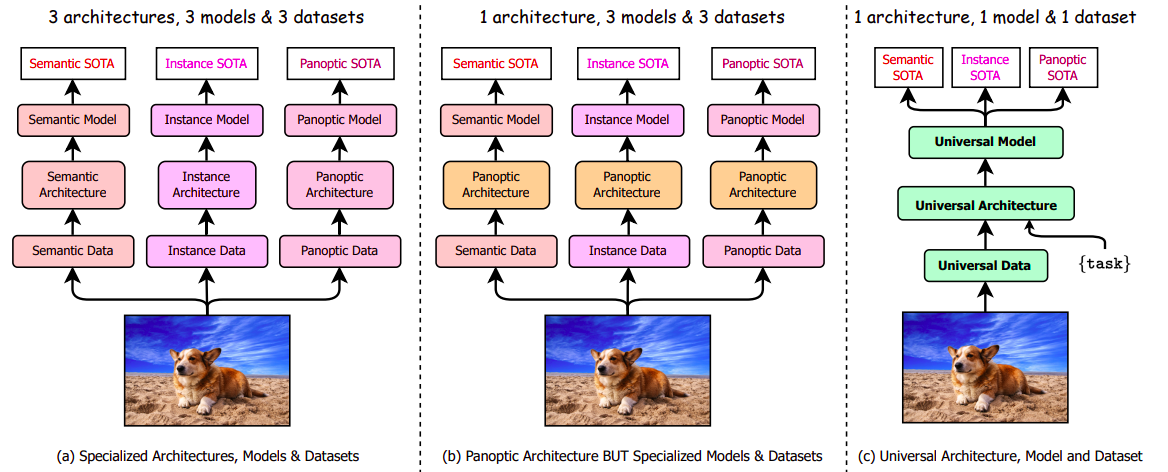
They suggest a multi-task universal image segmentation framework (OneFormer) to completely unify image segmentation, which outperforms the current state-of-the-art on all three image segmentation tasks (see Figure 1c) by just training once on a single panoptic dataset. For instance, to get the highest performance for the semantic, instance, and panoptic segmentation tasks, Mask2Former is prepared for 160K iterations on ADE20K. This results in 480K iterations in training and three models to store and host for inference. They hope to address the following issues through this work: (i) Why do existing panoptic architectures fail to complete all three tasks with a single training procedure or model?
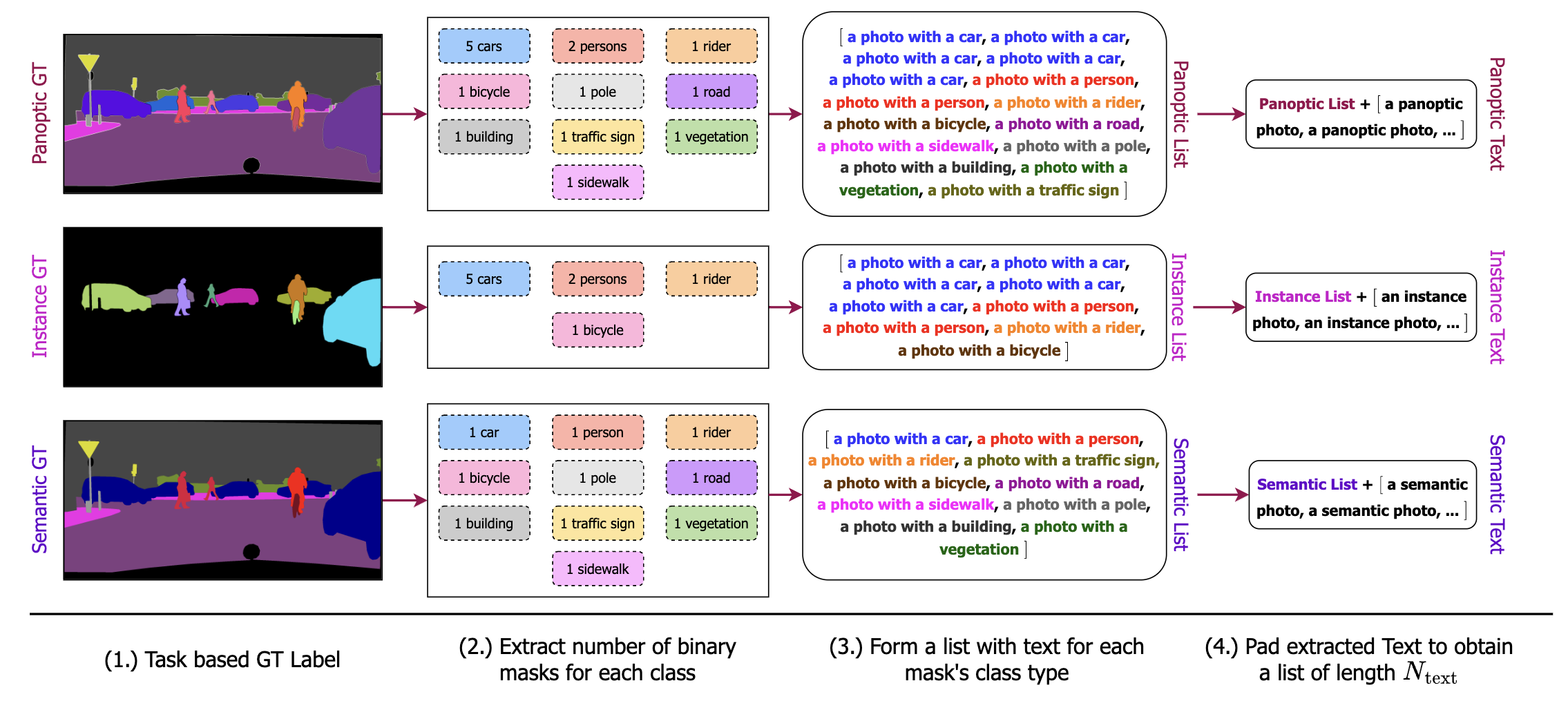
They postulate that because current approaches lack task guidance in their designs, they must train separately for each segmentation job, making it difficult to understand the distinctions across inter-task domains when trained jointly or with a single model. To address this issue, they add a task input token in the text, “the task is a task,” which forces the model to depend on the job at hand. To ensure their model is objective in tasks, they uniformly sample “task” from “panoptic, instance, semantic” and the related ground truth during their joint training procedure. As a result, their architecture is task-guided for training and task-dynamic for inference using just one model.
They generate the semantic and instance labels from the matching panoptic annotations during training because they are driven by panoptic data’s capacity to capture both semantic and model information. They, therefore, require panoptic data during training. Additionally, they reduce training time and storage needs by up to 3, making picture segmentation less resource-intensive and more available. Their combined training time, model parameters, and FLOPs are equivalent to those of the current approaches. (ii) How can the single joint training method help the multi-task model learn inter-task and inter-class differences more effectively?
They design their framework as a transformer-based method, which query tokens may direct, in response to the recent success of transformer frameworks in computer vision. They initialize their queries as repetitions of the task token (obtained from the task input) to add task-specific context to their model. Then they compute a query-text contrastive loss using the text derived from the corresponding ground-truth label for the sampled task. According to their hypothesis, a contrastive loss on the queries aids in guiding the model to become more task-sensitive. Additionally, it lessens incorrect category predictions. They test OneFormer on three significant segmentation datasets, each with all three segmentation tasks: ADE20K, Cityscapes, and COCO.
By using a single jointly trained model for all three tasks, OneFormer establishes a new standard. To sum up, they have mostly contributed:
- They suggest OneFormer, the first multi-task universal image segmentation framework based on transformers, to outperform existing frameworks across semantic, instance, and panoptic segmentation tasks, despite the latter needing to be trained separately on each job using multiple times of resources. OneFormer can be trained only once with a single universal architecture, model, and dataset. To train its multi-task model,
- OneFormer employs a task-conditioned joint training technique, uniformly sampling several ground truth domains (semantic, instance, or panoptic).
- They validate OneFormer through rigorous tests on three key benchmarks: ADE20K, Cityscapes, and COCO. As a result, OneFormer truly accomplishes the original unifying aim of panoptic segmentation. Compared to traditional Swin-L backbone methods, OneFormer sets a new benchmark for segmentation performance on all three tasks. It gets even better with the new ConvNeXt and DiNAT backbones.
Check out the paper, project, and code. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.