Open AI’s ‘Critique-Writing’ Model To Describe Flaws In Summaries Can Be Used To Scale The Supervision Of Machine Learning Systems To Tasks That Are Difficult For Humans To Evaluate Directly

Future AI systems that accomplish extremely complex jobs will be guided by human purpose. Models may then learn to provide outputs that appear suitable to humans but contain faults overlooked. On the other hand, humans have difficulty appraising tough jobs, such as finding every problem in a codebase or every factual error in a lengthy essay. Several prior efforts to align language models have used human evaluations as a training signal.
It takes a lot of effort to read a whole book, but humans who are given chapter summaries have an easier time analyzing a book summary. To address this issue, researchers intend to teach AI assistants to assist people in providing feedback on complex jobs. These assistants should point out faults, explain what’s going on, and answer questions from people.
Researchers gathered their dataset of over 6,000 subject inquiries and summaries on over 2,000 different texts as proof of concept. The sections are drawn from a database of short stories, Wikipedia articles, and web articles (mainly news) gathered from the internet. When encoded using the GPT-2 tokenizer, most jobs were generated from short texts with less than 2,048 characters. They also gathered some non-training challenges based on texts with up to 4,096 tokens. These models will aid human assessors and will be used to investigate the scaling features of critique writing.
Experiments with the help of artificial intelligence

Free-2 Min AI NewsletterJoin 500,000+ AI Folks
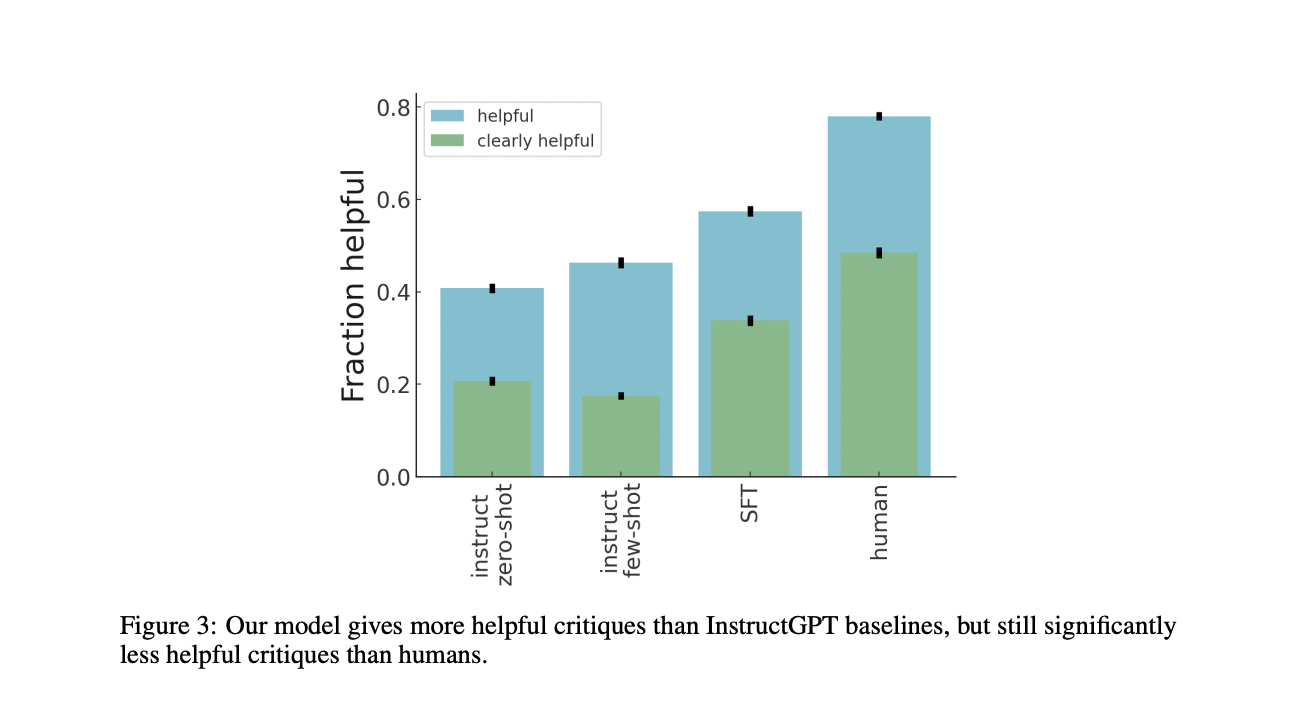
They show labels eight model-written criticisms of each summary, with a control group that receives no aid, to assess how valuable models are for evaluation assistance. They use topic-based outlines from three different sources: written by their models, humans, and people with significant but minor faults.

Researchers also discovered that, unlike tiny models, huge models could directly enhance their outputs by applying self-critiques. Models who receive better criticisms make more progress than those who receive poor critiques or none.
Do models share everything they know with us?
Researchers want models to communicate any problems they “know about” to provide the best evaluation support on challenging assignments. Can a model give an honest critique that people comprehend whenever it accurately predicts that a response is incorrect?
This is especially crucial when supervising models that may try to deceive human supervisors or hide facts. They want to train equally intelligent help models to identify what humans miss.
Unfortunately, researchers discovered that models are better at discriminating than analyzing their responses, implying that they are aware of some issues that they are unable or unwilling to communicate. Furthermore, for larger models, the difference between discriminating and critique abilities did not appear to be narrow. For the alignment research, closing this gap is a principal focus.
Topic-based summarization is the base task that is identical to or interchangeable with query-based and question-focused summarization. Instead of attempting to summarize the entire text, topic-based summarization focuses on a particular aspect of the text.
Steps to take next
A significant disadvantage of this study is that topic-based summarization is not a difficult task: humans comprehend it well and can evaluate a summary in around 10 minutes. They deal with jobs that are far more difficult for humans to assess to better grasp the boundaries of AI-assisted evaluation.
Nonetheless, these findings give us hope that they may be able to train models to provide people with user input. Starting with the work on discussion and recursive reward modeling is a fundamental pillar of the alignment method. In the long run, researchers hope to create assistants that can be trusted to perform all of the cognitive work associated with evaluation, allowing humans to focus on communicating their preferences.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Self-critiquing models for assisting human evaluators'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper, dataset and blog post. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.