OpenAI Announce a New Embedding Model Which is Significantly More Capable, Cost-Effective, and Simpler to Use
Embeddings are representations of concepts in the form of sequences of numbers, which facilitates the computer’s ability to grasp the connections between those concepts. Embeddings form a vector (list) of real or complex integers with floating-point arithmetic. How closely two vectors are linked is quantified by their distance. In general, closer distances indicate a stronger relationship, while further ones indicate less of one. Embeddings are typically used for tasks like searching, clustering, recommending, detecting anomalies, measuring diversity, classifying, etc.
OpenAI has released a new embedding model that is more powerful, cheaper, and easier to implement. Compared to our previous most competent model, Davinci’s new model, text-embedding-ada-002, beats it on most tasks while costing 99.8 percent less. OpenAI provides access to seventeen different embedding models, including one from the second generation (model ID -002) and sixteen from the first generation (denoted with -001 in the model ID). For practically all purposes, text-embedding-ada-002 is OpenAI’s preferred method. It’s more convenient, inexpensive, and effective than alternatives.
If one wants an embedding, provide the text string to the embeddings API endpoint and the ID of an embedding model one would d like to use (e.g., text-embedding-ada-002). An embedding will be included in the reply; this can be copied, stored, and used later.
Some enhanced models include the following: The new embedding model is a more powerful resource for NLP and other coding-related activities. The new embedding model provides a more powerful resource for NLP and other coding-related activities. Some of the following model enhancements are listed below:
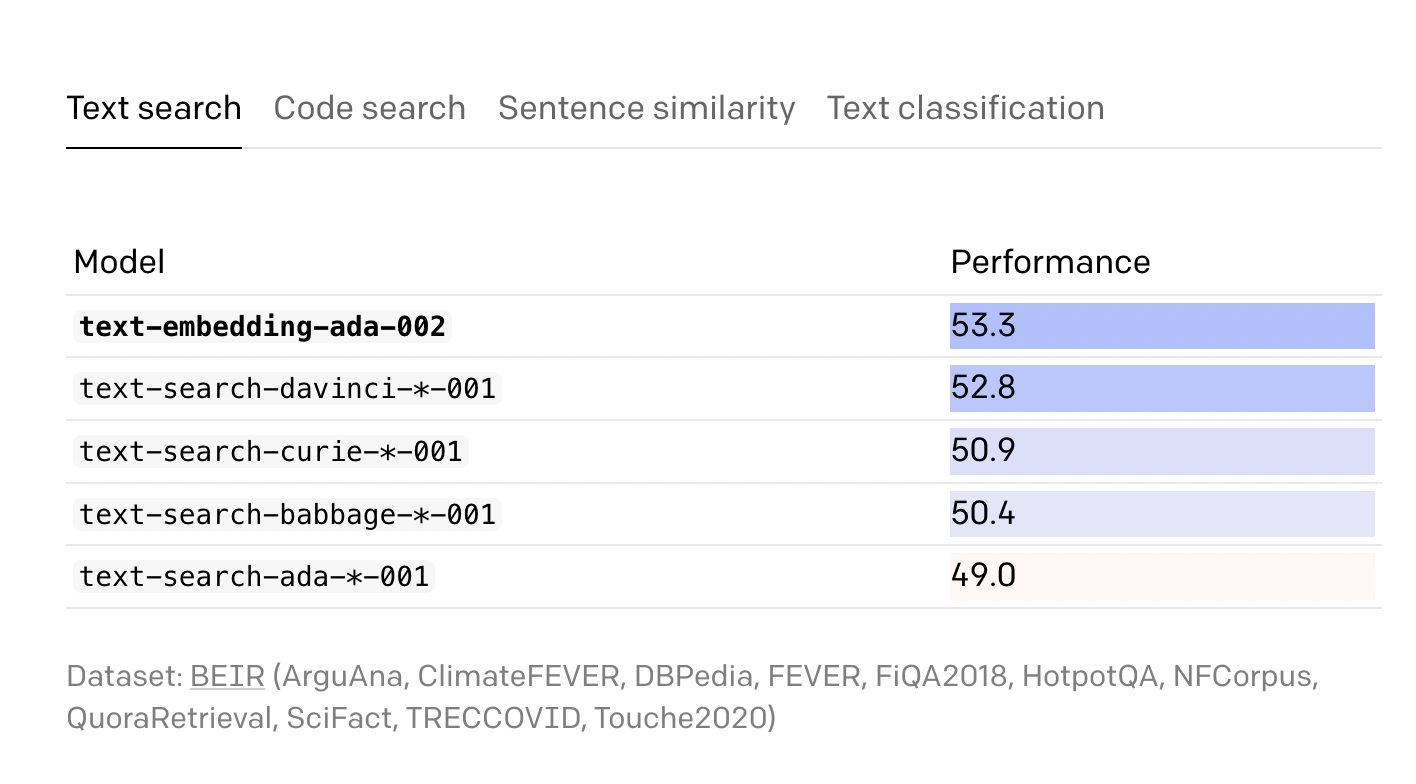
- Stronger performance – text-embedding-ada-002 reaches equivalent performance on text classification while outperforming all previous embedding models on text search, code search, and sentence similarity.
- Unification of capabilities – After combining the five models mentioned in the previous section (text-similarity, text-search-query, text-search-doc, code-search-text, and code-search-code), OpenAI has greatly simplified the /embeddings endpoint’s interface. It outperforms our prior embedding models in various text search, sentence similarity, and code search benchmarks, all with a single, unified representation.
- Longer context – The new model’s context length has been extended fourfold, from 2048 to 8192, making it much more manageable when dealing with lengthy texts.
- Smaller embedding size – The new embeddings are more efficient when dealing with vector databases while having only 1536 dimensions, which is one-eighth the size of davinci-001 embeddings.
- Reduced price – Compared to older, similarly sized models, OpenAI’s new embedding models are 90% cheaper. With the new model, one may have the same or greater performance than the previous Davinci models at a 99.8 percent reduced price.
Normalizing OpenAI embeddings to length 1 allows for the following benefits:
- Cosine similarity can be computed with simply a dot product, making the calculation somewhat faster.
- The rankings obtained using Cosine similarity and Euclidean distance are equivalent.
Limitations and Risks
- Without safeguards, the usage of embedded models will lead to undesirable outcomes due to their inherent unreliability or the societal hazards they entail. Compared to the state-of-the-art text-embedding-ada-002 model, the text-similarity-davinci-001 model performs better on the SentEval linear probing classification benchmark.
- Social biases, such as preconceptions or unfavorable feelings against particular groups, are encoded in the models.
- Mainstream English, like that accessible on the Internet, is the most useful kind of English for models to train on. Some local or group dialects may need to do better with our models.
- Events after August 2020 are not accounted for in the models.
Check out the OpenAI Blog and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Consulting Content Writer at MarktechPost. She is a Computer Science Engineer and working as a Delivery Manager in leading global bank. She has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world.
Credit: Source link
Comments are closed.