OpenAI Releases Whisper: A New Open-Source Machine Learning Model For Multi-Lingual Automatic Speech Recognition
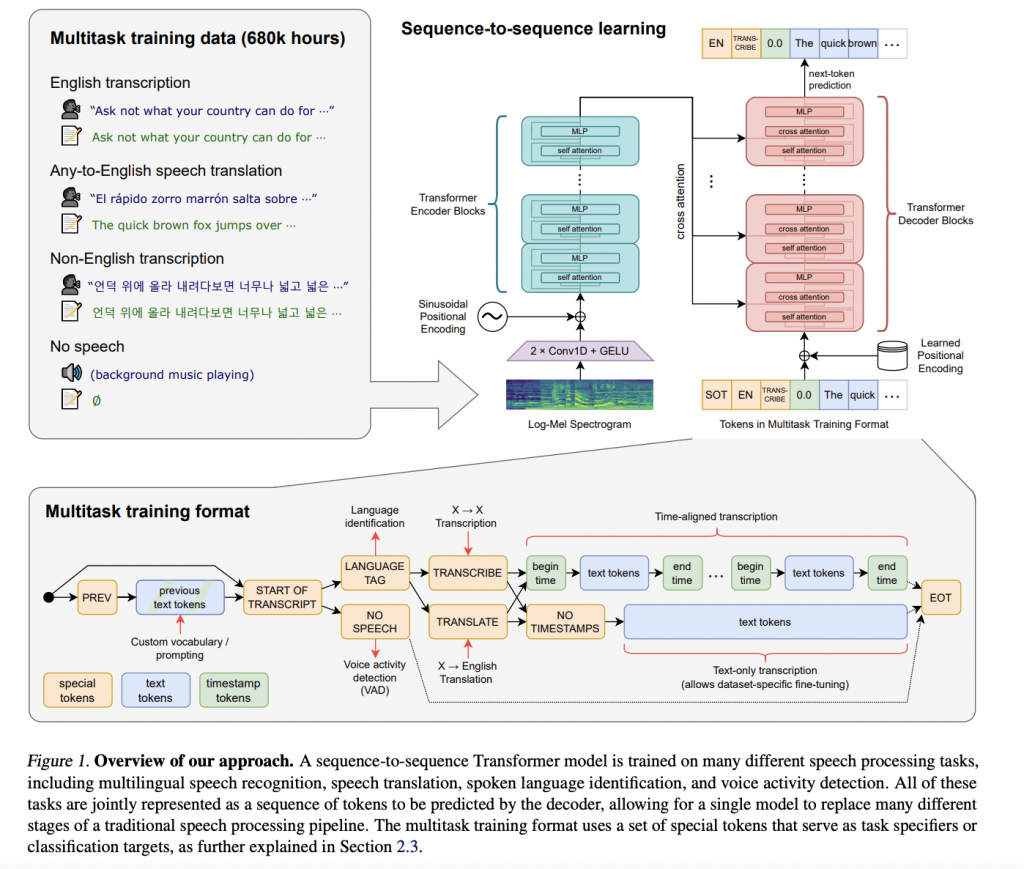
Using only an off-the-shelf transformer trained on 680,000 hours of weakly-supervised, multi-lingual audio data, OpenAI’s Whisper can approach human-level robustness and accuracy in ASR, all without the need for fine-tuning. Best of all, the model is open-source, with various weight sizes available to the public.
The model

As mentioned previously, the model is a standard encoder-decoder transformer. Audio files from various speech recognition tasks are first converted to log-mel spectrograms, which are audio representations in the time-frequency-amplitude domain, with frequencies represented in Mels, a logarithmic scale meant to mimic how pitch perception works in humans. Dimensionality reduction is then performed on the spectrograms using 1-dimensional convolution with GELU.
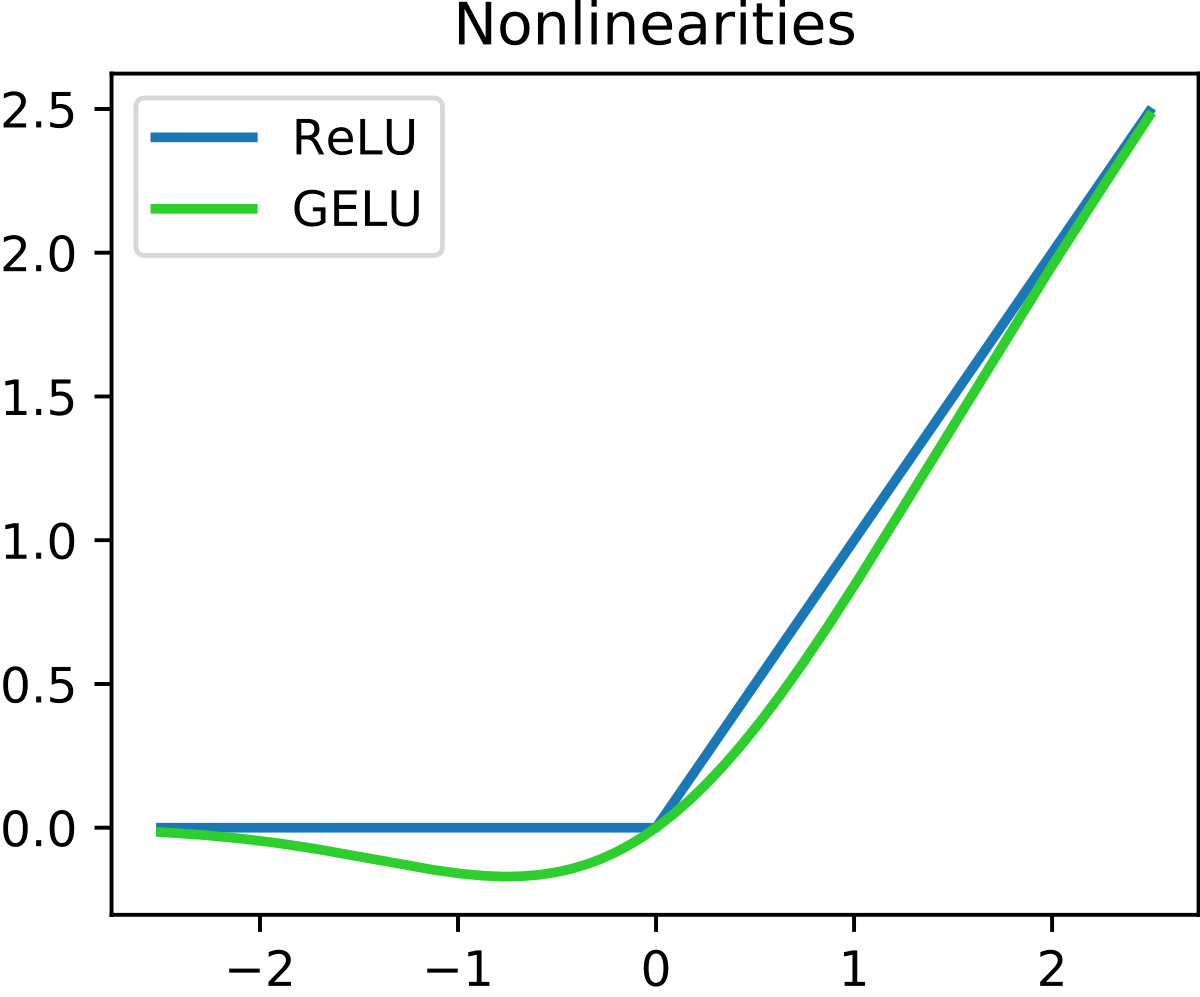

GELU (What?)
Inputs are always normalized to 0 mean and unit variance so that different features are scaled evenly, making the loss landscape more uniform. While ReLU’s dropout is applied ∀x<0, GELU performs dropout stochastically, increasing the likelihood of input being dropped as x decreases.
After performing positional encoding, the input is fed to the transformer encoder stack, and the resulting representation is used to condition the autoregressive decoder. Unique tokens are used at the start of the decoding process to indicate the start-end of a task, task type, whether speech is present in the input or not, timestamp information, and more.
As greedy decoding is used to sample outputs, the authors use several heuristics to prevent repetition looping, like starting from temperature 0 and gradually increasing it if the entropy of the generated tokens is too low (someone should tell them about typical sampling).
The data
Since human-validated, supervised speech recognition and translation data is scarce, the authors decided to scavenge for any ASR data they could find, focusing on data pre-processing techniques. These included heuristics to identify and remove machine-generated translations, such as the lack of punctuation or usage of all-caps. Researchers also used a language detector to ensure a match between transcript and audio language. They trained an initial model on the data to indentify and manually inspect data points with a high error rate to exclude potential outliers. The data totaled 680.000 hours, two orders larger than previous supervised ASR datasets. This dataset was not made public despite releasing the model weights and code.
Evaluation
The authors take issue with the word-error rate (WER) metric, which penalizes any difference between model output and ground truth. Some of these differences may only be stylistic: what we care about is semantic errors. The authors developed several dictionaries to standardize word choice and thus decrease WER.

Another metric used to evaluate the model is effective robustness. Robustness measures how well the model generalizes to out-of-distribution datasets: effective robustness is robustness relative to another model. When Whisper is compared to wav2vec, we find Whisper has higher effective robustness, making 55% fewer errors on average than wav2vec.

The authors hypothesize that WER halves for every 16x increase in training data in terms of scaling laws. If this were true, we should expect to reach super-human performance for ASR in the next generation of models. However, this trend does not hold for all languages: non-Indo-European languages usually fare worse, with Welsh (CY) also being an outlier, despite supposedly being trained on 9,000 hours of translation data.

As for scaling model parameters, we see diminishing returns as WER approaches human SR levels.

Conclusion
OpenAI’s Whisper is an off-the-shelf transformer that leverages massive data and decoding heuristics to reach human-level speech recognition and translation. It remains to be seen whether future ASR models will surpass human performance in the coming years.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Robust Speech Recognition via Large-Scale Weak Supervision'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Martino Russi is a ML engineer who holds a master’s degree in AI from the University of Sussex. He has a keen interest for reinforcement learning, computer vision and human-computer interaction. He is currently researching unsupervised reinforcement learning and developing low-cost, high-dimensional control interfaces for robotics
Credit: Source link
Comments are closed.