OpenAI Researchers Built An Efficient Framework For Language Models To Complete Middle Blanks In A Document
Suppose we have an incomplete code, and we want our coding assistant to fill that automatically, or we have thought of the start and end of a document and cannot think of useful things to write in the middle of the document. The state-of-the-art frameworks available for language models cannot effectively do that, although they are pretty good at completing the prompt. The researchers at OpenAI have demonstrated a way to enable language models to infill texts in the middle (FIM – Fill in the middle) by modifying the existing frameworks.
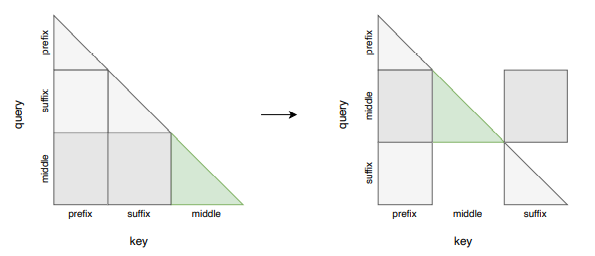
Current state-of-the-art frameworks like GPT-3, LaMDA are based on an encoder and a decoder. They generate the subsequent texts based on the probabilities of generating previous texts (Auto-regressive structure). However, a slight change in their training procedure would enable them to infill texts in the middle. The procedure is to apply a transformation in some parts of the dataset without modifying the model architecture. The transformation is such that the document is cut into three pieces randomly, and the middle piece is removed and appended at the end. If a document has three parts: {prefix, middle, suffix}, then it becomes like {prefix, suffix, middle}, that probability of generating middle not only depends on probabilities of prefix elements but also on the suffix elements too. Then the mixture of this transformed data and the rest of the original data is passed through the same previously used model architectures.
They have examined both code and language-generating cases. First, they demonstrated that training with the mixture does not harm the model’s previous capabilities, like generating texts from left to the right. If the model is not pre-trained using the mixture, the FIM capability can also be learned by fine-tuning existing pre-trained model. However, they have shown that fine-tuning is more computationally expensive than pre-training with FIM. Because while encoding through the transformer, it imposes a different attention pattern throughout the document. Although the document is broken into three pieces and rearranged, the total number of tokens to be made are same as in the previous auto-regressive structures. However, the different encoded pattern learned during pre-training with the mixture is difficult to achieve by fine-tuning a pre-trained regular AR model.

This framework is evaluated by measuring how much information gain happens by evaluating the probability of generating middle tokens conditioned by only prefix and prefix as well as suffix tokens. The evaluation is made by masking a span of the document randomly and predicting the values in the span.
They have created a different version of this approach, namely SPM, which is swapping the prefix and suffix so that it becomes like {suffix, prefix, middle}. This advantage is that the prefix also validates key-value pairs computed by suffix. They have tested by applying both transformations with 50% probabilities each.
In conclusion, they have shown that training the previous auto-regressive models with the mixture data can efficiently infill the middle parts of documents and codes without harming their previous capabilities of generating texts from left to right. However, this has several limitations which can be improved by later research. Like they have applied the transformation uniformly, which can be improved by language-specific transformations. It is also currently ambiguous to infill texts sensibly, which can be later improved by adding a reinforcement learning approach where several feedbacks would control generation.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Efficient Training of Language Models to Fill in the Middle'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.