Peeking Inside Pandora’s Box: Unveiling the Hidden Complexities of Language Model Datasets with ‘What’s in My Big Data’? (WIMBD)

Machine learning relies on data as its building block. New datasets are a key factor in research and the development of innovative models since they propel advancements in the field. The training of larger models on larger datasets has resulted in a significant rise in the computing cost of AI experiments over time. Currently, some of the most influential datasets are produced by extracting text from the whole publicly accessible internet. Some of the biggest databases ever constructed are usually introduced with no documentation of their contents, only an explanation of how they were generated.
This is a crucial distinction since models are currently being trained on large text corpora without any knowledge of the concepts, subjects, toxicity, or private information that may be included. In the meanwhile, language models are now widely utilized daily by individuals all around the world. Since these AI systems have a direct influence on people’s lives, it is now critical to comprehend both their advantages and disadvantages. Models can only learn from the data they were trained on, but the enormous quantity and lack of public availability of pretraining corpora make it difficult to analyze them. A handful of significant dimensions are usually the focus of work assessing the contents of web-scale corpora, and crucially, more work needs to be done analyzing several datasets along the same dimensions.
As a result, before deciding which dataset or datasets to employ, machine learning practitioners need more useful methods for describing distinctions between them. In this study, researchers from the Allen Institute for AI, the University of Washington and the University of California propose to use a collection of tools called WIMBD: WHAT’S IN MY BIG DATA, which helps practitioners rapidly examine massive language datasets to research the content of large text corpora. Additionally, they use this technology to offer some of the first directly comparable measures across several web-scale datasets.
There are two parts to WIMBD: (1) an Elasticsearch (ES) index-based search tool that allows programmatic access to look for documents that contain a query. ES is a search engine that makes it possible to find strings inside a corpus together with the texts in which they occurred and how many times. (2) A MapReduce-built count capability that enables rapid iteration across a whole dataset and the extraction of pertinent data, such as the distribution of document character lengths, duplicates, domain counts, the identification of personally identifiable information (PII), and more. The code for WIMBD is open source and accessible at github.com/allenai/wimbd. It is extensible and may be used to index, count, and analyze different corpora at a large scale. They conducted sixteen studies on 10 distinct corpora including C4, The Pile, and RedPajama that are utilized to train language models using these techniques.
They classify their analyses into four categories:
- Data statistics (e.g., number of tokens and domain distribution).
- Data quality (e.g., measuring duplicate documents and most frequent n-grams).
- Community- and society-relevant measurements (e.g., benchmark contamination and personally identifiable information detection).
- Cross-corpora analysis (e.g., verifying document overlap and comparing the most common n-gram).
Figure 1 is a representation of WIMBD. Numerous insights on data distribution and anomalies are presented in their work.
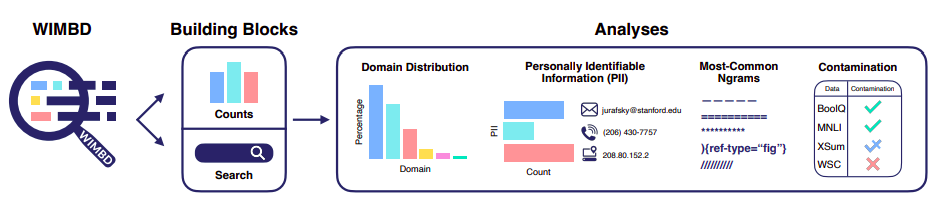
Figure 1: WIMBD overview. They provide two core functionalities, Count and Search, which facilitate rapid processing and provide access to vast text corpora, hence enabling a multitude of analysis.
Examining the distribution of document lengths, for instance, reveals anomalies where some lengths are overrepresented in comparison to nearby lengths; these abnormalities frequently relate to text that is created from templates almost exactly twice or documents that have been intentionally cut to a certain character length. Another example would be punctuation sequences, often the most common n-grams. For instance, in The Pile, the most common 10-gram is a dash (‘-‘) repeated ten times. WIMBD provides practical insights for curating higher-quality corpora, as well as retroactive documentation and anchoring of model behaviour to their training data. Wimbd.apps.allenai.org has an interactive demo highlighting some of their analysis and is released in conjunction with this publication.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.