Peking University Researchers Introduce FastServe: A Distributed Inference Serving System For Large Language Models LLMs
Large language model (LLM) improvements create opportunities in various fields and inspire a new wave of interactive AI applications. The most noteworthy one is ChatGPT, which enables people to communicate informally with an AI agent to resolve problems ranging from software engineering to language translation. ChatGPT is one of the fastest-growing programs in history, thanks to its remarkable capabilities. Many companies follow the trend of releasing LLMs and ChatGPT-like products, including Microsoft’s New Bing, Google’s Bard, Meta’s LLaMa, Stanford’s Alpaca, Databricks’ Dolly, and UC Berkeley’s Vicuna.
LLM inference differs from another deep neural network (DNN) model inference, such as ResNet, because it has special traits. Interactive AI applications built on LLMs must provide inferences to function. These apps’ interactive design necessitates quick job completion times (JCT) for LLM inference to deliver engaging user experiences. For instance, consumers anticipate an immediate response when they submit data into ChatGPT. However, the inference serving infrastructure is under great strain due to the number and complexity of LLMs. Businesses set up pricey clusters with accelerators like GPUs and TPUs to handle LLM inference operations.
DNN inference jobs are often deterministic and highly predictable, i.e., the model and the hardware largely determine the inference job’s execution time. For instance, the execution time of various input photos varies a little while using the same ResNet model on a certain GPU. LLM inference positions, in contrast, have a unique autoregressive pattern. The LLM inference work goes through several rounds. Each iteration produces one output token, which is then added to the input to make the subsequent token in the following iteration. The output length, which is unknown at the outset, affects both the execution time and input length. Most deterministic model inference tasks, like those performed by ResNet, are catered for by existing inference serving systems like Clockwork and Shepherd.
They base their scheduling decisions on precise execution time profiling, which is ineffective for LLM inference with variable execution times. The most advanced method for LLM inference is Orca. It suggests iteration-level scheduling, allowing for adding new jobs to or deleting completed jobs from the current processing batch after each iteration. However, it processes inference jobs using first-come, first-served (FCFS). A scheduled task runs continuously until it is completed. The processing batch cannot be increased with an arbitrary number of incoming functions due to the restricted GPU memory capacity and the low JCT requirements of inference jobs. Head-of-line blocking in run-to-completion processing is well known.
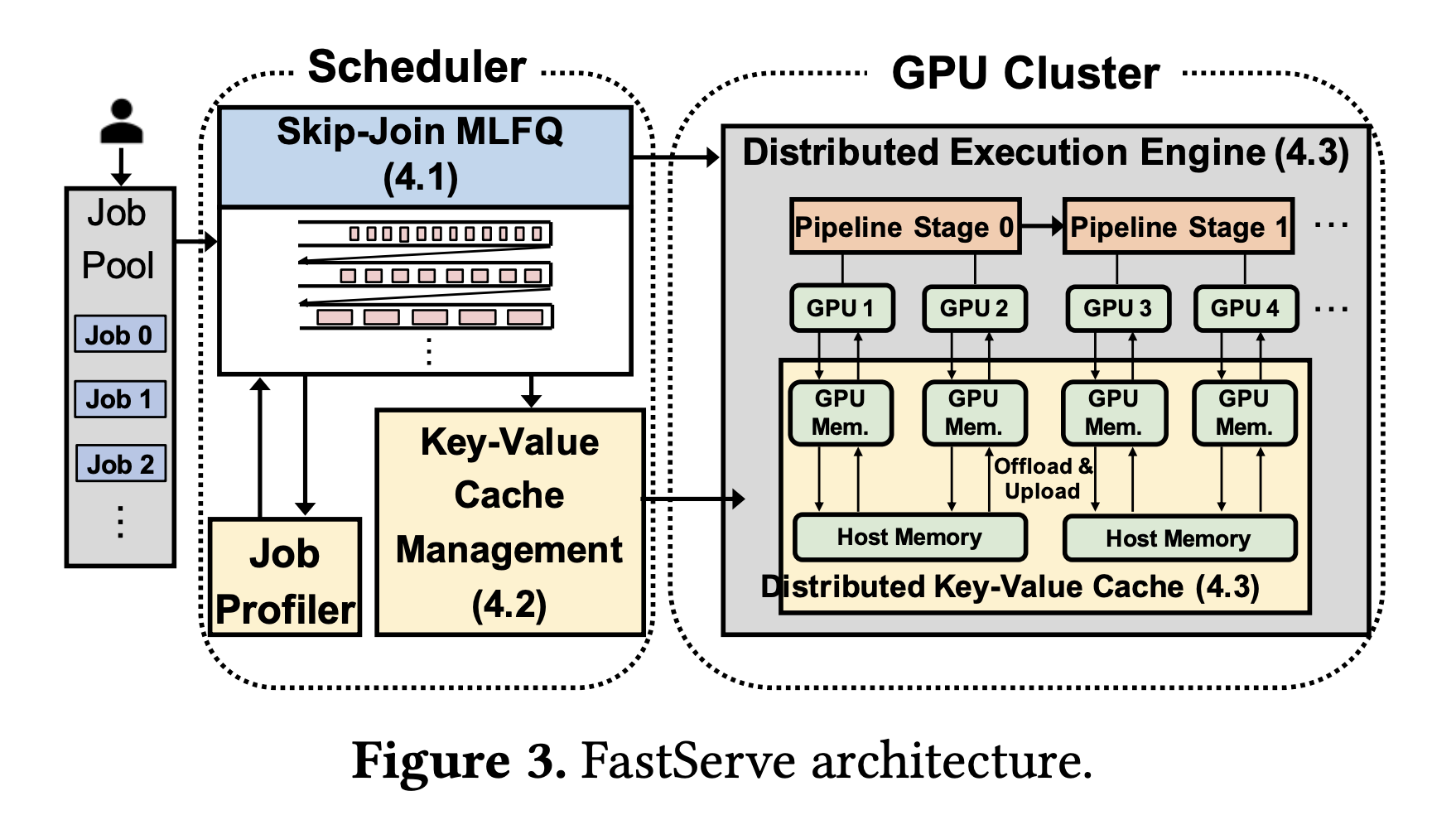
Because LLMs are vast in size and take a long time to execute in absolute terms, the issue is particularly severe for LLM inference operations. Large LLM inference jobs, especially those with lengthy output lengths, would take a long time to complete and obstruct subsequent short jobs. Researchers from Peking University developed a distributed inference serving solution for LLMs called FastServe. To enable preemption at the level of each output token, FastServe uses iteration-level scheduling and the autoregressive pattern of LLM inference. FastServe can choose whether to continue a scheduled task after it has generated an output token or to preempt it with another job in the queue. This enables FastServe to reduce JCT and head-of-line blocking via preemptive scheduling.
A unique skip-join Multi-Level Feedback Queue (MLFQ) scheduler serves as the foundation of FastServe. MLFQ is a well-known method for minimizing average JCT in information-free environments. Each work starts in the highest priority queue, and if it doesn’t finish within a certain time, it gets demoted to the next priority queue. LLM inference is semi-information agnostic, meaning that while the output length is not known a priori, the input length is known. This is the main distinction between LLM inference and the conventional situation. The input length determines the execution time to create the initial output token, which might take much longer than those of the following tokens because of the autoregressive pattern of LLM inference.
The initial output token’s execution time takes up most of the work when the input is lengthy and the output is brief. They use this quality to add skip-join to the traditional MLFQ. Each arrival task joins an appropriate queue by comparing the execution time of the first output token with the demotion thresholds of the lines, as opposed to always entering the highest priority queue. The higher priority queues than the joined queue are bypassed to minimize downgrades. Preemptive scheduling with MLFQ adds additional memory overhead to keep begun but incomplete jobs in an interim state. LLMs maintain a key-value cache for each Transformer layer to store the intermediate state. As long as the batch size is not exceeded, the FCFS cache needs to store the scheduled jobs’ intermediate states. However, additional jobs may have begun in MLFQ, but they are relegated to queues with lesser priorities. All begun but incomplete jobs in MLFQ must have the interim state maintained by the cache. Given the size of LLMs and the restricted memory space of GPUs, the cache may overflow. When the cache is full, the scheduler naively can delay initiating new jobs, but this once more creates head-of-line blocking.
Instead, they develop a productive GPU memory management system that proactively uploads the state of processes in low-priority queues when they are scheduled and offloads the state when the cache is almost full. To increase efficiency, they employ pipelining and asynchronous memory operations. FastServe uses parallelization techniques like tensor and pipeline parallelism to provide distributed inference serving with many GPUs for huge models that do not fit in one GPU. To reduce pipeline bubbles, the scheduler performs numerous batches of jobs concurrently. A distributed key-value cache is organized by the key-value cache manager, which also distributes the management of memory swapping between GPU and host memory. They put into practice a FastServe system prototype based on NVIDIA FasterTransformer.The results reveal that FastServe enhances the average and tail JCT by up to 5.1 and 6.4, respectively, compared to the cutting-edge solution Orca.
Check out the Paper. Don’t forget to join our 21k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
🚀 Check Out 100’s AI Tools in AI Tools Club
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.