Privacy-Preserving Machine Learning For Decoding Clinical Jargon
Many patients today may view their medical history online, from lab results to clinician notes. Unfortunately, clinical notes are difficult to decipher due to the jargon and acronyms used by professionals. There are hundreds of such acronyms, many of which are unique to certain fields of medicine or geographical areas or have more than one possible meaning. Many acronyms and abbreviations are used in the medical field, and it can be difficult for patients to make sense of them all. Multiple interpretations can be resolved by looking at the sentence’s whole context.
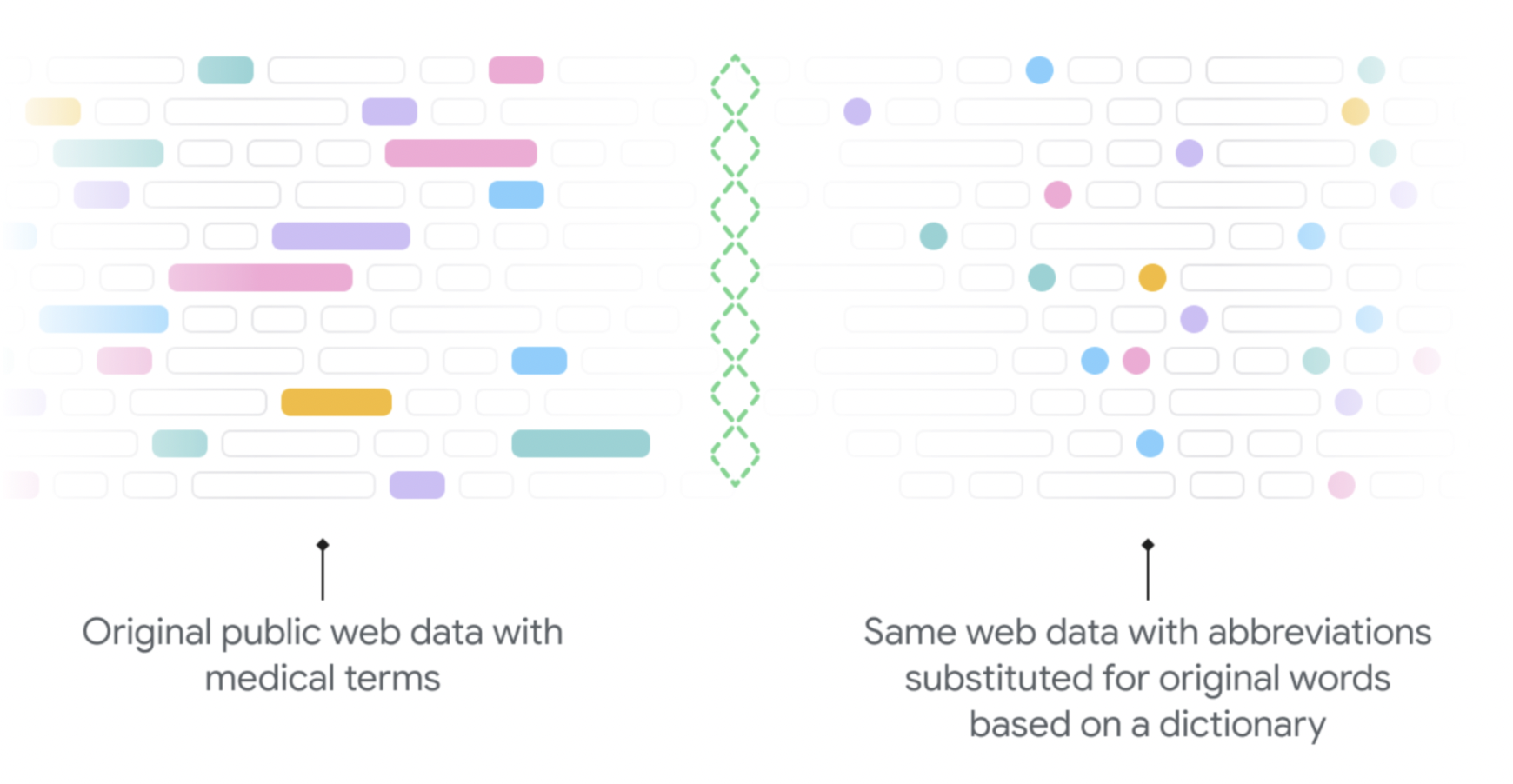
Researchers developed a novel inference method and a method for algorithmically re-writing large amounts of internet text to make it appear as if it were written by a doctor (web-scale reverse substitution) to enable the model to generalize from web data to notes (called elicitive inference). The model was constructed using only publicly available, non-patient-specific data from the web (i.e., no potentially sensitive data).
There is a lot of jargon and abbreviations in the notes of patients’ medical records, making it difficult for patients to understand what is being said. Recent research found that only 62% of patients understood ten common medical abbreviations, but that understanding increased to 95% after the abbreviations were expanded. It is difficult for clinicians to understand clinical notes due to specialty-specific and regional jargon. The research found that local GPs often misunderstood six commonly used acronyms in hospital discharge summaries, and there is evidence that these misunderstandings can lead to medical harm. While most doctors would rather see a discharge summary without abbreviations, one study found that even just 100 discharge summaries from hospitals contained as many as 750. Given recent US legislation requiring universal electronic sharing of clinical notes, it is crucial that the more than 50 million patients who already have access to their medical records find this information both understandable and useful.
Several machine learning methods, such as naive Bayes, support vector machines, profile-based approaches, algorithms based on hyperdimensional computing, convolutional neural networks, long short-term memory networks, encoder-based transformers (e.g., clinicalBERT), latent meaning cells, and decoder-based transformers, have been created to disambiguate abbreviations in clinical text. The real extension of a recognized abbreviation from all of its potential senses was predicted in a recent study. The authors trained the algorithm by replacing each lengthy form with its corresponding abbreviation in anonymized clinical notes. The modified text serves as the input, while the original string serves as the label.
Methods
Fine-tuning dataset generation with WSRS
Due to the nature of the pre-training corpus’s source material websites that don’t often have instances of abbreviations in the clinical text, researchers developed an algorithm to generate sample snippets from the online corpus that included clinical terminology. From a high level, researchers systematically replaced expansion phrases from the public web with their abbreviations using the dictionary (explained below) that comprised expansions (sometimes referred to as long forms or senses), such as atrial fibrillation: AF.
Model fine-tuning
In this research, researchers employ Text-to-Text Transfer Transformers (T5), a class of encoding-decoding models that aims to transform one form of text into another. T5 11B and a T5 80B variation were tested, along with T5 small (60M) and T5 big (770M). For primary outcomes, researchers employ the T5 80B. All models were pre-trained on the MLM loss on a web corpus before deployment. The researchers employed the same 250,000 wordpieces40 used by MT5 and used byte fallback for 101 different languages.
Model Inference
Researchers use a beam-search size of 2 for the model inference. In this research, researchers provide three model inference methods.
- In conventional inference, the source text is fed into a model, and the model returns a result.
- During iterative inference, the model is repeatedly given the original text. If the model produces a result different from the input text, that result is used to train the model once more. The output is delivered once the model’s output is identical to the input text.
- To make eliciting inference, researchers feed the model the input text while it is set to use beam search. The model’s output is used once more as input, much like in iterative inference, until the best beam remains unaltered from the original information.
Challenges
- No clinical corpus of original and “translated” text fragments exists in which abbreviations are systematically disambiguated, suggesting that disambiguating clinical abbreviations may be viewed as a type of translation. While expensive or inaccurate labeling approaches allow certain automated machine-learning systems to get around the lack of training data.
- These systems’ dependence on anonymized medical training data and the privacy issues raised by their use. Federated learning is one approach to avoiding the central gathering of big sensitive information. Still, it requires data preparation to ensure comparable data structures across locations, which is not commonly available in electronic health record systems.
- Comprehensive disambiguation of clinical abbreviations entails a significant number of discrete activities and, as a result, typically calls for sophisticated multi-model systems. Before now, state-of-the-art abbreviation detection models were trained independently from expansion models, and state-of-the-art abbreviation expansion models were trained separately for each ambiguous abbreviation.
The work of abbreviation disambiguation has been modeled by researchers as a translation effort, in which one snippet containing abbreviations is converted into another containing the same information but with the abbreviations extended. This is in contrast to more conventional methods, which include treating abbreviations as independent entities and having an abbreviation-specific model generate the possible extension from a small pool of dictionary entries. Take the quote: “This is a 45-year-old male pt with chronic lbp who failed pt” as an example. The abbreviation “pt” can mean either “patient” or “physical therapy” depending on the context. An exogenous (e.g., human) identification of the position of each form and two independent inference runs for each location would be necessary for a model trained to disambiguate the abbreviation “pt” using conventional methods. Since the method handles abbreviation identification internally, only the input snippet is needed. The self-attention mechanism in the model uses the contextual representation of each word to broaden the snippet as a whole. To clarify the second use of “pt” as physical therapy, it is helpful to know that “lbp” means “low back pain.” In addition, whereas “yo,” “m,” and “lbp” would generally require separate models, the approach can recognize and expand all of these abbreviations concurrently.
Limitations
- Additional computational overhead in the form of numerous consecutive rounds of model inference is introduced by the elicitive inference employed to retain high abbreviation detection recall.
- In contrast to previous high-performing language models in the literature, such as decoder-only models, models are not compared.
- Multiple characteristics, including general literacy, health literacy, and, in the case of physicians, specialty, are likely to influence how individuals perform on the task. Although the laypeople used in the human evaluation study don’t have a representative sample of the general population’s education or healthcare knowledge, their familiarity with internet search engines gives a good estimate of how many abbreviations can be understood with online searching.
- When a system arbitrarily creates sequences of output values, it opens itself up to certain dangers. Previous techniques of abbreviation disambiguation are immune to these dangers since models are only applied to some abbreviations, and expansions are picked from predetermined lists.
To sum it up –
Large language models (LLMs) have several potential applications for improving patients’ health literacy by enhancing the visual and textual materials at their disposal. This makes it difficult to apply these models in an “out-of-the-box” manner, as most LLMs are trained on data that does not resemble clinical note data. Scholarly work has shown how this barrier can be breached. The model also “normalizes” data from clinical notes, opening the door for more ML capabilities to make the text more accessible to patients of varying educational and health-literacy levels.
Check out the Paper and Google Blog. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.