RA-ISF: An Artificial Intelligence Framework Designed to Enhance Retrieval Augmentation Effects and Improve Performance in Open-Domain Question Answering
Developing and refining large language models (LLMs) have marked a revolutionary stride toward machines that understand and generate human-like text. Despite their significant advances, these models grapple with the inherent challenge of their knowledge being fixed at the point of their training. This limitation confines their adaptability and restricts their ability to assimilate new, updated information post-training, posing a critical bottleneck for applications requiring up-to-the-minute data.
Current research has ventured into retrieval-augmented generation (RAG) techniques to bridge the divide between static knowledge bases and dynamic information needs. RAG methods empower models to fetch and incorporate external information, broadening their horizons beyond the original dataset. This capability is pivotal, especially in scenarios where the relevance and timeliness of information can significantly influence the accuracy and reliability of model outputs.
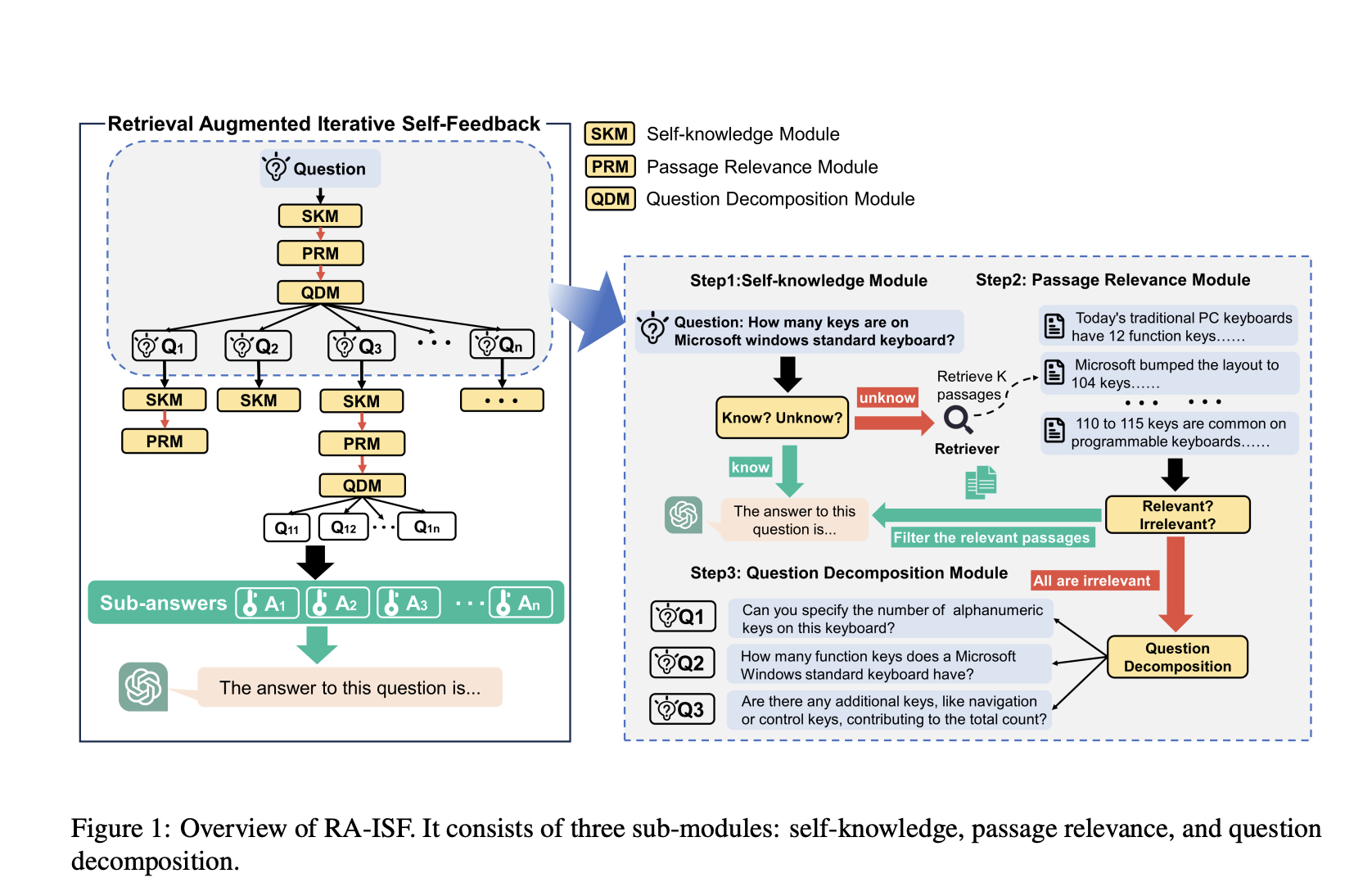
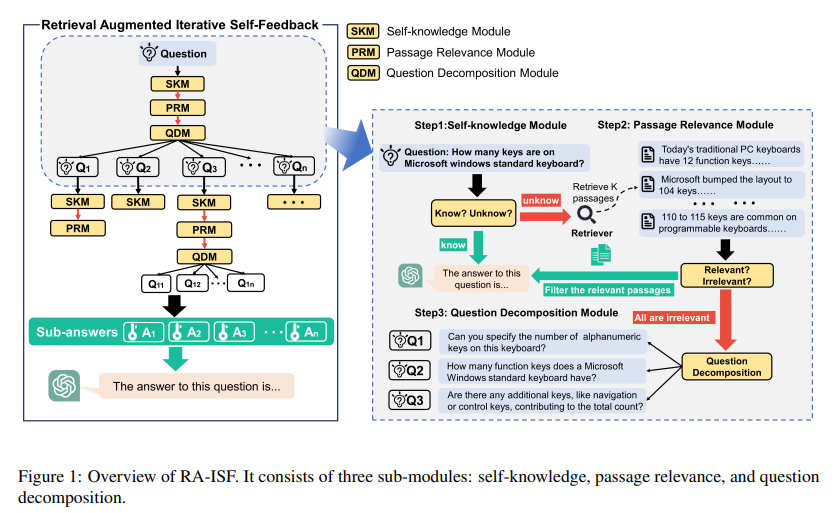
Researchers from Zhejiang University, Southeast University, and Massachusetts Institute of Technology propose the Retrieval Augmented Iterative Self-Feedback (RA-ISF) framework. RA-ISF innovates by combining the model’s internal knowledge assessment with a strategic retrieval of external data while employing an iterative feedback mechanism to refine its understanding and application of this information. The framework operates through a series of meticulously designed submodules that tackle distinct facets of the information retrieval and integration process. This includes initial self-assessment to determine a question’s answerability based on existing knowledge, followed by a relevance check of external information and, if necessary, decomposition of complex queries into more manageable sub-questions. Each of these steps is crucial for ensuring that the model accesses the most pertinent information and interprets and utilizes it correctly.
Its unique iterative self-feedback loop sets RA-ISF apart from conventional RAG methods. This loop enables the model to continuously refine its search and comprehension processes, leading to more accurate and relevant responses. Such a design amplifies the model’s ability to tackle complex queries with higher precision and significantly reduces errors and hallucinations, instances where models generate misleading or entirely fabricated information. This reduction in inaccuracies is a pivotal improvement, as it enhances the trustworthiness and reliability of the model’s outputs, making them more usable in real-world applications.
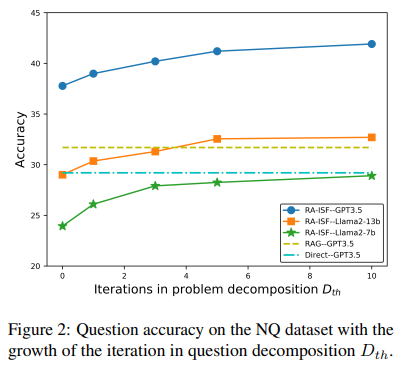
Empirical evaluations across various benchmarks and datasets underscore RA-ISF’s superior performance. By systematically enhancing the interaction between the model’s inherent knowledge base and external data sources, RA-ISF remarkably improves answering complex questions. This is evidenced by its ability to outperform existing benchmarks, showcasing its potential to redefine the capabilities of LLMs. Moreover, its success across different models, including GPT3.5 and Llama2, highlights its adaptability and robustness, further establishing its significance in the landscape of AI research. These practical results reassure RA-ISF’s potential to enhance the performance of AI systems in real-world applications.
In conclusion, RA-ISF embodies a significant stride toward resolving the long-standing challenge of integrating dynamic, external knowledge with the static data repositories of LLMs. By facilitating a more nuanced and refined approach to information retrieval and utilization, RA-ISF elevates the model’s performance and broadens its applicability across a spectrum of real-world scenarios. Its ability to iteratively refine and adjust its processes ensures that the model remains relevant and accurate, marking a paradigm shift in how the future of intelligent systems is envisioned. With its innovative structure and proven efficacy, this framework sets a new benchmark for developing more intelligent, adaptable, and reliable artificial intelligence systems.
Check out the Paper and Github. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 38k+ ML SubReddit
![]()
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.
Credit: Source link
Comments are closed.