Redefining Transformers: How Simple Feed-Forward Neural Networks Can Mimic Attention Mechanisms for Efficient Sequence-to-Sequence Tasks
Researchers from ETH Zurich analyze the efficacy of utilizing standard shallow feed-forward networks to emulate the attention mechanism in the Transformer model, a leading architecture for sequence-to-sequence tasks. Key attention mechanism elements in the Transformer are replaced with simple feed-forward networks trained through knowledge distillation. Rigorous ablation studies and experiments with various replacement network types and sizes underscore the adaptability of shallow feed-forward networks in emulating attention mechanisms, highlighting their potential to simplify complex sequence-to-sequence architectures.
The research emphasizes the adaptability of shallow feed-forward networks in replicating attention mechanisms. The study employs BLEU scores as the evaluation metric. While successfully repeating the behavior in the encoder and decoder layers, replacing the cross-attention tool poses challenges, leading to notably lower BLEU scores. The research sheds light on the limitations and potential of this approach.
The study explores the viability of replacing attention layers in the original Transformer model with shallow feed-forward networks for sequence-to-sequence tasks, particularly in language translation. Inspired by the computational overheads associated with attention mechanisms, the study investigates whether external feed-forward networks can effectively mimic their behavior. The research focuses on training these networks to substitute key attention components. It aims to assess their capability in modeling attention mechanisms and their potential as an alternative in sequence-to-sequence tasks.
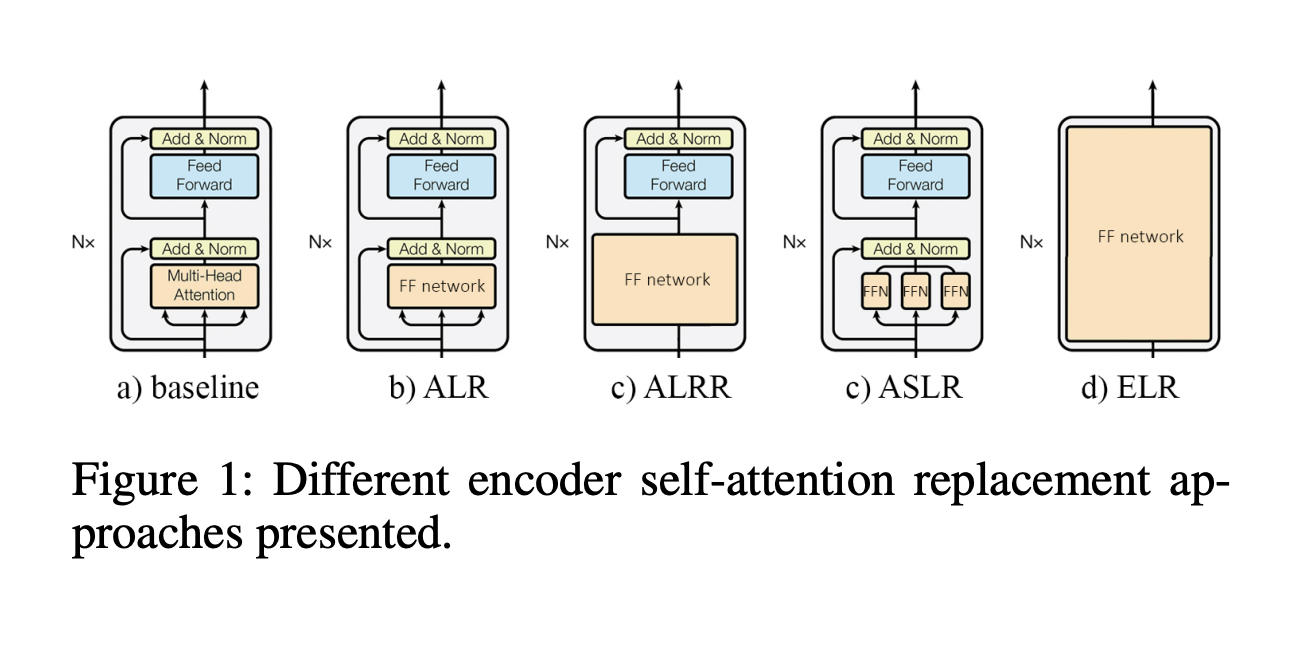
The approach employs knowledge distillation to train shallow feed-forward networks, using intermediate activations from the original Transformer model as the teacher model. A comprehensive ablation study introduces four methods for replacing the attention mechanism in the Transformer’s encoder. Evaluated on the IWSLT2017 dataset using the BLEU metric, the proposed approaches demonstrate comparable performance to the original Transformer. It provides empirical evidence and detailed implementation specifics in the appendix, establishing the effectiveness of these methods in sequence-to-sequence tasks, particularly language translation.
Results indicate that these models can match the original’s performance, showcasing the efficacy of shallow feed-forward networks as attention-layer alternatives. Ablation studies offer insights into replacement network types and sizes, affirming their viability. However, replacing the cross-attention mechanism in the decoder significantly degrades performance, suggesting that while shallow networks excel in self-attention, they need help emulating complex cross-attention interactions in the Transformer model.
In conclusion, the study on attentionless Transformers highlights the need for advanced optimization techniques like knowledge distillation for training these models from scratch. While less specialized architectures may have potential for advanced tasks, replacing the cross-attention mechanism in the decoder with feed-forward networks can significantly reduce performance, revealing the challenges in capturing complex cross-attention interactions.
Future work could optimize hyperparameters using advanced techniques like Bayesian optimization to enhance translation quality and address size bottlenecks. Exploring more complex feed-forward networks, especially for the decoder’s cross-attention, may improve capturing complexity. Investigating alternative architectures for improved expressiveness in cross-attention is a promising research direction. The generalizability of attentionless Transformers to diverse sequence-to-sequence tasks warrants exploration. Further experiments and ablation studies can provide deeper insights, potentially refining the approach and optimizing feed-forward networks emulating attention mechanisms.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.