ReLU vs. Softmax in Vision Transformers: Does Sequence Length Matter? Insights from a Google DeepMind Research Paper
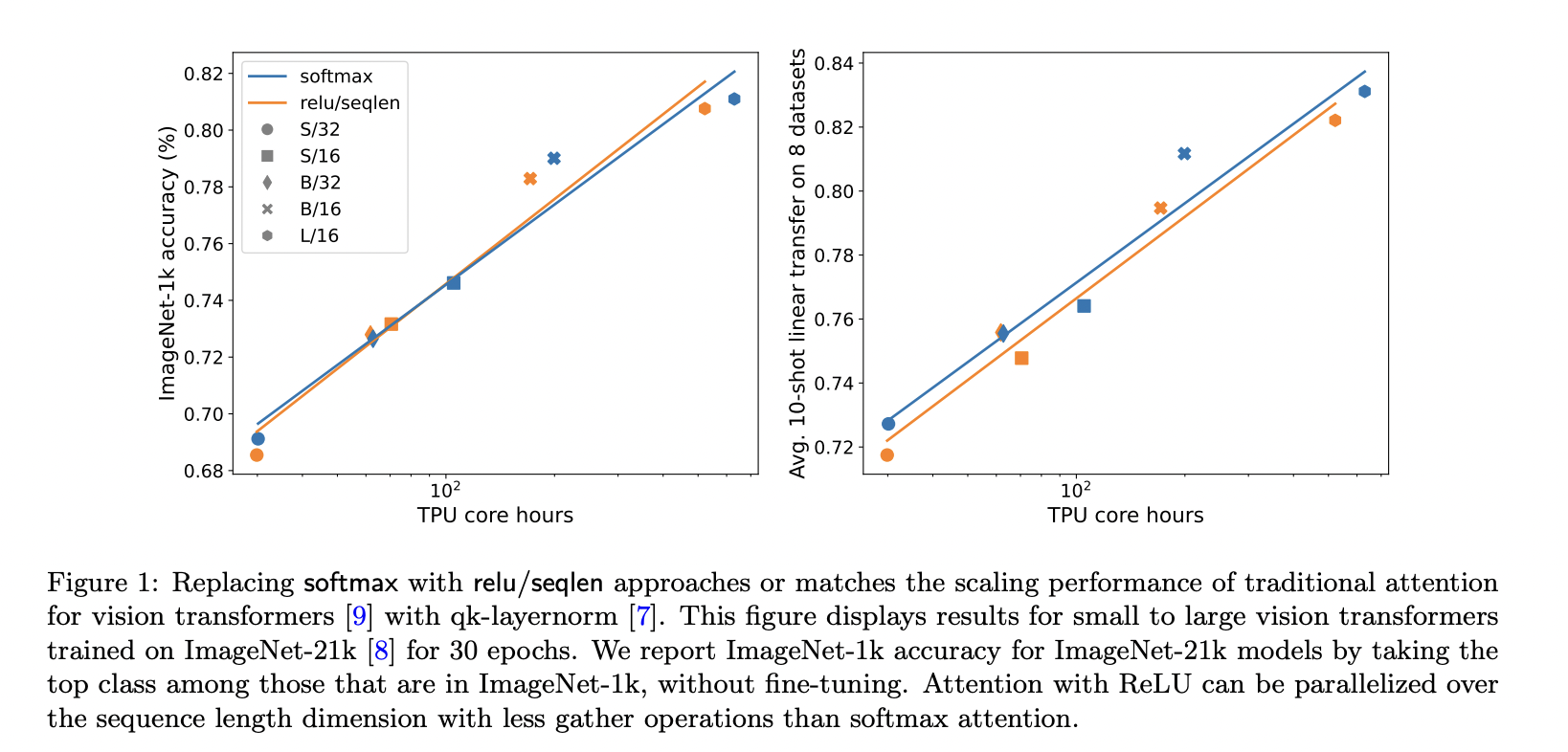
A common machine learning architecture today is the transformer architecture. One of the main parts of the transformer, attention, has a softmax that generates a probability distribution across tokens. Parallelization is difficult with Softmax since it is expensive owing to an exponent calculation and a sum over the length of the sequence. In this study, they investigate point-wise softmax alternatives that do not always provide a probability distribution. One standout finding is that, for visual transformers, scaling behavior for attention with ReLU split by sequence length can come close to or match that of classic softmax attention.
This finding opens up new possibilities for parallelization since ReLU-attention parallelizes more easily than standard attention along the sequence length dimension. In earlier studies, ReLU or squared ReLU have been considered possible replacements for softmax. However, these methods do not split by sequence length, which researchers from Google DeepMind find crucial for achieving accuracy on par with softmax. Additionally, earlier research has taken the role of softmax, albeit normalization across the axis of sequence length is still necessary to guarantee that the attention weights add up to one. The drawback of requiring a gather remains with this. Additionally, there is a wealth of research that eliminates activation functions to make attention linear, which is advantageous for lengthy sequence durations.
In their studies, accuracy was lowered when the activation was completely removed. Their tests utilize ImageNet-21k and ImageNet-1k training settings from the BigVision source without changing hyperparameters. They train for 30 epochs in their experiments on ImageNet-21k and 300 epochs in their trials on ImageNet-1k. As a result, both training runs take around 9e5 steps, which is a similar quantity. As this was previously discovered to be required to avoid instability when scaling model size, they utilize ViTs with the qk-layer norm. They conclude that this is not a crucial element on their scales.
They report ImageNet-1k accuracy for ImageNet-21k models by taking the top class among those in ImageNet-1k without fine-tuning. They use the terms i21k and i1k to denote ImageNet-21k and ImageNet-1k, respectively. They utilize a 10-shot linear probe averaged across three seeds to assess transfer performance on downstream activities. The downstream jobs are Caltech Birds, Caltech101, Stanford Cars, CIFAR-100, DTD, ColHsit, Pets, and UC Merced. This study raises a lot of unanswered issues. They must discover why factor L^(-1) boosts performance or if this concept can be learned. Furthermore, there may be a more effective activation function that they are not investigating.
Check out the Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 30k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.