Researchers At Amazon Propose ‘AdaMix’, An Adaptive Differentially Private Algorithm For Training Deep Neural Network Classifiers Using Both Private And Public Image Data
It is crucial to preserve privacy by restricting the amount of data that may be gathered about each training sample when training a deep neural network for visual classification. Differential Privacy (DP) is a theoretical framework that aims to give strong guarantees regarding the most data that an attacker can possibly obtain about a specific training sample. A privacy parameter, which is often dependent on the application context, is one way that DP specifically enables users to choose the desired trade-off between privacy and accuracy.
It is difficult to train big machine learning models while ensuring that each sample has a high level of privacy. In reality, however, one frequently has access to a pool of data for which there are no privacy issues. This could be a fake dataset or a dataset created with public use in mind. These public data are separate from private data, the privacy of which is sought after strongly. The development of language models that accomplish DP on the goal task while maintaining performance that is close to the state-of-the-art has recently been made possible, in particular, by the use of vast volumes of general public data for pre-training.
Avoiding the use of private data altogether is one definite approach to protecting privacy, and recent research has offered numerous strategies for doing so. For instance, by employing zero-shot learning, one can train a visual model with public data from a different modality (such as text) without ever viewing the private data. To train utilizing few-shot learning, one can more generally source or create a few samples of labeled public data from the task distribution, all the while avoiding the use of private data.
Ignoring the latter is not a desirable technique to protect privacy because there may be a slight domain change between the public and private data. Therefore, the issue is how to employ both private data and modest bits of public data to overcome the trade-off between accuracy and privacy.
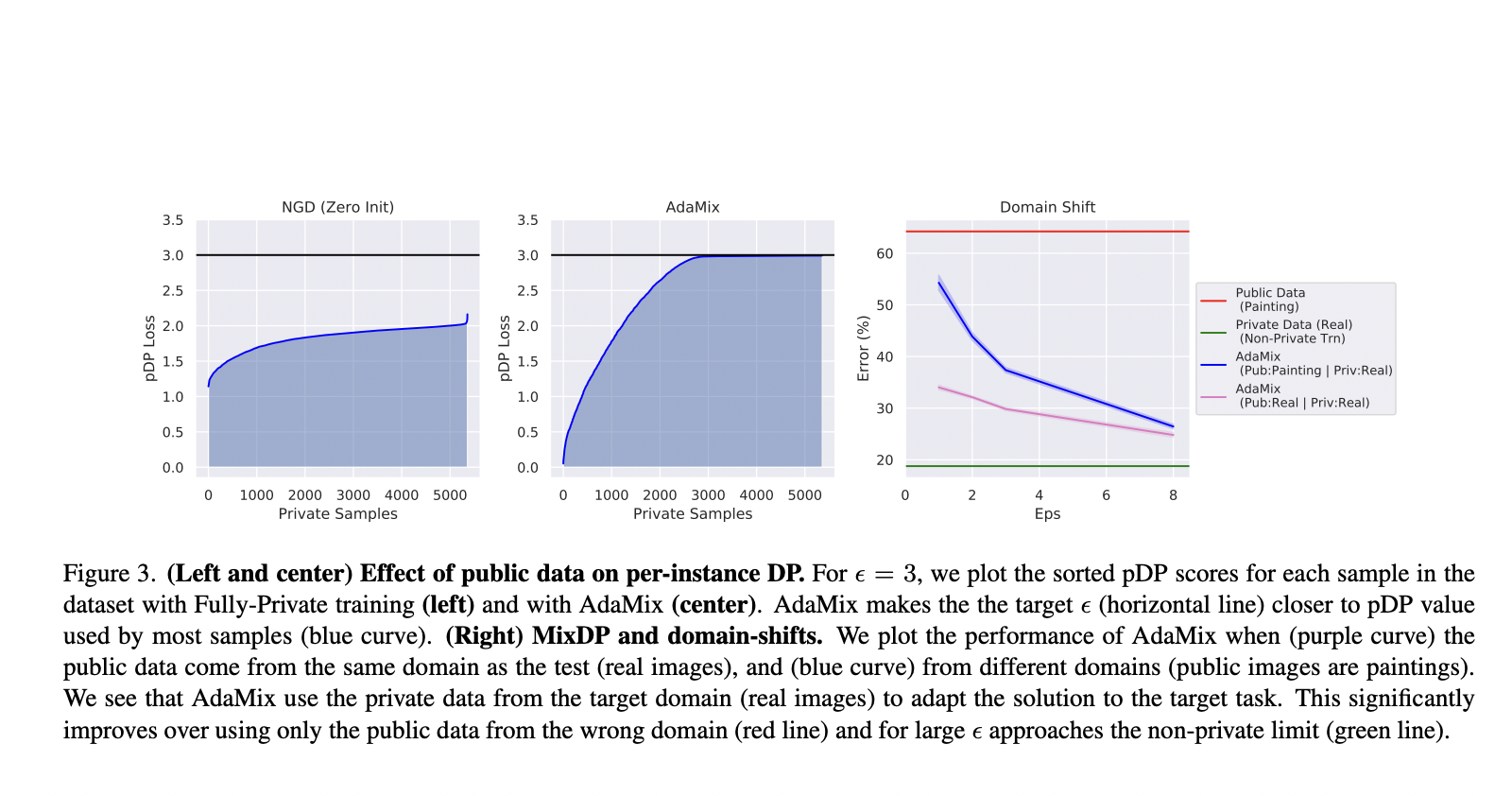
To do this, Amazon researchers recently altered the environment of a study from the majority of work on DP to tag public data sources with the same labels as the objective task. This setting is known as MixDP or mixed differential privacy. Researchers suggested using the public data to create a classifier for few-shot or zero-shot learning on the target tasks, prior to private fine-tuning, in order to overcome MixDP.
In comparison to training with only private or only public data, even with a modest amount of the latter, researchers demonstrated that it was possible to make considerable gains in the MixDP environment. To achieve this, they adjusted already-existing DP training algorithms to the mixed environment, which resulted in the creation of AdaMix, a method for MixDP that uses public data to tune and adapt all significant phases of private training, particularly model initialization, gradient clipping, and projection onto a lower-dimensional subspace.
The lengthy tails of the data are crucial for strong classification performance in visual classification tasks. Outliers or long tails have a significant impact on DP because it is a worst-case framework. MixDP solves the issue by enabling the collection of open data to guarantee that each subpopulation is adequately covered. The algorithm’s convergence was demonstrated by researchers along with a new, stronger constraint for the strongly convex situation. The team was able to compare the algorithm’s usefulness to that of its non-private equivalent, thanks to this as well.
Conclusions.
Differentially For realistic privacy parameters, private models in computer vision frequently perform worse than non-private models. Researchers at Amazon demonstrated, using AdaMix in the MixDP learning environment, that accurate networks can be created that achieve better accuracies than entirely private training without compromising the privacy of the data, assuming the existence of a modest quantity of public data. The team is hopeful that greater study in this area will contribute to the adoption of private models in more computer vision applications.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Mixed Differential Privacy in Computer Vision'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit
Credit: Source link
Comments are closed.