Researchers at Apple developed Fairness Optimized Reweighting via Meta-Learning (FORML), a Machine Learning Training Algorithm that balances Fairness and Robustness with Accuracy by jointly learning training sample Weights and Neural Network Parameters
Deep neural networks are used in machine learning applications such as image classification, audio recognition, natural language comprehension, and healthcare. Despite modern DNN architectures’ strong predictive performance, models can inherit biases and fail to generalize as data distribution differs in validation and training or when the test evaluation metrics differ from those used during training. This is due to spurious correlations in the dataset and overfitting of the training metric. Importantly, this can lead to fairness breaches for specific test groups.
Data reweighting is a typical data-centric paradigm in fairness and robustness for minimizing data distribution shifts and class imbalance. Weights are computed by reweighting iteratively based on the training loss or fairness violations on the training set in data-dependent reweighting algorithms. Resampling data, applying domain-specific knowledge, estimating weights based on data complexity, and using class-count information are all traditional techniques for data reweighting. Other research has enhanced traditional techniques by learning a function that maps inputs to weights or optimizing for weights by considering them as directly learnable parameters. The approach does not learn a global set of weights and cannot be utilized for post-training data reduction.
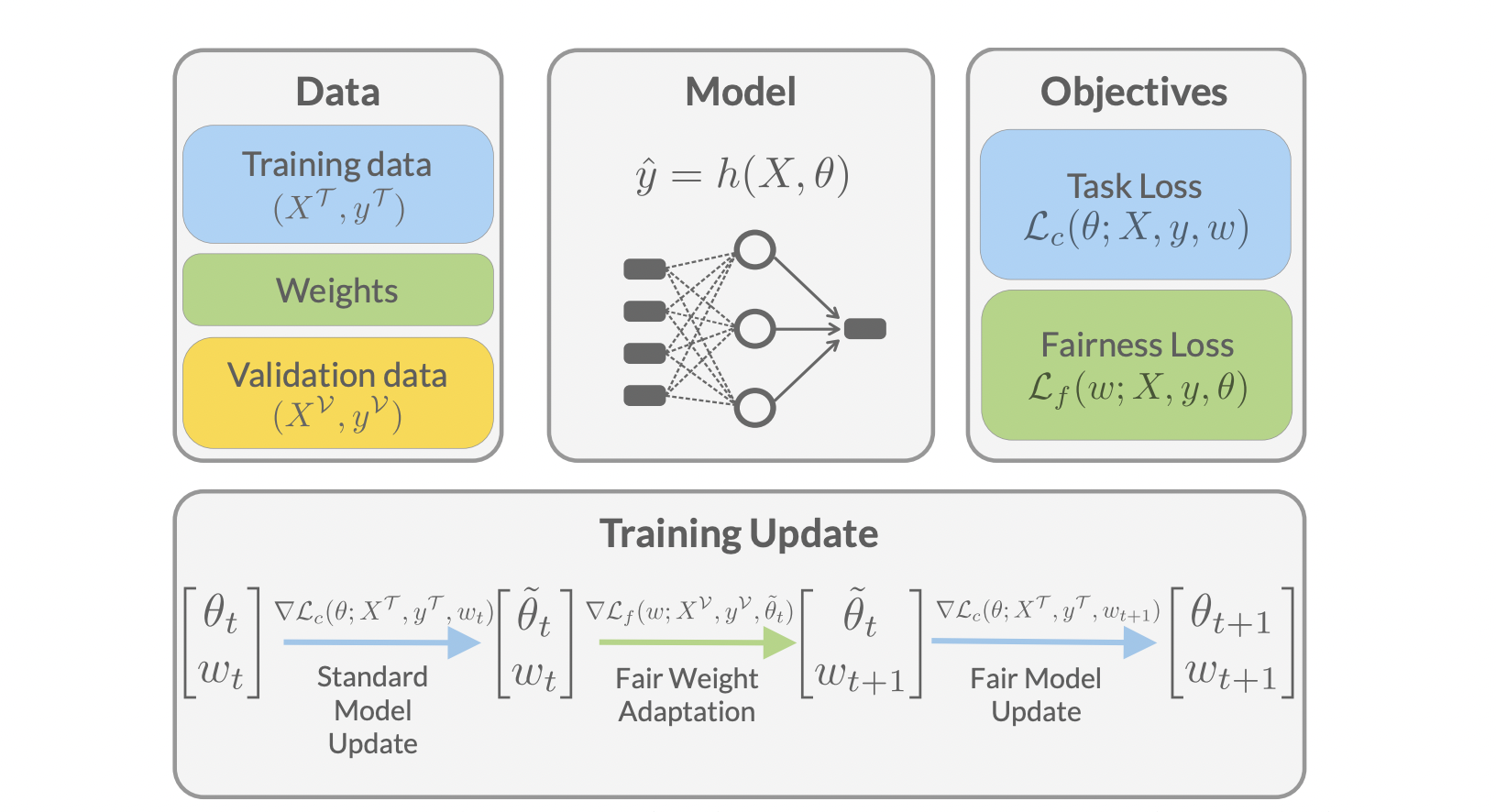
Prior reweighting methods strive to increase generalization and resilience to noisy labels, class imbalance, training time, and convergence by learning a curriculum over cases. Few of these efforts try to reweight data to maximize another statistic directly. In this paper, researchers present Fairness Optimized Reweighting through Meta-Learning, a method that directly improves both fairness and predictive performance. They use the learning-to-learn paradigm to learn a weight for each sample jointly. It is done in the training set. The model parameters are optimized for the specified test measure and a fairness criterion over a held-out exemplar set, which integrates data significance.
The technique optimizes model parameters at a high level using a weighted loss goal and a global set of sample weights over the exemplar set using predefined fairness criteria. Learning sample weights over an exemplar set aids in adapting the model to the fairness metric, which improves label efficiency because held-out validation sets are typically much smaller than the training data set where attribute labels are required.
FORML does not merely learn to reweight solely on the number of samples since they witness fewer fairness violations even when samples are distributed evenly across groups, but on the significance of data points to the fairness criterion. They test the technique on image recognition datasets and show that it decreases fairness violations by enhancing the lowest group performance without affecting total performance. Furthermore, FORML enhances performance in noisy label conditions, and FORML may be used to eliminate detrimental data samples, resulting in greater fairness and efficiency.
Researchers think that properly using data may create fairer models without losing accuracy. FORML has numerous advantages: it is simple to apply by making minimal changes in training, and it does not need data pre-processing or post-processing of model outputs. Furthermore, FORML is a data-centric strategy that increases fairness depending on the dataset and is model and fairness metric agnostic, going beyond classification.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'FORML: Learning to Reweight Data for Fairness'. All Credit For This Research Goes To Researchers on This Project. Check out the paper. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.