Researchers at ByteDance develop IDOL for enabling Models to learn more about Discriminative and Robust Instance Features for VIS (Video Instance Segmentation) Tasks
The goal of video instance segmentation is to simultaneously find, segment, and track all instances of an object in a video. Due to the enormous challenge and several applications in video interpretation, video editing, autonomous driving, augmented reality, etc., it received much attention after its initial definition in 2019.
There are two types of current VIS techniques: online and offline. Online techniques use a video as an input and detect and segment things in each frame while tracking instances and improving outcomes over time. In contrast, offline approaches use the complete movie as their input and produce the instance sequence of the entire video in a single step.
Even while offline models have good performance, the demand for entire movies restricts the application scenarios, particularly in situations where there are lengthy video sequences and ongoing films. However, a significant disadvantage of online models is that they frequently perform worse than the current offline models.
Prior to now, little research has attempted to explain the performance difference between these two paradigms or provide information about the offline paradigm’s high performance. The ability of offline models to bypass error-accumulating tracking steps and use the richer data offered by several frames to better segmentation is a common attempt made by the latter.
The offline approaches have a significant advantage over hand-designed association modules from the perspective of association. It functions nicely with the dataset’s specific situations. This primarily causes the performance difference between the present online and offline paradigms. However, the black-box association mechanism used in offline models also quickly deteriorates as the complexity of the video increases.
In order to avoid exceeding computational restrictions while handling lengthier movies, such as those in the real world, offline algorithms must split the input video into clips. As a result, hand-designed clip matching is still required, further lowering performance. In conclusion, matching and association still play a major role in offline models and are the primary cause of the performance gap.
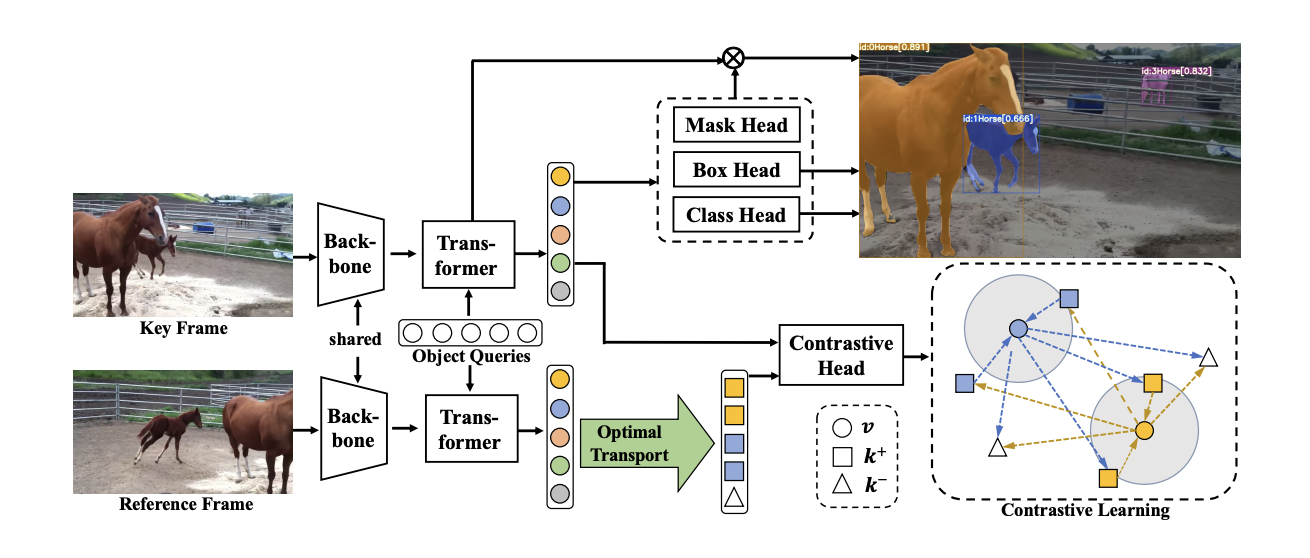
In a recent study, researchers at ByteDance suggested a framework for In Defense of OnLine models for video instance segmentation, known as IDOL, to enhance matching performance and close the performance gap. The main goal is to guarantee that, even for examples that belong to the same category and have comparable appearances, there is a similarity between the same instance across frames and a difference between different instances across all frames in the embedding space.
It offers stronger temporal consistency and more discriminative instance features, resulting in more precise association results. Contrastive learning is hindered by the prior technique, which manually selects positive and negative samples, creating false positives in crowded situations and occlusions.
In order to address it, researchers developed the sample selection problem as an Optimal Transport problem in Optimization Theory, which lowers false positives and raises the embedding quality. The researchers made use of the learned prior to the embedding during inference, utilizing one-to-many temporally weighted softmax to re-identify missing instances brought on by occlusions and to enforce the consistency and integrality of linkages.
On a variety of datasets, researchers conducted comprehensive tests. Despite its ease of use, IDOL achieves a new benchmark for performance on the validation set of datasets. More significantly, researchers improved these datasets consistently when compared to earlier online techniques. They even outperformed the earlier SOTA offline approach. The method’s success and simplicity, according to researchers, will help with future studies. The comprehensive research also offers insights into current approaches and offers helpful recommendations for future work in both online and offline VIS.
Conclusions
While managing lengthy or continuous films is an inherent advantage of online video instance segmentation algorithms, their performance lags behind that of offline models. ByteDance researchers sought to close the performance gap in this effort. The team started by thoroughly analyzing the existing online and offline models and discovered that the clumsy linkage between frames primarily causes the gap. Researchers developed IDOL, which enables models to acquire more robust and discriminative instance characteristics for VIS tasks in response to this observation. On three benchmarks, it greatly beats all online and offline techniques and reaches new SOTA. They hope that their insights into VIS methods will inspire future work in both online and offline approaches.
This Article is written as a summary article by Marktechpost Staff based on the research paper 'In Defense of Online Models for Video Instance Segmentation'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Nitish is a computer science undergraduate with keen interest in the field of deep learning. He has done various projects related to deep learning and closely follows the new advancements taking place in the field.
Credit: Source link
Comments are closed.