Researchers at DeepMind Trained a Semi-Parametric Reinforcement Learning RL Architecture to Retrieve and Use Relevant Information from Large Datasets of Experience
In our day-to-day life, humans make a lot of decisions. Flexibly applying prior experiences to a novel scenario is required for effective decision-making. One might wonder how reinforcement learning (RL) agents use relevant information to make decisions? Deep RL agents are often depicted as a monolithic parametric function that has been taught to amortize meaningful knowledge from experience using gradient descent gradually. It has proven useful, but it is a sluggish method of integrating expertise, with no simple mechanism for an agent to assimilate new knowledge without requiring numerous extra gradient adjustments. Furthermore, as surroundings get more complicated, this necessitates increasingly enormous model scaling driven by the parametric function’s dual duty, which must enable computation and memorization.
Finally, this technique has a second disadvantage that is especially relevant in RL. An agent cannot directly influence its behaviors by attending to information, not in working memory. The only way previously encountered knowledge (not in working memory) might improve decision-making in a new circumstance is indirectly through weight changes mediated by network losses. The availability of more information from prior experiences inside an episode has been the subject of much research (e.g., recurrent networks, slot-based memory). Although subsequent studies have started to investigate using information from the same agent’s inter-episodic episodes, extensive direct use of more general types of experience or data has been restricted.
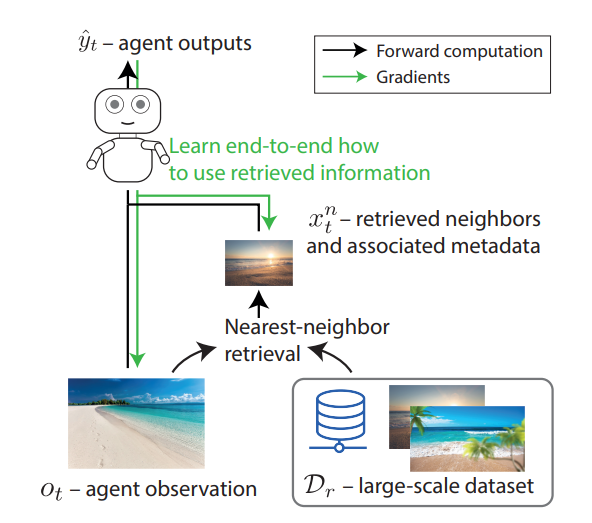
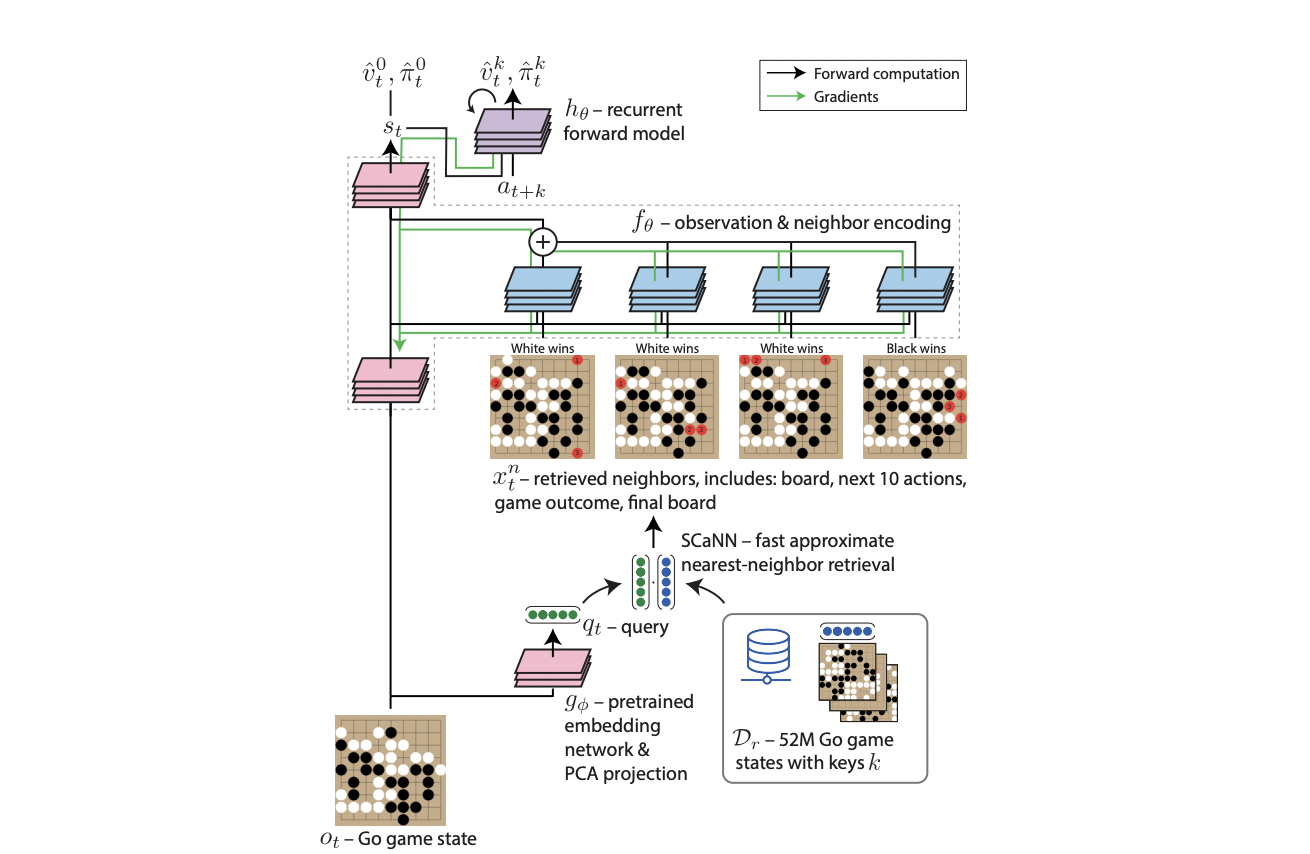
The aim is to dramatically extend the volume of information an agent can access, allowing it to attend to tens of millions of bits of information while learning how to use this information for decision-making from start to finish. One may consider this the first step toward a vision in which an agent may draw on various large-scale knowledge sources, including its own (inter-episodic) experiences and those of humans and other agents.
Additionally, since the information being retrieved need not follow the structure of the agent’s observations, retrieval could make it possible for agents to include data from sources like videos, text, and third-party demonstrations that have not previously been used. It is a semi-parametric agent architecture that dynamically retrieves pertinent facts from a dataset of experience using quick and effective approximate closest neighbor matching. It has been tested in an offline RL environment for the game 9×9 Go, which has around 1038 potential games and presents a challenging generalization problem from historical data to new conditions.
The agent is provided with a large-scale dataset of 50M Go board-state observations and discovers that a retrieval-based method based on this data may consistently and considerably beat a non-retrieval solid baseline. A retrieval-augmented network can use more processing resources instead of amortizing all relevant information into its network weights. Furthermore, by using a semi-parametric form, one may change the information available to the agent during assessment without retraining it. Surprisingly, we discover that when games against the assessment opponent are added to the agent’s knowledge base, it may increase its performance without further training.
This Article is written as a summary article by Marktechpost Staff based on the paper 'Large-Scale Retrieval for Reinforcement Learning'. All Credit For This Research Goes To Researchers on This Project. Checkout the paper. Please Don't Forget To Join Our ML Subreddit

Promote Your Brand 🚀 Marktechpost – An Untapped Resource for Your AI/ML Coverage Needs
Get high-quality leads from a niche tech audience. Benefit from our 1 million+ views and impressions each month. Tap into our audience of data scientists, machine learning researchers, and more.
Credit: Source link
Comments are closed.