Researchers at Microsoft Introduce Z-Code++, A Pre-Trained Language Model Optimized For Abstractive Summarization
In this research article, Microsoft researchers introduce Z-Code++, an advanced encoder-decoder PLM (Pre-trained Language Model) created for machine translation that considerably enhances Z-Code and is optimized for abstractive summarization.
Z-Code++ is a novel encoder-decoder pretrained language model optimized for abstractive summarization. Z-Code++ outperforms the fine-tuned and 200x larger GPT3-175B on the SAMSum human-annotated dialogue dataset.
The automatic software manipulation of natural languages, such as speech and text, is known as natural language processing, or NLP for short.
Abstractive text summarization, a task in natural language processing (NLP), aims to deliver concise and fluid document summaries. Large-scale pretrained language models’ recent development has significantly improved the effectiveness of abstractive text summarising. However, these models are susceptible to the “hallucination problem,” where the generated summaries might turn illogical or betray the input content.
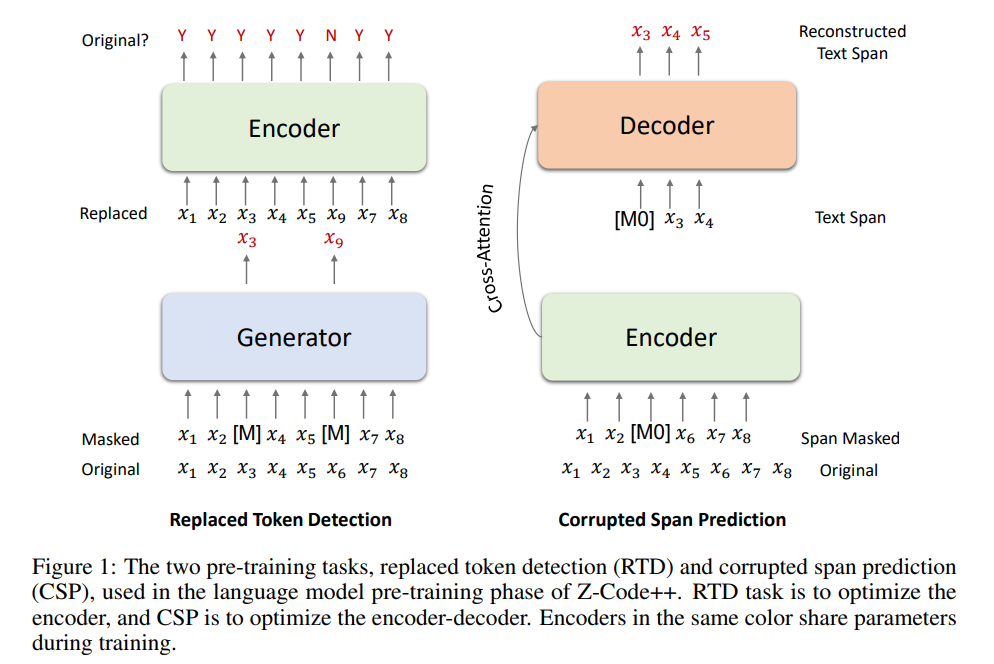
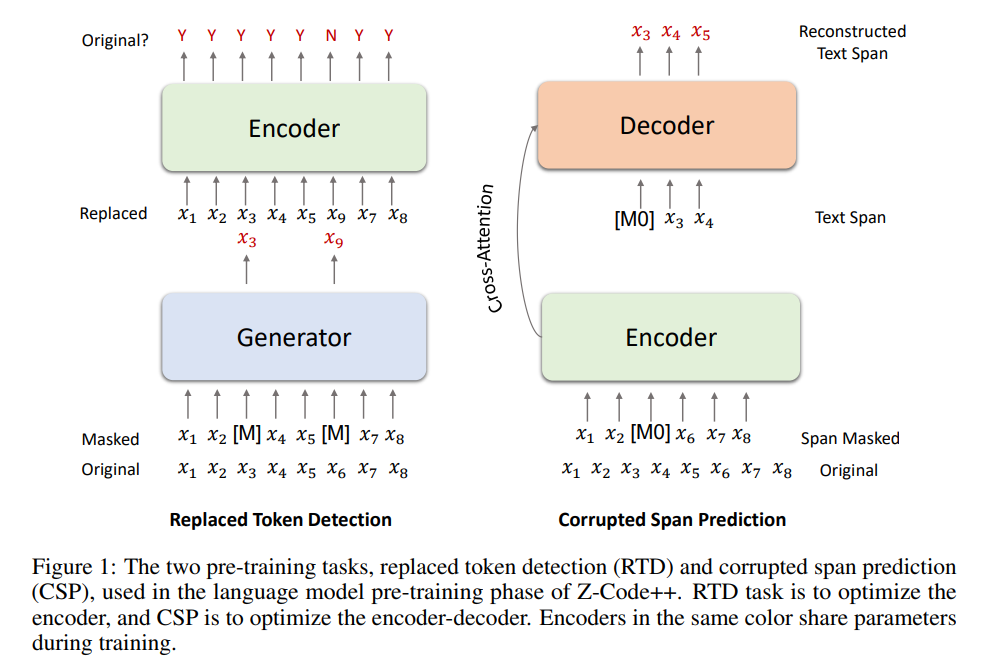
Three methods are used in the proposed Z-Code++ to extend the encoder-decoder model: a two-phase pretraining procedure, a disentangled attention mechanism, and a fusion-in-encoder technique.
The grounded pre-training phase and the language model pre-training phase make up the two-phase pretraining. Z-Code++ is pre-trained utilizing corrupted span prediction and replacement token detection (RTD) during the language model pre-training phase (CSP). RTD generates ambiguous tokens, which a discriminator categorizes as coming from the generator or the original input. The model is additionally trained on a summarization corpus of document-summary pairs during the grounded pre-training phase, which greatly enhances performance on downstream tasks in low-resource environments.
Disentangled attention (DA), which encodes a word using two vectors that encode its content and position, also replaces the transformer self-attention layer in the encoder. The performance of text summarization is enhanced by DA because it encodes positional dependency more effectively than the conventional self-attention technique. The last mechanism used is a straightforward yet efficient fusion-in encoder, which can encode long sequences while preserving high attention precision for short sequences.
The team’s empirical study contrasted the suggested Z-Code++ with baseline approaches on representative summarization tasks. In the tests, Z-Code++ outperformed the 600x larger PaLM540B on XSum and the 200x larger fine-tuned GPT3-175B on SAMSum, achieving state-of-the-art performance on 9 out of 13 text summary jobs across five languages. Additionally, Z-Code++ showed improved performance in the circumstances with zero shots and few shots.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Z-Code++: A Pre-trained Language Model Optimized for Abstractive Summarization'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and refeference article. Please Don't Forget To Join Our ML Subreddit
![]()
Asif Razzaq is an AI Journalist and Cofounder of Marktechpost, LLC. He is a visionary, entrepreneur and engineer who aspires to use the power of Artificial Intelligence for good.
Asif’s latest venture is the development of an Artificial Intelligence Media Platform (Marktechpost) that will revolutionize how people can find relevant news related to Artificial Intelligence, Data Science and Machine Learning.
Asif was featured by Onalytica in it’s ‘Who’s Who in AI? (Influential Voices & Brands)’ as one of the ‘Influential Journalists in AI’ (https://onalytica.com/wp-content/uploads/2021/09/Whos-Who-In-AI.pdf). His interview was also featured by Onalytica (https://onalytica.com/blog/posts/interview-with-asif-razzaq/).
Credit: Source link
Comments are closed.