Researchers at Microsoft Research and TUM Have Made Robots to Change Trajectory by Voice Command
While deploying a robot in a real environment, many obstacles can often come. Like a robot arm is deployed to pick up an object, and suddenly some animal comes in front, which is unable to understand the robot’s movement. Then the robot has chances to get damaged. As a user, a primary thought can come to our mind if we were able to command the robot to change the robot’s path then. Researchers at Microsoft Research and TUM have made a human-robot interface that enables the robot to change its path by voice command.
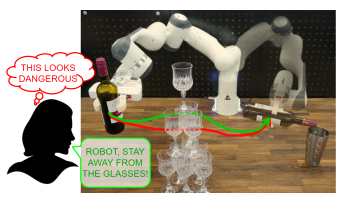
Multi-modal processing has gained much attention in recent years. It is the processing of various kinds of data together; for example, audio and video are combinedly processed to make some inference on video. So, the language and image need to be processed together to enable the robot to see obstacles and avoid them by listening to voice commands.
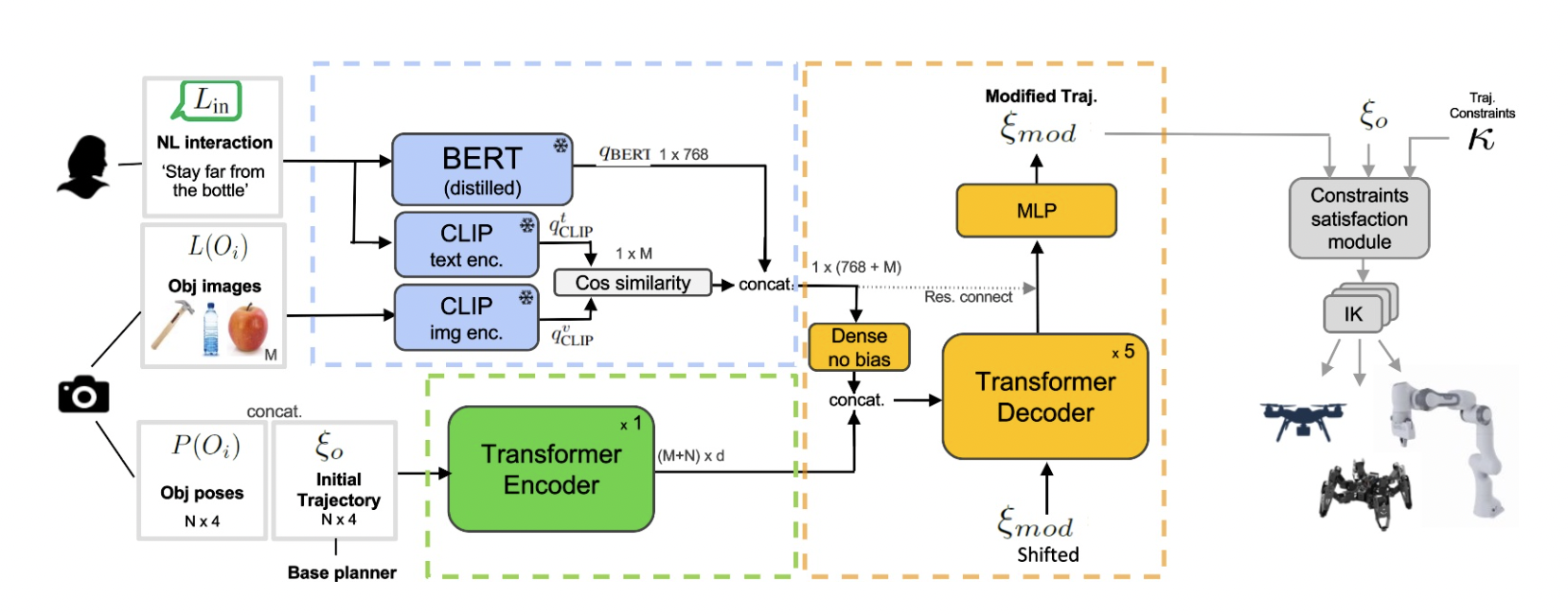
The researchers have made a model that’d modify the coordinates of the robot’s trajectory given precise coordinates and tags of objects of the image along with language commands. They have used pre-trained models to encode the multi-modal data because these models are trained on a large dataset for any downstream task so that they can be easily adapted with minimal fine-tuning.
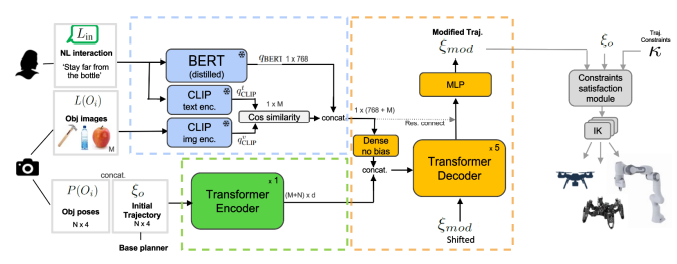
BERT is a pre-trained transformer-based encoder to produce features from language, and they have used it to encode the language command. CLIP is another transformer-based encoder pre-trained to predict a text containing objects in the image. They have used pre-trained weights of the transformer of CLIP to generate features corresponding to both image and the language. The encodings from BERT and CLIP are concatenated to form the joint feature embedding.
Now we also have actual coordinates or trajectories of the robot and coordinates of the objects. Using a transformer-based encoder, these coordinates are further transformed into a meaningful feature representation.
Now all the embeddings from language, image tags, object locations, and actual trajectory are passed through a multi-modal transformer decoder to generate modified trajectory coordinates. Now the main issue that arises is how to create training data, as we do not have any fixed modified path; the robot can take any path according to language command and vision. They have solved it by generating their own training data. First, they have created a set of meaningful examples that can result in significant trajectory space and direction. They have generated joint feature embedding for those examples. A* planner computes the initial coordinates, and the CHOMP motion planner computes the modified trajectory given the joint feature embedding.
They evaluated the performance in both simulated and real environments and showed that this approach outperforms any existing approaches. However, the movements are restricted to basic tasks, like ‘moving left’ or ‘moving away from’ etc. In order to achieve more complex tasks, the robot must map a causal relation among objects from language commands. This can be the next step of this research.
Paper 1: https://arxiv.org/pdf/2203.13411.pdf
Paper 2: https://arxiv.org/pdf/2208.02918.pdf
Github: https://github.com/arthurfenderbucker/nl_trajectory_reshaper
Reference Article: https://www.microsoft.com/en-us/research/group/autonomous-systems-group-robotics/articles/robot-language/
Please Don't Forget To Join Our ML Subreddit
![]()
I’m Arkaprava from Kolkata, India. I have completed my B.Tech. in Electronics and Communication Engineering in the year 2020 from Kalyani Government Engineering College, India. During my B.Tech. I’ve developed a keen interest in Signal Processing and its applications. Currently I’m pursuing MS degree from IIT Kanpur in Signal Processing, doing research on Audio Analysis using Deep Learning. Currently I’m working on unsupervised or semi-supervised learning frameworks for several tasks in audio.
Credit: Source link
Comments are closed.