Researchers at MIT and IBM Propose an Efficient Machine Learning Method That Uses Graph Grammar to Generate New Molecules
This research summary is based on the paper 'DATA-EFFICIENT GRAPH GRAMMAR LEARNING FOR MOLECULAR GENERATION' Please don't forget to join our ML Subreddit
Chemical engineers and materials scientists are continuously looking for the following groundbreaking material, chemical, or medication. The emergence of machine-learning technologies has accelerated the discovery process, which may typically take years. Ideally, the objective is to train a machine-learning model on a few known chemical samples and then let it build as many manufacturable molecules of the same class with predictable physical attributes as feasible. You can develop new molecules with ideal characteristics if you have all of these components and the know-how to synthesize them.
However, current approaches need large datasets for training models. Many class-specific chemical databases only contain a few example compounds, restricting their capacity to generalize and construct biological molecules that might be generated in the real world.
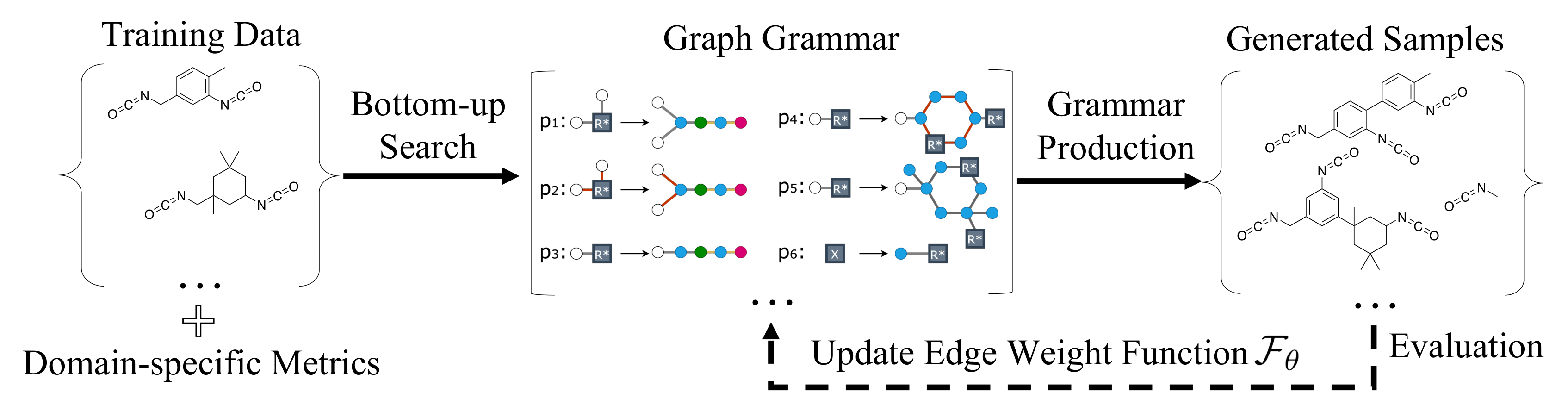
This issue was addressed by a team of researchers from MIT and IBM by employing a generative graph model to create new synthesizable compounds within the same training data’s chemical class. The research was presented in a research paper. They model the production of atoms and chemical bonds as a graph and create a graph grammar — a linguistic analog of systems and structures for word ordering — that provides a set of rules for constructing compounds like monomers and polymers.
Using the grammar and production rules inferred from the training set, the model can reverse engineer its examples and generate new compounds in a methodical and data-efficient manner. Because this syntax is explainable and expressive, it can be applied for monomer and polymer creation. A wide range of structures can be produced with only a few manufacturing rules.
A molecular structure may be a graph’s symbolic representation — a string of atoms (nodes) linked together by chemical bonds (edges). The researchers use this strategy to let the model take the chemical structure and compress a substructure of the molecule down to one node. This may be two atoms joined by a bond, a brief series of bound atoms, or a ring of particles. This is performed until only one node remains, at which point the production rules are created.

The rules and language might then be applied to reproduce the training set from scratch or other combinations to construct new molecules of the same chemical class. Previous graph creation methods would create one node or one edge sequentially at a time. Still, looking at higher-level structures, especially chemical knowledge, doesn’t take individual atoms and bonds as the unit. This streamlines the creation process while also making learning more data-efficient. Furthermore, the researchers improved the process so that the bottom-up grammar was rather basic and uncomplicated, resulting in molecules that could be created.
If the sequence in which these manufacturing principles are applied is reversed, we obtain another molecule; moreover, we can enumerate all the possibilities and make tonnes of them. Because some of these molecules are legitimate and others are not, learning the language itself is essential to find a minimal collection of production rules. The percentage of molecules that can be synthesized is maximized. While the researchers focused on three training sets with less than 33 samples each — acrylates, chain extenders, and isocyanates — they added that the approach might be extended to any chemical class.
The researchers compared DEG to other cutting-edge models and approaches, looking at percentages of chemically valid and unique compounds, variety of those synthesized, retrosynthesis success rate, and proportion of molecules belonging to the training data’s monomer class.
The approach surpasses all current techniques by a significant margin for synthesizability and membership, while it’s similar for specific other frequently used metrics. What is astonishing about the algorithm is that roughly 0.15 percent of the original dataset is required to obtain very similar outcomes compared to state-of-the-art algorithms that train on tens of thousands of samples. The technique is specially designed to deal with the problem of data sparsity.
Shortly, the team intends to scale up this language learning process to construct enormous graphs and synthesize and identify molecules with essential features.
The researchers envisage various possibilities for the DEG approach in the future, pointing out that it is extensible beyond developing novel chemical structures. A graph is a highly versatile representation, and it may be used to represent a wide range of items, including robots, cars, buildings, and electronic circuits. Essentially, the objective is to build up the grammar so that the visual representation can be extensively utilized across various domains. DEG may automate the generation of innovative things and structures.
Paper: https://openreview.net/pdf?id=l4IHywGq6a
Github: https://github.com/gmh14/data_efficient_grammar
Reference: https://news.mit.edu/2022/generating-new-molecules-with-graph-grammar-0401
Suggested
Credit: Source link
Comments are closed.