Researchers at Oxford University Propose a Machine Learning Framework Called ‘TriSegNet’ Based on Triple-View Feature Learning for Medical Image Segmentation
Deep learning’s potential performance for medical imaging depends not only on the design of the network architecture but also on the availability of a sufficient amount of high-quality, manually annotated data, which is difficult to come by. Two techniques for semi-supervised learning that have received much attention are co-training and self-training. A model is initially initialized with labeled data during self-training. The model then creates fictitious masks for the unlabeled data. The model is retrained by extending its training data, and a criterion is established for choosing pseudo masks.
Deep co-training was initially presented as a solution to the problem of “collapsed neural networks,” which prevents multiview feature learning when two models are trained on the same dataset because they will inevitably become similar. By increasing the quantity of the training data, co-training is typically used to train two distinct models with two viewpoints. Methods like output smearing, diversity augmentation, and dropout for pseudo label editing were created to lessen the impact.
The critical component of the approach is the simultaneous development of several (in instance, three) distinct data perspectives and the related learned parameters in various models. It allows each model to enhance the contributions of the others to the learning process. Additionally, they do not process the same dataset; instead, they pick carefully constructed, disparate subsets of the data and extract what they can from each one. It is also suggested to use a multiview co-training semi-supervised learning method for classification, although for a classification problem rather than for semantic segmentation.
Detailed mask prediction necessitates an entirely new method. In order to train the third CNN component, the pseudo-labels are generated from scratch at intermediate steps by choosing from the output of two separate CNN components. The confidence estimation differs from the uncertainty-aware approach in that the triple framework chooses the pseudo-labels that the various component models have ‘voted’ for and in which they have shown high confidence. Additionally, they demonstrate how to quantify how this impacts the overall confidence of the framework.
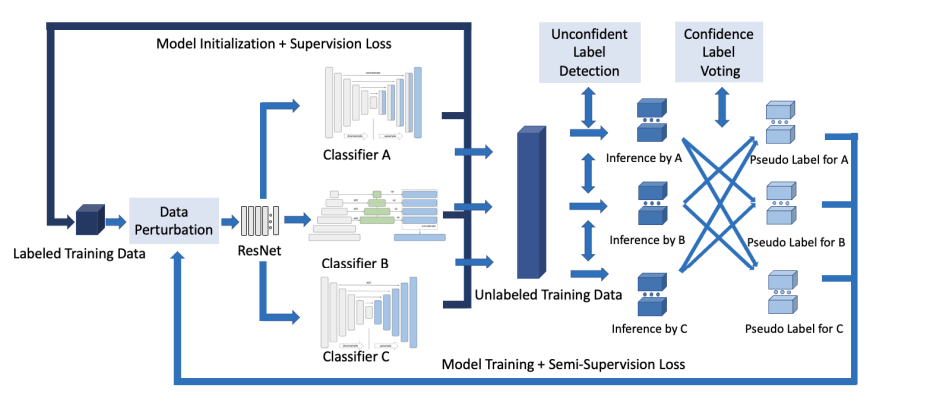
The following step does not employ pseudo-labels with a sufficient level of confidence. The training stage determines how low that confidence level should be; the further the training process, the more assured the framework should be. As a result, the quantity of photos available for training gradually grows. The figure below shows the structure of the Triple-view feature learning for semantic segmentation network for medical images (TriSegNet).
The feature expression of unannotated data is improved by label editing. It includes unconfident label detection and confidence label voting based on a confidence estimate. Random data perturbation is used for regularisation in each of the three viewpoints of feature learning. The three high-level feature learning pixel-level classifiers A, B, and C use a pre-trained ResNet as a low-level feature learning module. The architecture and parameters initialization are created separately for triple-view learning. A, B, and C use an encoder-decoder.
They fully model long-range dependencies, variation size of feature expression, model skip connections, bypass spatial information, and process multi-scale feature maps to communicate enough semantic information. The ResNet can extract low-level features in a general way because of the low-level feature learning module, which is modeled after, and the three classifier views. In the semi-supervised process, A, B, and C not only extract features but also vote, create pseudo labels, and generally benefit one another.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'Triple-View Feature Learning for Medical Image Segmentation'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and github link. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.