Researchers At SenseTime Develop HuMMan: A Multi-Modal 4D Human Dataset For Versatile Sensing And Modeling
This Article Is Based On The Research Paper 'HuMMan: Multi-Modal 4D Human Dataset for Versatile Sensing and Modeling'. All Credit For This Research Goes To The Researchers 👏👏👏 Please Don't Forget To Join Our ML Subreddit
Sensing and modeling humans have long been a challenge for the computer vision and computer graphics communities, which provide the foundation for a wide range of applications, including animation, gaming, augmented reality, and virtual reality.
With the introduction of large-scale datasets and the advent of deep learning, tremendous progress in human-centric sensing and modeling has been made. HuMMan, a comprehensive human dataset comprising of 1000 human participants collected in a total of 400k sequences and 60M frames, was recently presented by SenseTime researchers. Based on the features stated below, HuMMan appears to outperform existing datasets.
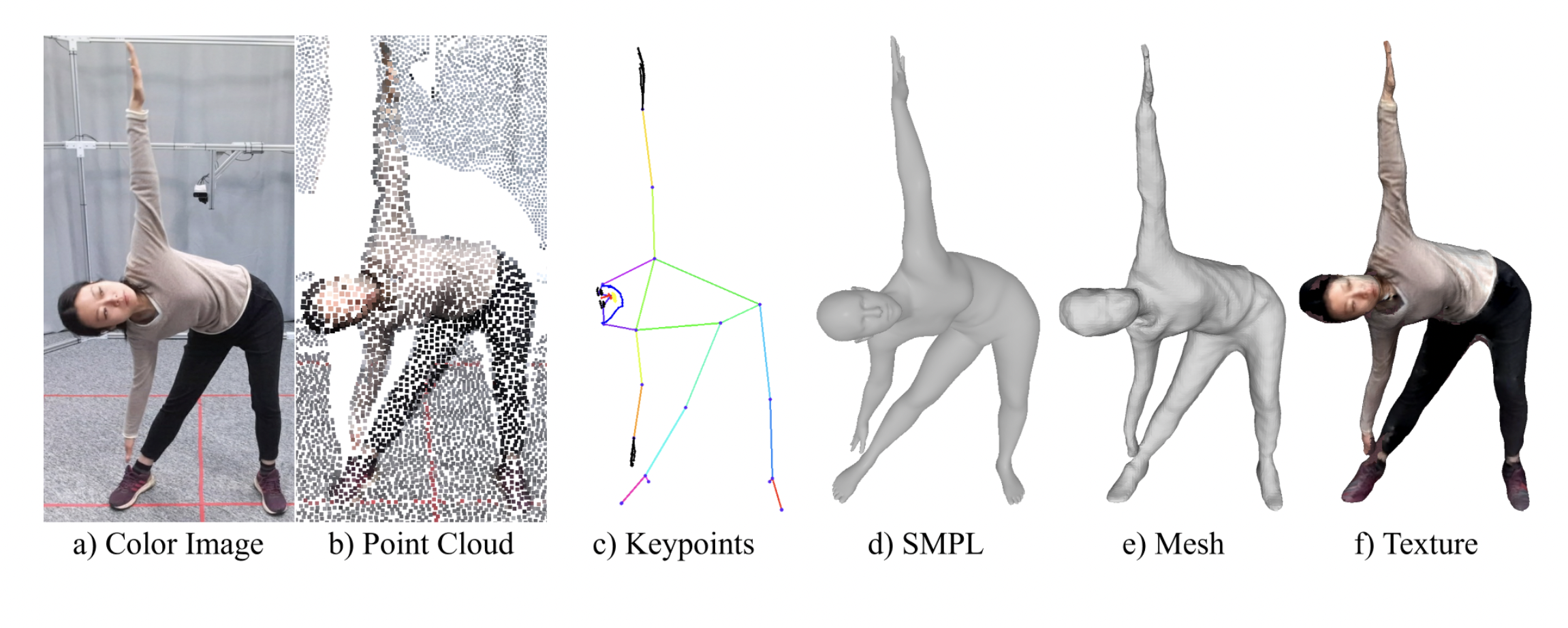
- Multiple Modalities: HuMMan offers a variety of data formats and annotations in the hopes of facilitating nature exploration. HuMMan was created using ten synchronized RGB-D cameras to collect both video and depth sequences.
- Mobile Device: With the advancement of 3D sensors, depth cameras and low-power LiDARs are becoming more ubiquitous on mobile devices. Because of the startling gap between growing real-world applications and the inadequacy of data acquired using mobile devices, the team decided to include a mobile phone with built-in LiDAR in the data collection to make the research more efficient.
- Action Set: HuMMan was created to help researchers better understand human behavior. Instead of choosing daily tasks, the researchers advised categorizing body motions according to the muscles that drive them.
- Multiple Tasks: The researchers created a set of baselines and standards for action recognition, 2D and 3D posture estimation, and mesh reconstruction to aid research on HuMMan. Standard metrics are used to implement and assess popular approaches.
HuMMan’s numerous tests show that it can be used in a variety of domains, including fine-grained action recognition, point cloud-based parametric human recovery, dynamic mesh sequence reconstruction, and knowledge transfer across devices.

HuMMan has 1000 individuals representing a wide range of genders, ages, body types, and ethnicities. To produce a vast array of natural appearances, the subjects were advised to wear their own everyday attire.
HuMMan includes action labels as well as 3D skeleton locations, demonstrating its utility in 3D action recognition. The abundance of intra-actions in HuMMan was thought to be the cause of this occurrence. This forces the model to focus more on the subtle distinctions between these actions. As a result, the team discovered that HuMMan might be used as a rough guide for fine-grained action comprehension.
Conclusion
HuMMan, a large-scale 4D human dataset with multi-modal data and annotations, was presented by SenseTime researchers. Fine-grained action identification, point cloud-based parametric human estimate, dynamic mesh sequence reconstruction, transferring knowledge across devices, and perhaps multi-task joint training are all areas where future study is needed. HuMMan, according to the team, will aid in the development of better algorithms for sensing and modeling humans.
Project: https://caizhongang.github.io/projects/HuMMan/
Paper: https://arxiv.org/pdf/2204.13686.pdf
Credit: Source link
Comments are closed.