Researchers at Stanford developed an Artificial Intelligence (AI) Model called ‘RoentGen,’ based on Stable Diffusion and fine-tuned on a Large Chest X-ray and Radiology Dataset
Latent diffusion models (LDMs), a subclass of denoising diffusion models, have recently acquired prominence because they make generating images with high fidelity, diversity, and resolution possible. These models enable fine-grained control of the image production process at inference time (e.g., by utilizing text prompts) when combined with a conditioning mechanism. Large, multi-modal datasets like LAION5B, which contain billions of real image-text pairs, are frequently used to train such models. Given the proper pre-training, LDMs can be used for many downstream activities and are sometimes referred to as foundation models (FM).
LDMs can be deployed to end users more easily because their denoising process operates in a relatively low-dimensional latent space and requires only modest hardware resources. As a result of these models’ exceptional generating capabilities, high-fidelity synthetic datasets can be produced and added to conventional supervised machine learning pipelines in situations where training data is scarce. This offers a potential solution to the shortage of carefully curated, highly annotated medical imaging datasets. Such datasets require disciplined preparation and considerable work from skilled medical professionals who can decipher minor but semantically significant visual elements.
Despite the shortage of sizable, carefully maintained, publicly accessible medical imaging datasets, a text-based radiology report often thoroughly explains the pertinent medical data contained in the imaging tests. This “byproduct” of medical decision-making can be used to extract labels that can be used for downstream activities automatically. However, it still demands a more limited problem formulation than might otherwise be possible to describe in natural human language. By prompting pertinent medical terms or concepts of interest, pre-trained text conditional LDMs could be used to synthesize synthetic medical imaging data intuitively.
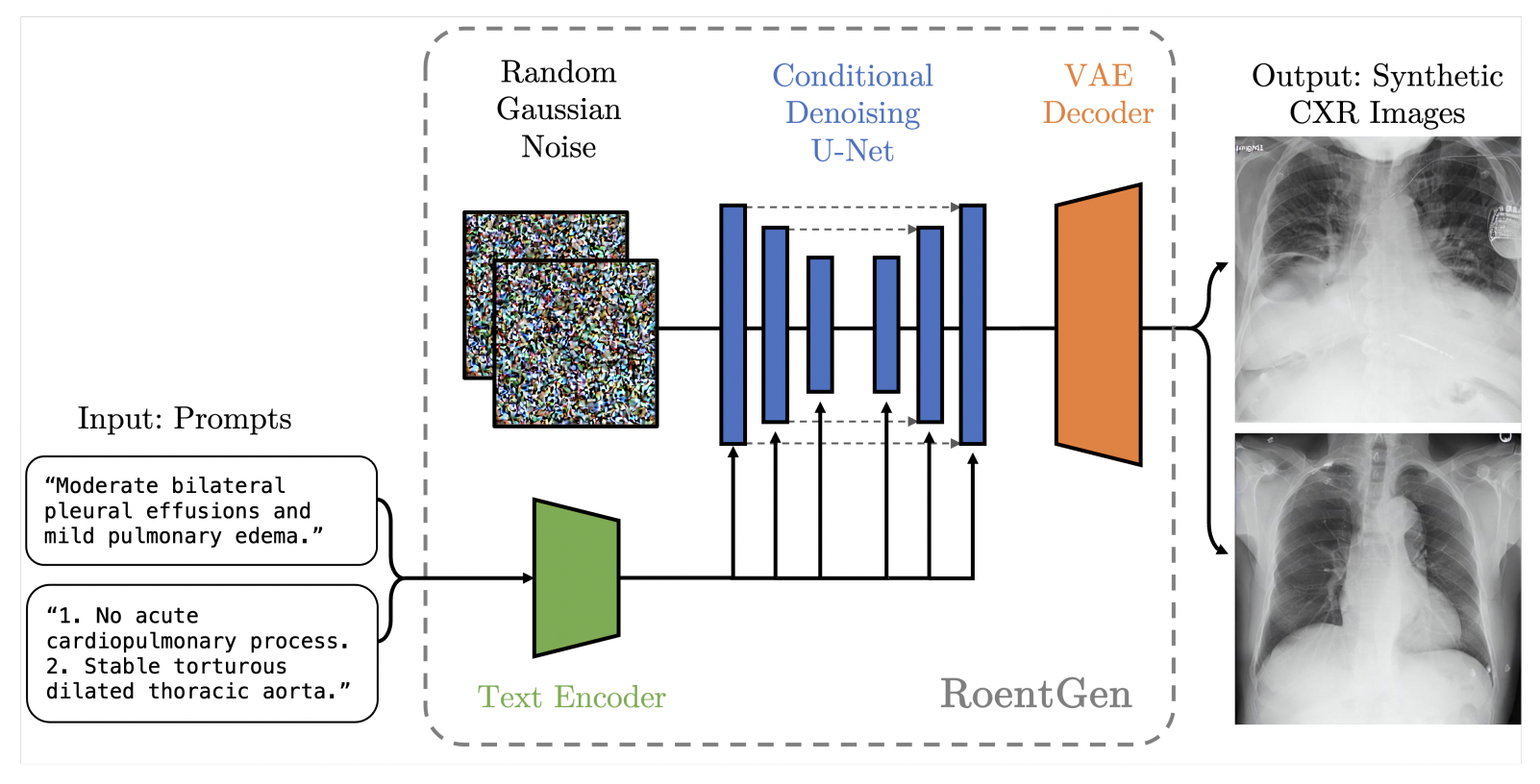
This study examines how to adapt a big vision-language LDM (Stable Diffusion, SD) to medical imaging ideas without specific training on these concepts. They investigate its application for producing chest X-rays (CXR) conditioned on brief in-domain text prompts to take advantage of the vast image-text pre-training underlying the SD pipeline components. CXRs are one of the world’s most frequently utilized imaging modalities because they are simple to get, affordable, and able to provide information on a wide range of significant medical disorders. The domain adaptation of an out-of-domain pretrained LDM for the language-conditioned creation of medical images beyond the few- or zero-shot context is systematically explored in this study for the first time, to the authors’ knowledge.
To do this, the representative capacity of the SD pipeline was assessed, quantified, and subsequently increased while investigating various methods for enhancing this general-domain pretrained fundamental model for representing medical ideas specific to CXRs. They provide RoentGen, a generative model for synthesizing high-fidelity CXR that can insert, combine, and modify the imaging appearances of different CXR findings using free-form medical language text prompts and incredibly accurate picture correlates of the relevant medical concepts.
The report also identifies the following developments:
1. They present a comprehensive framework to assess the factual correctness of medical domain-adapted text-to-image models using domain-specific tasks of i) classification using a pretrained classifier, ii) radiology report generation, and iii) image-image- and text-image retrieval.
2. The highest level of image fidelity and conceptual correctness is achieved by fine-tuning the U-Net and CLIP (Contrastive LanguageImage Pre-Training) text encoders, which they compare and contrast other methods for adapting SD to a new CXR data distribution.
3. When the text encoder is frozen, and only the U-Net is trained, the original CLIP text encoder can be substituted with a domain-specific text encoder, which results in increased performance of the resultant stable diffusion model after fine-tuning.
4. The text encoder’s ability to express medical concepts like uncommon abnormalities is enhanced when the SD fine-tuning job is utilized to extract in-domain knowledge and trained along the U-Net.
5. RoentGen can be fine-tuned on a small subset of images (1.1- 5.5k) and can supplement data for later image classification tasks. In their setup, training on both real and synthetic data improved classification performance by 5%, with training on synthetic data only performing comparably to training on real data.
Check out the Paper and Project. All Credit For This Research Goes To Researchers on This Project. Also, don’t forget to join our Reddit page and discord channel, where we share the latest AI research news, cool AI projects, and more.
![]()
Aneesh Tickoo is a consulting intern at MarktechPost. He is currently pursuing his undergraduate degree in Data Science and Artificial Intelligence from the Indian Institute of Technology(IIT), Bhilai. He spends most of his time working on projects aimed at harnessing the power of machine learning. His research interest is image processing and is passionate about building solutions around it. He loves to connect with people and collaborate on interesting projects.
Credit: Source link
Comments are closed.