Researchers at Stanford have developed an Artificial Intelligence (AI) Model, SUMMON, that can generate Multi-Object Scenes from a Sequence of Human Interaction

Capturing and synthesizing realistic human motion trajectories can be extremely useful in virtual reality, game character animations, CGI, and robotics. We need large datasets to help push machine learning research in this field. Still, the catch is constructing such high-quality datasets annotated with human motions and 3D object placements is very costly and constrained. The data generation pipelines used for creating such datasets involve expensive devices like MoCap systems, structure cameras, and 3D scanners; hence are limited to laboratory settings which is a bottleneck on scene diversity.
A team of researchers from Stanford University came together to solve the novel problem of synthesizing the scenes only from human motion trajectories.

They proposed SUMMON ( Scene Synthesis from HUMan MotiON). SUMMON can produce a diverse set of plausible object placements in a scene only from human motion trajectories, as shown in Figure 1. SUMMON facilitates its predictions mainly in two main steps. Firstly, a human-scene contact predictor (ContactFormer) predicts the vertices in a human mesh that are in contact with any object. Secondly, a scene synthesizer finds an object that fits the contact points from the previous step, as shown in Figure 2. In addition, it also populates the scene with various objects that are not in contact and fits well in the scene. The ContactFormer in SUMMON uses transformer to incorporate temporal information to enhance the consistency of the prediction of contact points in a human motion sequence.
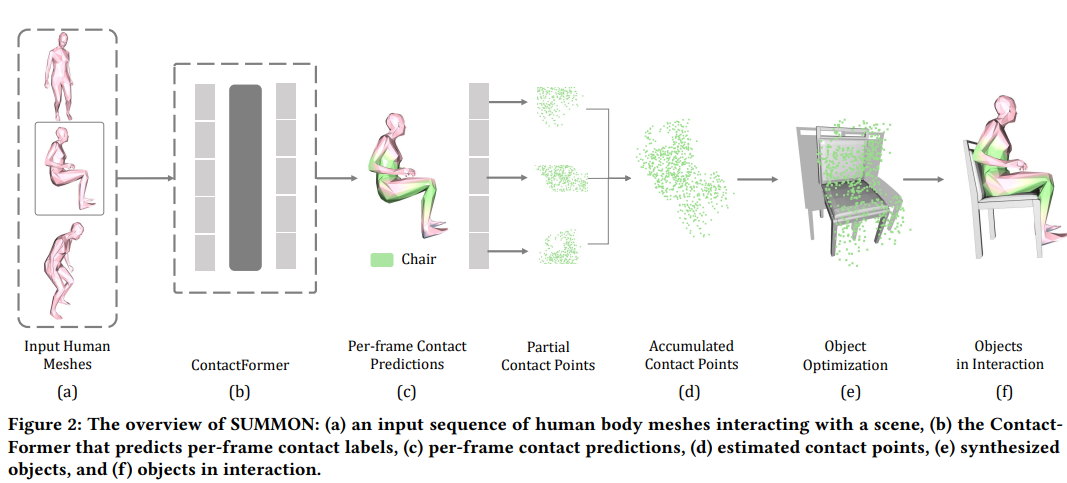
They used a modified version of SMPL-X to represent the human body poses, and for computational purposes, they reduced the number of vertices of mesh from 10475 to 655 points. The dataset consists of sequences of pairs of vertices with corresponding F. Corresponding to each vertex, they have a one-hot vector f of size number of object classes + one “void” class for the vertex not being in contact with any object. F denotes the contact semantic labels(f) for all the vertices in a body pose.
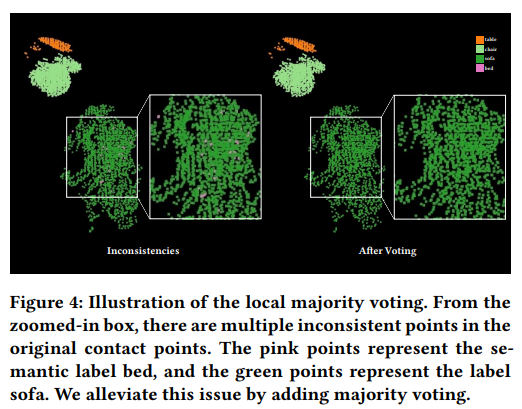
The ContactFormer consists of a conditional GNN (graph neural network) Encoder-decoder architecture and a transformer layer to enhance prediction consistency by modeling temporal dependencies, as shown in Figure 3. Once the object in contact is predicted, the model has been trained using a combination of two losses, ensuring that the object remains in contact with the human mesh and does not penetrate it. For this purpose, the SUMMON also rearranges the object’s orientation in contact. Once we get the contact points, the scene synthesis model further reduces the spatial prediction noise by majority voting for the object class in contact, as shown in Figure 4.
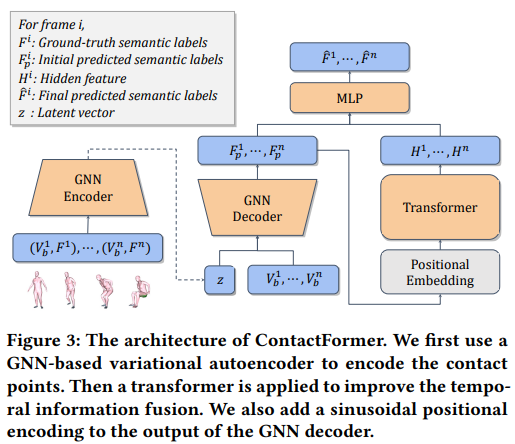
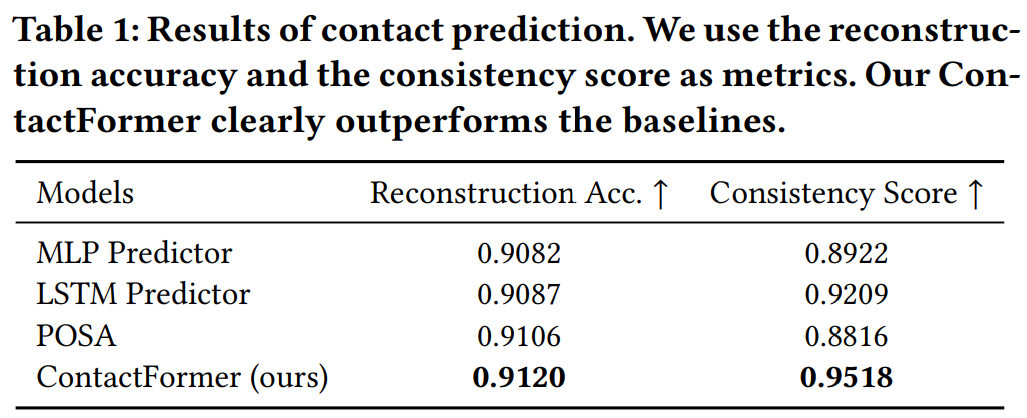
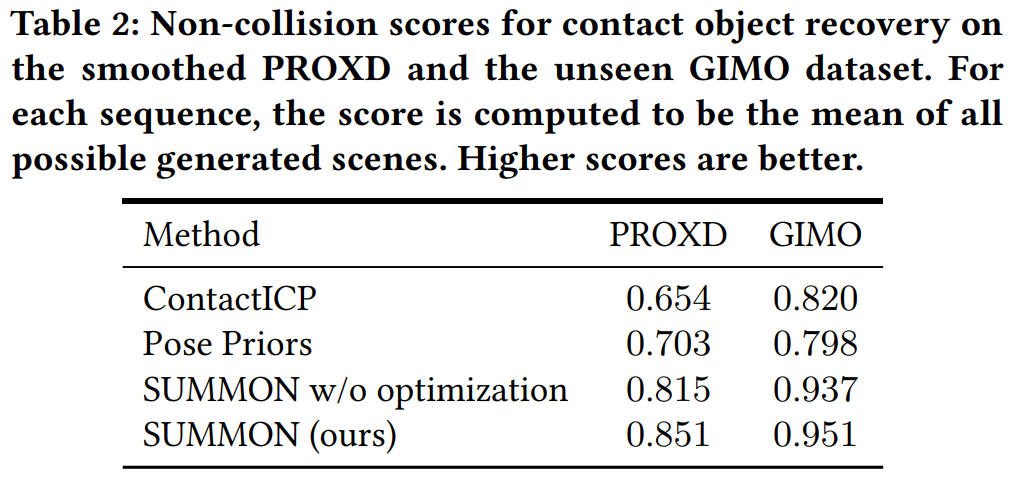
In addition, a transformer model is trained on the 3D-Front dataset, which takes as input the existing categories that are present in the scene and predicts the future categories that will fit well in the scene at empty spaces. It helps complete the scene by placing different objects, not in contact with the human mesh. As for the datasets, the PROXD dataset is used for training SUMMON, and the GIMO dataset is used for testing. Reconstruction accuracy and consistency score are used as metrics. Reconstruction accuracy is the average correctness of the predicted contact label compared to the ground truth for every vertex. Consistency score intuitively means close contact points should have the same contact semantic labels. The team also performed a user study where they presented the user with human motion sequences and the predicted objects in the scenes and asked them to choose the most plausible and realistic placement, 74.5% of users preferred SUMMON over other baselines. The results are shown in Table 1 and Table 2. Figure 6 shows some visualization of prediction from all the baselines.

In conclusion, SUMMON has immense applications in real-life scenarios. It can be used to create diverse human-scene interaction datasets only from human motion sequences, for animations and CGI, etc. The team also discussed the future of research in this direction. As for now, SUMMON only deals with Hard-body contacts. It can be further extended to soft bodies also. Another research direction can be dealing with dynamic scenes, where the object in the scene moves during human motion etc.
Check out the Paper, Code, and Project. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
Credit: Source link
Comments are closed.