Researchers at Stanford Propose A Cheap And Scalable Data Selection Framework Based on Importance Resampling For Improving The Downstream Performance of Language Models
The performance of language models (LMs) depends largely on the kind of training dataset chosen. This holds true for both general-domain models like GPT-3 as well as domain-specific models like Minerva. Most of the existing works rely on heuristics to select training data. For instance, heuristic classification is a technique used by general-domain models like GPT-3 and PaLM to build a training dataset that contains information similar to a high-quality reference corpus like Wikipedia. Domain-specific datasets, on the other hand, are typically manually curated by specialists using various techniques. However, there is a substantial need for a framework that can be employed for automating the data selection process. As a result, more pertinent training data would be available for both general-domain and domain-specific examples, saving both time and human labor.
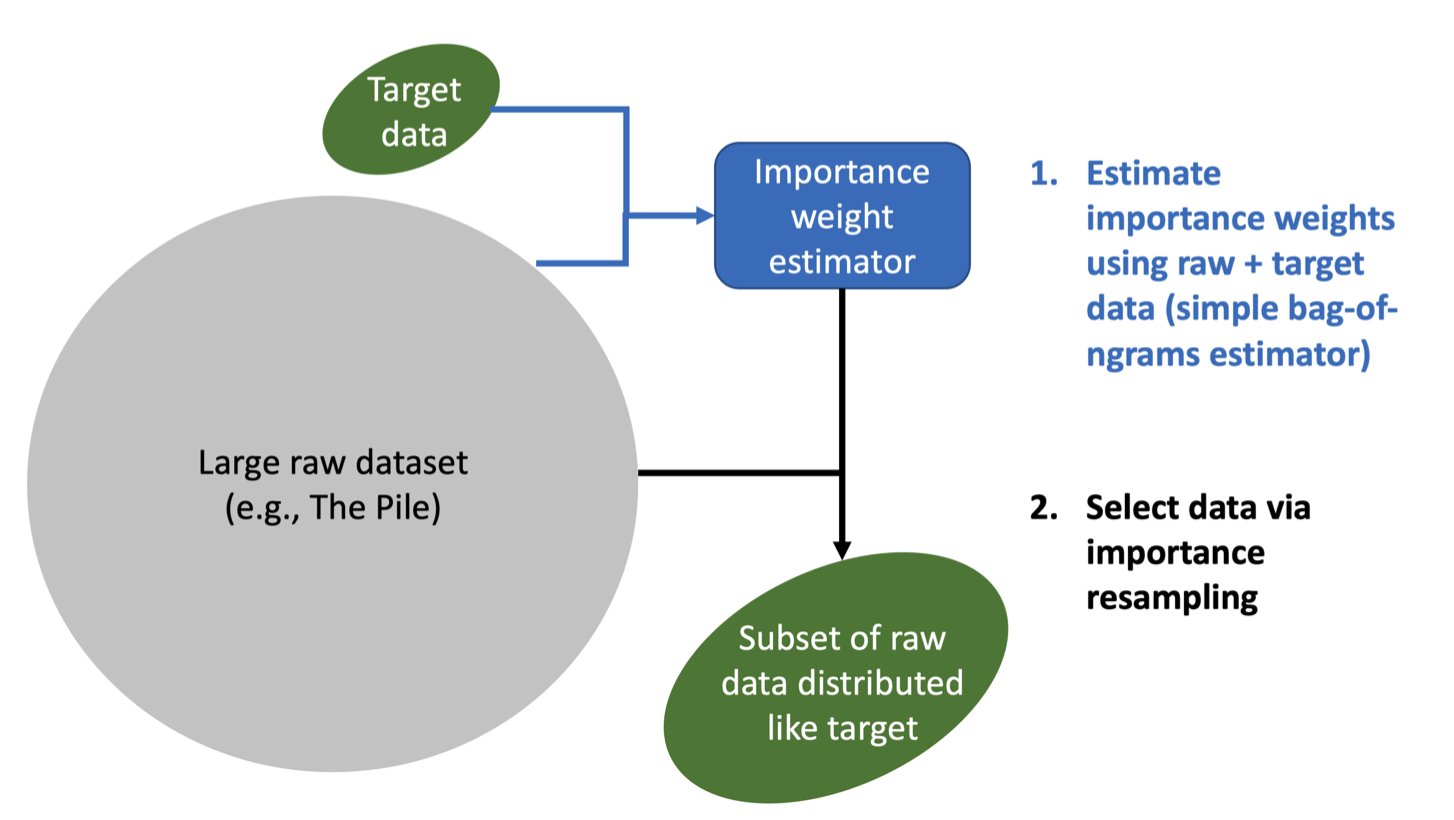
A group of academics at Stanford University studied this data selection problem and proposed an important resampling framework and algorithm in their paper titled ‘Data Selection for Language Models via Importance Resampling.’ The data selection problem can be formulated as choosing a subset of a large raw unlabeled dataset to match a desired target distribution given certain unlabeled target samples. Importance resampling—a technique where raw data is resampled according to weights—has been a common strategy used by researchers in the past. However, determining importance weights on high-dimensional data is frequently statistically challenging. Instead, the Stanford research team improves upon the conventional importance resampling strategy employed in low dimensions for LM data selection. The main differentiating factor introduced by the team was to effectively operate in a smaller feature space in order to make important weight estimation tractable over the space.
In other words, the framework suggested by the researchers resamples a subset of raw data in accordance with importance weights generated in this feature space after first mapping the target and raw data onto some feature space. One of the most important characteristics of the framework is its versatility, as it gives the user the option to select the feature space and importance estimator, which enables them to specify particular data characteristics. The researchers showed that KL reduction, a data metric that assesses the closeness of selected data to the target in a feature space, had a high Pearson correlation with the mean accuracy on eight downstream tasks when computed using basic n-gram features.
Based on this observation that proximity in a simple n-gram feature space correlates well with downstream task performance, the researchers proposed the Data Selection with Importance Resampling (DSIR) algorithm. The algorithm estimates importance weights in a reduced feature space and then selects data with importance resampling according to these weights. The DSIR’s simple n-gram features make it a very scalable and effective technique. The researchers considered two settings for their experiments: training general-domain LMs from scratch and continued pretraining of domain-specific LMs. When performing continued pretraining towards a specific domain, DSIR performs favorably to expert-curated data over eight target distributions extending across several disciplines, such as biomedical publications, news, reviews, etc. On the GLUE benchmark, DSIR outperforms random selection and heuristic filtering baselines by 2-2.5% while training general-domain models with Wikipedia + books as the target.
In a nutshell, Stanford researchers’ proposed importance-resampling-based data selection framework is very effective and scalable for enhancing LMs’ downstream performance. Another significant contribution was the team’s observation that the KL reduction data metric substantially corresponds with downstream accuracy and may facilitate new data-centric procedures. The team hopes the research community views their work as a stepping stone toward choosing better training data for downstream transfer in LMs. Regarding future work, the researchers plan to extend their study into data-centric approaches for LM pretraining.
Check out the Paper and Github Link. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 14k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Khushboo Gupta is a consulting intern at MarktechPost. She is currently pursuing her B.Tech from the Indian Institute of Technology(IIT), Goa. She is passionate about the fields of Machine Learning, Natural Language Processing and Web Development. She enjoys learning more about the technical field by participating in several challenges.
Credit: Source link
Comments are closed.