Researchers at Stanford University Introduce a Novel Artificial Intelligence Framework Aimed at Enhancing the Interpretability and Generative Capabilities of Current Models for Varied Visual Concepts
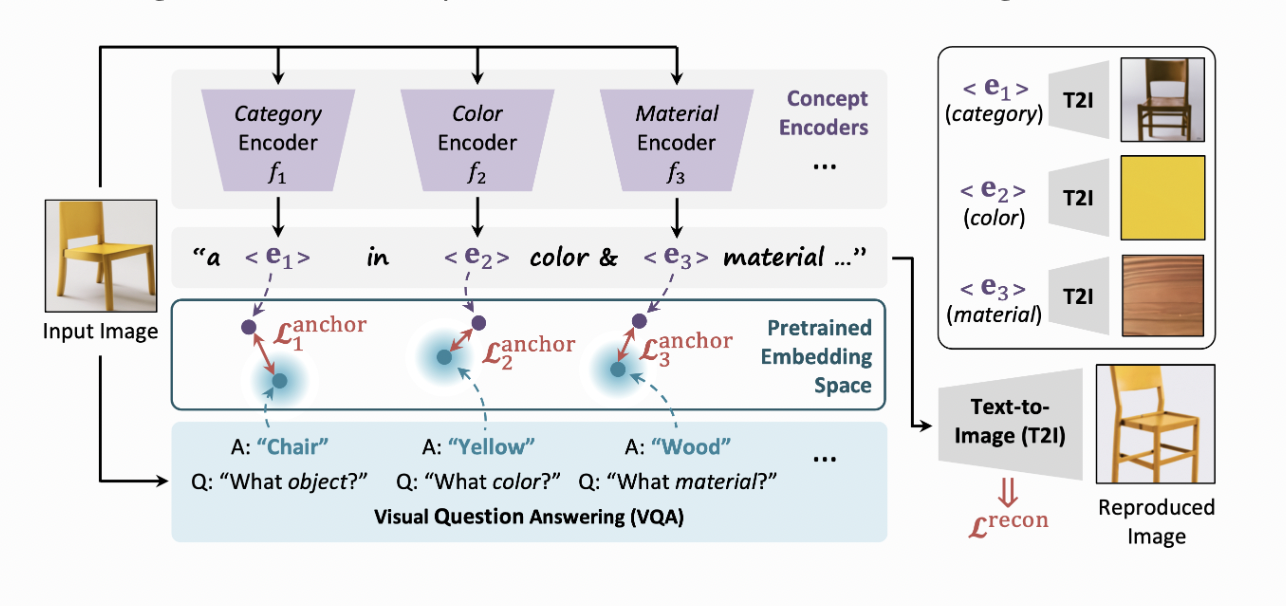
For diverse visual ideas, it is important to have more interpretability and generative capabilities of existing models. Researchers from Stanford University introduced an AI framework for learning a language-informed visual concept representation. This framework trains concept encoders that encode information aligned with language-informed concept axes, anchored to text embeddings from a pre-trained Visual Question Answering (VQA) model.
Concept encoders are trained to encode information aligned with language-informed concept axes. The model extracts concept embeddings from new test images, generates images with novel visual concept compositions, and generalizes to unseen concepts. The approach combines visual prompts and text queries for extracting graphical images and underscores the importance of vision-language grounding in text-to-image generation models.
The study aims to create systems that recognize visual concepts similar to humans. It introduces a framework that uses concept encoders aligned with language-specified concept axes. These encoders extract concept embeddings from images, generating images with novel compositions of concepts.
Within the framework, concept encoders are trained to encode visual information along language-informed concept axes. During inference, the model extracts concept embeddings from new images, enabling the generation of ideas with novel compositions. Comparative evaluation demonstrates superior recomposition results compared to other methods.
The proposed language-based visual concept learning framework outperforms text-based methods. It effectively extracts concept embeddings from test images, generates new compositions of visual concepts, and has better disentanglement and compositionality. Comparative analysis shows better color variation capture and human evaluation indicates high scores for realism and faithfulness to editing instructions.
In conclusion, this study proposes an effective framework for learning language-informed visual concepts through distillation from pre-trained models. The approach shows improved performance in visual concept editing, enabling better disentanglement of concept encoders and the generation of images with novel compositions of visual ideas. The study emphasizes the efficiency of using visual prompts and text queries for controlling image generation with high realism and faithfulness to editing instructions.
The study recommends using larger and more diverse training datasets to improve the language-informed visual concept learning framework. It also suggests exploring the impact of different pre-trained vision-language models and integrating additional concept axes to increase flexibility. The framework should be evaluated across various visual concept editing tasks and datasets. The study identifies bias mitigation in natural images and suggests potential applications in image synthesis, style transfer, and visual storytelling.
Check out the Paper and Project. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.