Researchers at Stanford University Introduce the ‘ASK ME ANYTHING’ PROMPTING (AMA), a Simple Approach that Surprisingly Enables Open-Source LLMs with 30x Fewer Parameters to Exceed the Few-Shot Performance of GPT3-175B
Researchers are getting closer to the aim of task-agnostic machine learning thanks to large language models (LLMs). LLMs are being used to do novel tasks directly instead of training models for them. Instead, LLMs in this paradigm—known as in-context learning—are guided by plain language task descriptions or prompts. A template with placeholders for descriptions and illustrations of the task’s inputs and outcomes defines a prompt. Recent research has assessed the effectiveness of LLM prompting on various activities and shows that the process is fragile, with slight changes to the fast leading to significant performance variances.
The performance also differs according to the selected model size and LLM family. Significant work is put into creating a meticulously flawless prompt to increase dependability. For example, researchers advise users to manually explore broad search spaces of techniques to fine-tune their cues for each activity.
Instead, this study considers combining the predictions of several efficient but flawed prompts to enhance prompting performance across a wide range of models and activities. When given a task input, every prompt generates a vote for the input’s accurate label, and these votes are combined to create the final prediction. They encounter the following difficulties as they work toward aggregation-based high-quality prompting:
- Effective prompts are the first step to benefit from aggregation. They require a prompting framework that applies to various activities and model types.
- Scalable data collection: By identifying efficient, prompt forms, they must acquire numerous prompts in these formats, which will be utilized to gather votes for each input’s actual label.
- Prompt aggregation: A plan that considers the various dependencies and accuracies is required.
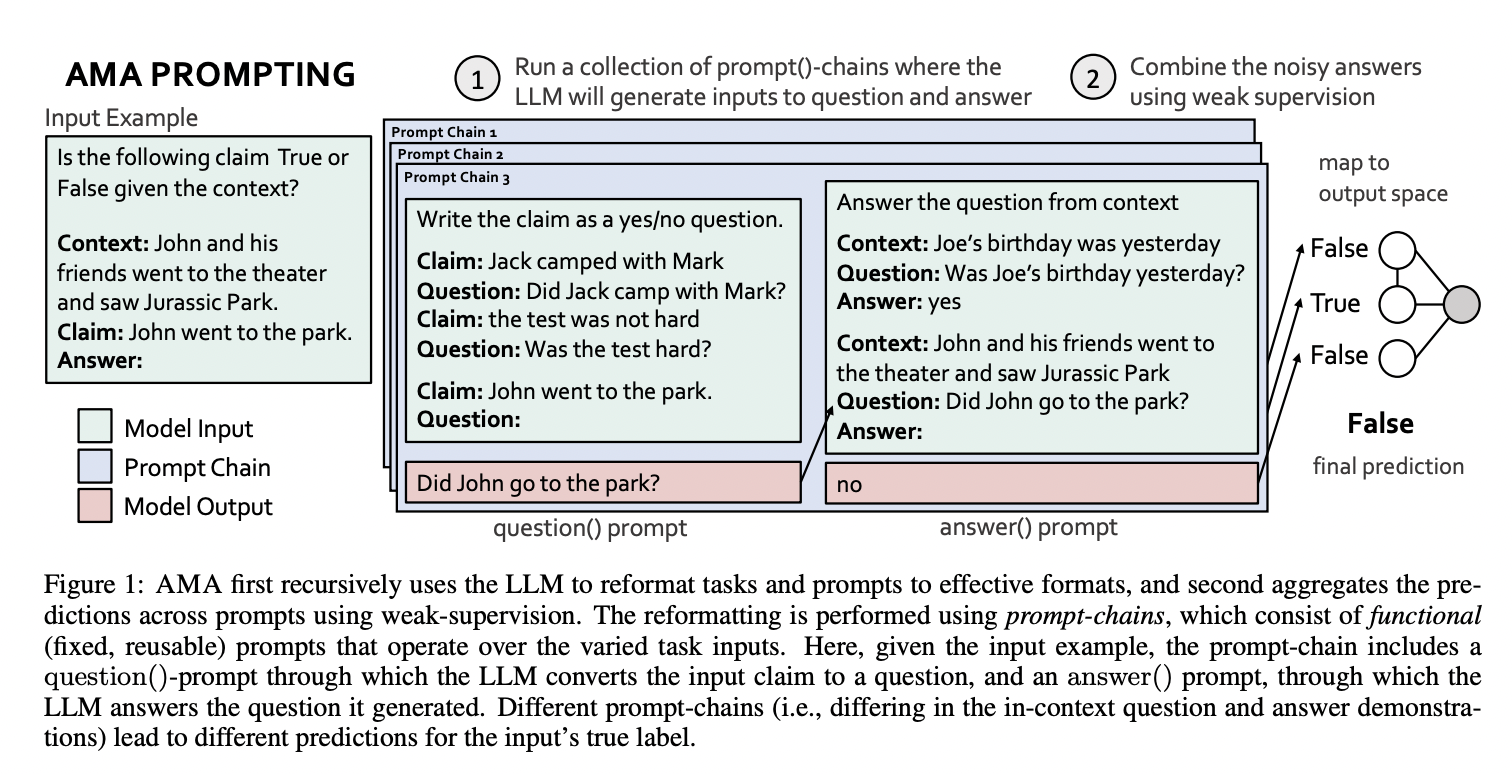
This paper suggests using ASK ME ANYTHING PROMPTING (AMA), a straightforward technique that surprisingly enables open-source LLMs with 30 times fewer parameters to outperform GPT3-175B in a few shots. The following points have been covered in the paper:

- They pinpoint prompting characteristics that increase efficiency across activities, model kinds, and model sizing. They look at common prompt forms characterized by previous research and discover that questions like “Where did John go?” are more successful than questions that limit the model output to specific tokens like “John went to the park. True or False?”).
- They provide a method for effectively reformatting task inputs at scale. They suggest employing the LLM itself in a fixed two-step pipeline to transform task inputs into an efficient open-ended question-answering format iteratively.
- They suggest using weak supervision (WS) to predict accurately and aggregate them. They discover that the inaccuracies caused by the predictions of several chains can vary greatly and are often connected. Although majority vote (MV) may perform admirably on some sets of prompts, it fails miserably in the circumstances covered in the paper.
Most excitingly, ASK ME ANYTHING PROMPTING allows an open-source LLM to meet or outperform the difficult GPT3-175B few-shot baseline results on 15 out of 20 benchmarks while having 30x fewer parameters. They expect that AMA and subsequent work will make it easier to go on with imperfect prompts and enable it to utilize tiny, private, and open-source LLMs, which will alleviate some of the problems associated with using LLMs. The data and running models are freely available on GitHub.
This Article is written as a research summary article by Marktechpost Staff based on the research paper 'ASK ME ANYTHING: A SIMPLE STRATEGY FOR PROMPTING LANGUAGE MODELS'. All Credit For This Research Goes To Researchers on This Project. Check out the paper and code. Please Don't Forget To Join Our ML Subreddit
![]()
Content Writing Consultant Intern at Marktechpost.
Credit: Source link
Comments are closed.