Researchers at Stanford Unveil PLATO: A Novel AI Approach to Tackle Overfitting in High-Dimensional, Low-Sample Machine Learning with Knowledge Graph-Augmented Regularization
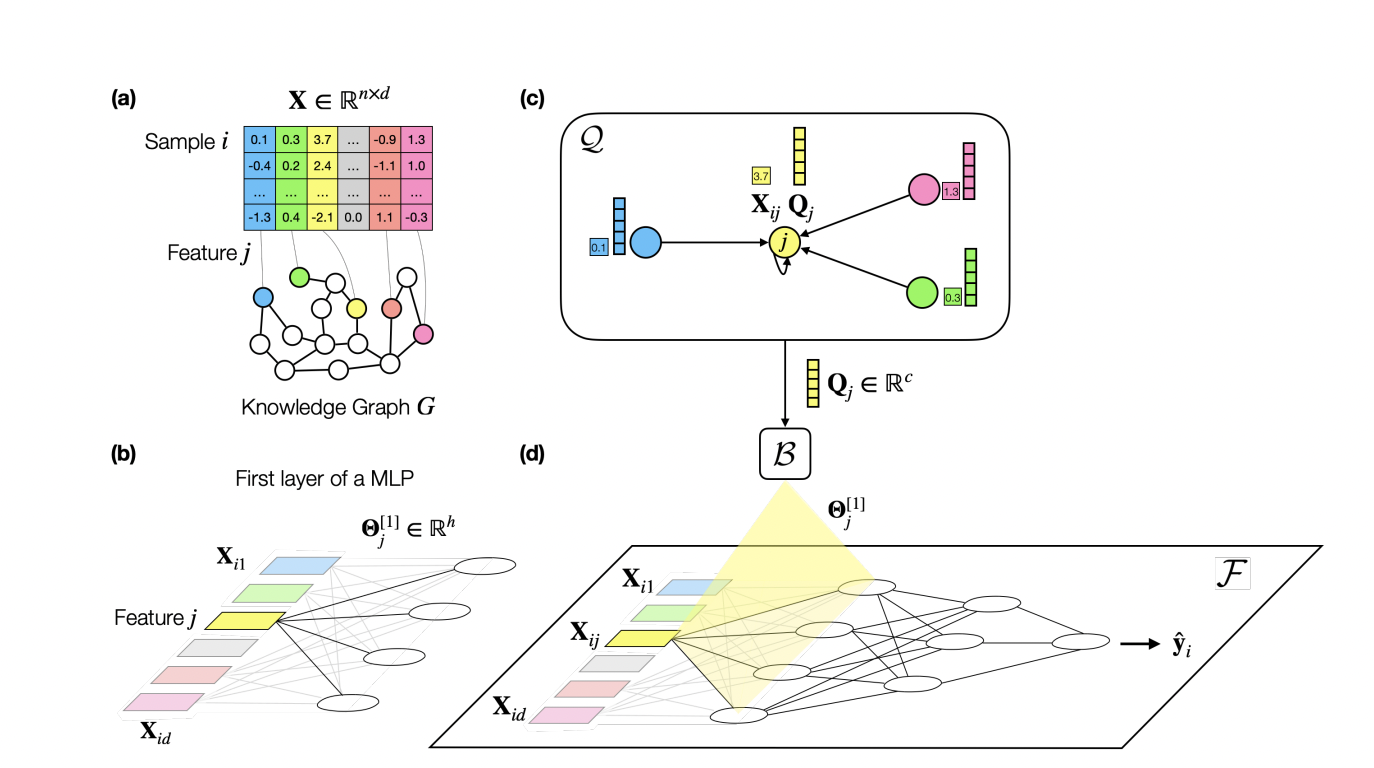
A knowledge graph (KG) is a graph-based database that stores information as nodes and edges. On the other hand, a multilayer perceptron (MLP) is a type of neural network used in machine learning. MLPs are composed of interconnected nodes arranged in multiple layers. Each node obtains input from the previous layer and sends output to the next layer.
Researchers from Stanford University have introduced a new machine learning model called PLATO, which leverages a KG to provide auxiliary domain information. PLATO regularizes an MLP by introducing an inductive bias that ensures similar nodes in the KG have equivalent weight vectors in the MLP’s first layer. This method addresses the challenge of machine learning models needing help with tabular datasets featuring many dimensions compared to samples.
PLATO addresses the underexplored scenario of tabular datasets with high-dimensional features and limited samples, contrasting with existing tabular deep-learning methods designed for settings with more pieces than features. It distinguishes itself from other deep tabular models, such as NODE and tabular transformers, and traditional approaches like PCA and LASSO by introducing a KG for regularization. Unlike graph regularization methods, PLATO incorporates feature and non-feature nodes in the KG. It infers weights for an MLP model, utilizing the graph as a prior for predictions on a distinct tabular dataset.
Machine learning models often excel in data-rich environments but need help with tabular datasets where the number of features greatly surpasses the number of samples. This discrepancy is especially prevalent in scientific datasets, limiting model performance. Existing tabular deep learning approaches mainly focus on scenarios with more examples than features, while traditional statistical methods dominate in the low-data regime with more features than samples. Addressing this, PLATO, a framework utilizing an auxiliary KG to regularize an MLP, enables deep learning for tabular data with features > samples and achieves superior performance on datasets with high-dimensional features and limited models.
Utilizing an auxiliary KG, PLATO associates each input feature with a KG node and infers weight vectors for the first layer of an MLP based on node similarity. The approach employs multiple rounds of message passing, refining feature embeddings. In an ablation study, PLATO demonstrates consistent performance across shallow node embedding methods (TransE, DistMult, ComplEx) in the KG. This innovative method offers potential improvements for deep learning models in data-scarce tabular settings.
PLATO, a method for tabular data with high-dimensional features and limited samples, surpasses 13 cutting-edge baselines by up to 10.19% across six datasets. Performance evaluation involves a random search with 500 configurations per model, reporting the mean and standard deviation of Pearson correlation between predicted and actual values. The results affirm PLATO’s effectiveness, leveraging an auxiliary KG to achieve robust performance in the challenging low-data regime. Comparative analysis against diverse baselines underscores PLATO’s superiority, establishing its efficacy in enhancing tabular dataset predictions.

In conclusion, the research conducted can be summarized in below points:
- PLATO is a deep-learning framework for tabular data.
- Each input feature resembles a node in an auxiliary KG.
- PLATO regulates an MLP and achieves robust performance on tabular data with high-dimensional features and limited samples.
- The framework infers weight vectors based on KG node similarity, capturing the inductive bias that similar input features should share similar weight vectors.
- PLATO outperforms 13 baselines by up to 10.19% on six datasets.
- The use of auxiliary KGs is shown to improve performance in low-data regimes.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 34k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
![]()
Hello, My name is Adnan Hassan. I am a consulting intern at Marktechpost and soon to be a management trainee at American Express. I am currently pursuing a dual degree at the Indian Institute of Technology, Kharagpur. I am passionate about technology and want to create new products that make a difference.
Credit: Source link
Comments are closed.