Researchers at the University of Maryland Propose Cold Diffusion: A Diffusion Model with Deterministic Perturbations

Diffusion models can be interpreted as stochastic encoder/decoder architectures, which are built around a residual architecture that successively applies a learned transformation. To this, additive Gaussian noise is added to degrade the input images until the noise is obtained. The decoder, on the other hand, reproduces an inverse residual pattern that, starting from inverse noise, reverses the degradation and reconstructs a point whose distribution is close to the original image. The term “diffusion” actually comes from the interpretation of these models in statistical mechanics. The decoder can be seen as a residual network evaluating the solution of a stochastic differential equation over time. The associated distribution is then interpreted as the solution of a Fokker-Planck equation (such as the heat equation) that introduces a diffusion term associated with the iteration of Gaussian noise.
It is interesting to note that, while most families of generative models parameterized by neural networks emerged between 2014 and 2015, interest in diffusion models started out like an old diesel engine: first timidly, before exploding, as evidenced by a small Google Trends search. They are now at the heart of a variety of generative AI applications (Midjourney, DALL-E,…) used by the general public. In research, it is becoming important to understand experimentally the underlying principles that explain their effectiveness and to extract their most general characteristics.
In the paper, Cold Diffusion: Inverting Arbitrary Image Transforms Without Noise, the researchers propose to replace the additive Gaussian noise in diffusion models with deterministic and arbitrary transformations, including (blur, subsampling, snowification…). This is not the first time that the use of deterministic degradation within diffusion models has been studied; in “generative modeling with inverse heat dissipation”, the authors were interested in the application of the heat equation to encode images. Indeed, a numerical scheme to integrate the heat equation can be interpreted as a residual linear network whose weights would be fixed. At each step, a reconstruction network R (or decoder) can then be trained to reverse these infinitesimal transformations. However, in their approach, the sampling process still involved the use of additive Gaussian noise at each iteration.
In the paper presented here, the model is trained as an autoencoder in which parameters of the encoder that applies a degradation that remains fixed during training. Thus, for different levels of degradation parameterized by the variable t, the reconstruction network R minimizes the reconstruction error associated with this architecture. In the paper, the authors chose to use an L1 norm for this :
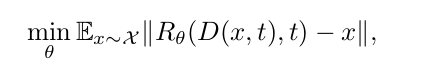
In diffusion models, image generation consists of sampling a point in the latent space of degraded images. Once the point is sampled, a ResNet can be applied and constructed as follows:
At each step, a point is evolved by successively applying the reconstruction network R and then adding another perturbation (usually Gaussian). We shall notice that in this paper, the degraded images have very simple distributions and can be fitted by a GMM, for example.
The main contribution of the authors is to show that this algorithm does not generate realistic samples when the degradation is fixed, they then propose a new sampling method to overcome this effect.

The authors perform experiments with classic datasets used in generative modelings such as MNIST, CIFAR, and CelebA. While they didn’t involve stochastic perturbations over their generating process, the samples generated are convincing, although slightly less realistic than those found in classical approaches. Their sampling methods are applied to inpainting and super-resolution tasks and show superior effectiveness compared to the classic sampling technique when the degradation is fixed and deterministic.
So we have here a paper with the result that at first glance seems very surprising: by sampling points from a very low entropy distribution (Cold), it is possible to reconstruct highly realistic samples of high dimensions (A bit hotter). If we look at the approach from the point of view of information theory, this result seems counterintuitive and contrary to the classical approach where one starts from a very disordered distribution (Hot) to construct highly structured objects of high dimensions (Cold). The authors clarify that it is indeed necessary to add a small Gaussian perturbation to the initial sample to obtain a generative model. However, the idea of using other transformations than white Gaussian noise is interesting and could lead to a better understanding of the generative capacity of these models.
Check out the Paper, Github, and Related Paper. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
![]()
Simon Benaïchouche received his M.Sc. in Mathematics in 2018. He is currently a Ph.D. candidate at the IMT Atlantique (France), where his research focuses on using deep learning techniques for data assimilation problems. His expertise includes inverse problems in geosciences, uncertainty quantification, and learning physical systems from data.
Credit: Source link
Comments are closed.