Researchers at the University of Oxford Introduce DynPoint: An Artificial Intelligence Algorithm Designed to Facilitate the Rapid Synthesis of Novel Views for Unconstrained Monocular Videos
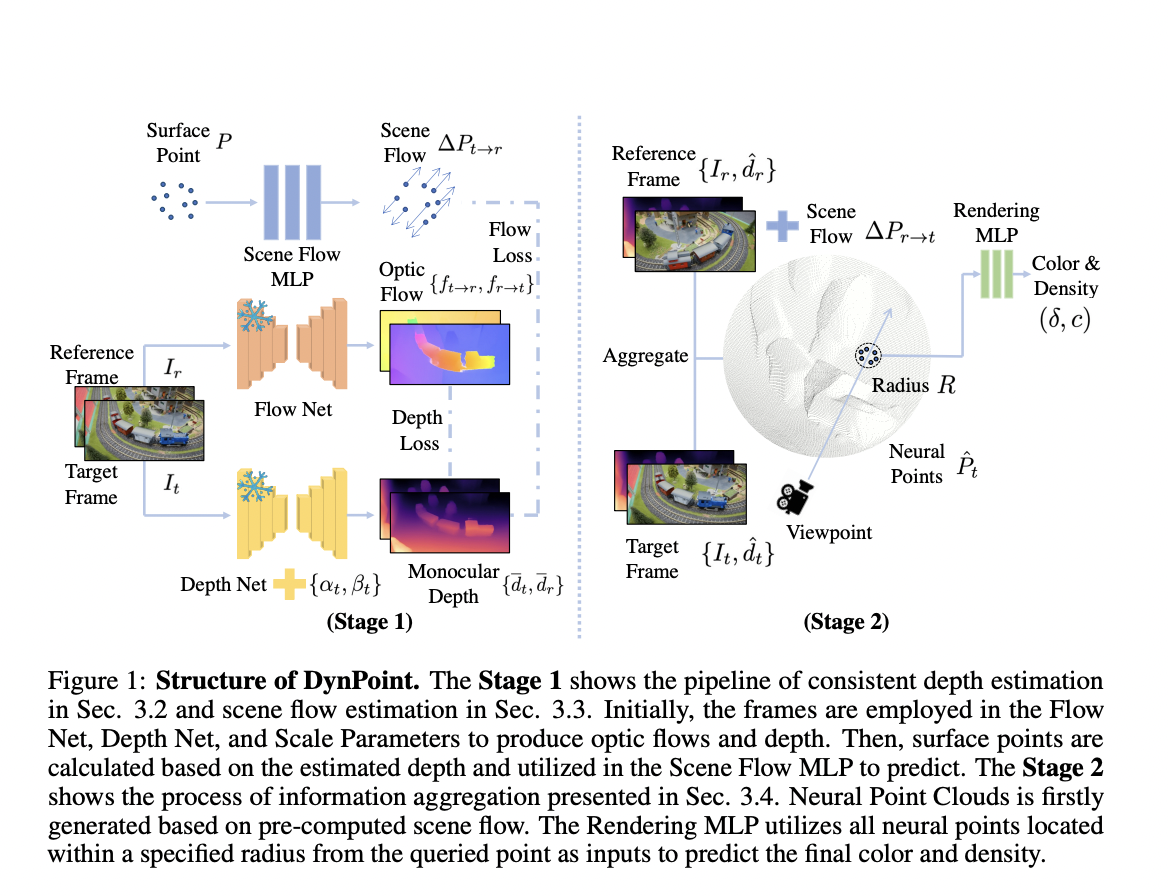
The computer vision community has been focusing significantly on novel view synthesis (VS) due to its potential to advance artificial reality and enhance a machine’s ability to understand visual and geometric aspects of specific scenarios. State-of-the-art techniques utilizing neural rendering algorithms have achieved photorealistic reconstruction of static scenes. However, current approaches relying on epipolar geometric relationships are better suited for static situations, while real-world scenarios with dynamic elements present challenges to these methods.
Recent works have primarily concentrated on synthesizing views in dynamic settings by using one or more multilayer perceptrons (MLPs) to encode spatiotemporal scene information. One approach involves creating a comprehensive latent representation of the target video down to the frame level. However, the limited memory capacity of MLPs or other representation methods restricts the applicability of this approach to shorter videos despite its ability to deliver visually accurate results.
To address this limitation, researchers from the University of Oxford introduced DynPoint. This unique method doesn’t rely on learning a latent canonical representation to efficiently generate views from longer monocular videos. DynPoint employs an explicit estimation of consistent depth and scene flow for surface points, unlike traditional methods that encode information implicitly. Multiple reference frames’ information is combined into the target frame using these estimates. Subsequently, a hierarchical neural point cloud is constructed from the gathered data, and views of the target frame are synthesized using this hierarchical point cloud.
This aggregation process is supported by learning correspondences between the target and reference frames, aided by depth and scene flow inference. To enable the quick synthesis of the target frame within a monocular video, the researchers provide a representation for aggregating information from reference frames to the target frame. Extensive evaluations of DynPoint’s speed and accuracy in view synthesis are conducted on datasets such as Nerfie, Nvidia, HyperNeRF, iPhone, and Davis. The proposed model demonstrates superior performance in terms of both accuracy and speed, as evidenced by the experimental results.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 32k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
We are also on Telegram and WhatsApp.
![]()
Dhanshree Shenwai is a Computer Science Engineer and has a good experience in FinTech companies covering Financial, Cards & Payments and Banking domain with keen interest in applications of AI. She is enthusiastic about exploring new technologies and advancements in today’s evolving world making everyone’s life easy.
Credit: Source link
Comments are closed.