Researchers at the University of Tokyo Developed an Extended Photonic Reinforcement Learning Scheme that Moves from the Static Bandit Problem Towards a more Challenging Dynamic Environment
In the world of machine learning, the concept of reinforcement learning has taken center stage, enabling agents to conquer tasks through iterative trial and error within a specific environment. It highlights the achievements in this field, such as using photonic approaches for outsourcing computational costs and capitalizing on the physical attributes of the light. It underscores the need to extend these methods to more complex problems involving multiple agents and dynamic environments. Through this study from the University of Tokyo , the researchers aim to combine the bandit algorithm with Q-learning to create a modified bandit Q-learning (BQL) that can accelerate learning and provide insights into multiagent cooperation, ultimately contributing to the advancement of the photonic reinforcement technique.
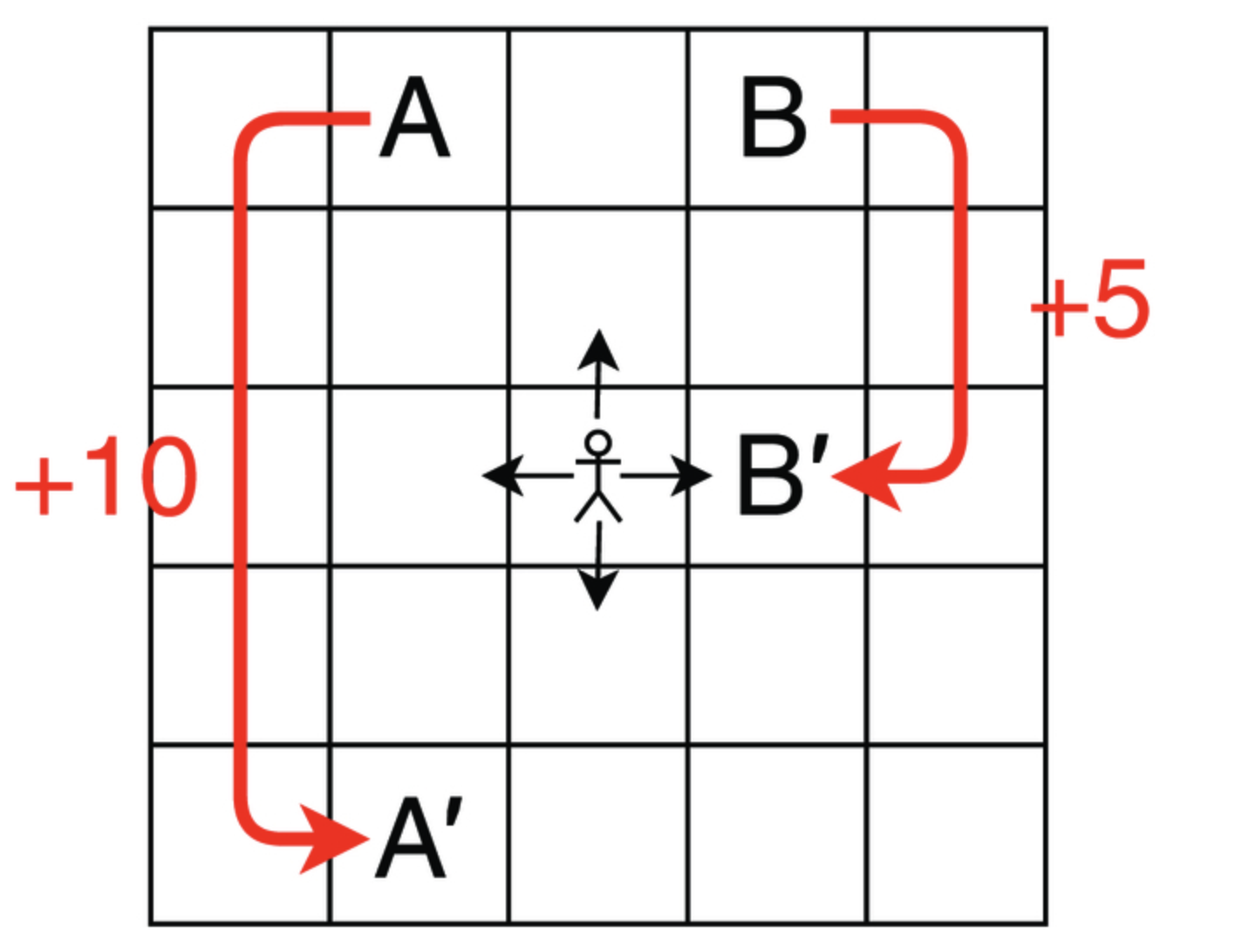
The researchers have used the concept of grid world problems. In this, an agent navigates through within a 5*5 grid, each cell representing a state. At each step, the agent has to take the action- up, down, left, or right and receive the reward and the next state. Specific cell A and B offer higher reward and prompts the agent to shift to different cells. This problem relies on a deterministic policy, where the agent’s action dictates its movement.
The action-value function Q(s, a) quantifies future rewards for state-action pairs given a policy π. This function embodies the agent’s anticipation of cumulative rewards through its actions. The main aim of this study is to enable an agent to learn the optimal Q values for all state-action pairs. A modified Q-learning is introduced, integrating the bandit algorithm and enhancing the learning process through dynamic state-action pair selection.
This modified Q-learning scheme allows for parallel learning where multiple agents update a shared Q-table. Parallelization boosts the learning process by enhancing the accuracy and efficiency of Q-table updates. A decision-making system is envisaged that harnesses the principles of quantum interference of photons to ensure that the agent’s simultaneous actions remain distinct without direct communication.
The researchers plan to develop an algorithm that enables agents to act continuously and apply their method in more complicated learning tasks. In the future, the authors aim to create a photonic system that enables conflict-free decisions among at least three agents, enhancing decision-making harmony.
Check out the Paper and Reference Article. All Credit For This Research Goes To the Researchers on This Project. Also, don’t forget to join our 29k+ ML SubReddit, 40k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, please follow us on Twitter
![]()
Astha Kumari is a consulting intern at MarktechPost. She is currently pursuing Dual degree course in the department of chemical engineering from Indian Institute of Technology(IIT), Kharagpur. She is a machine learning and artificial intelligence enthusiast. She is keen in exploring their real life applications in various fields.
Credit: Source link
Comments are closed.