Researchers at UC Berkeley Introduce a New Competence-Based Algorithm Called Contrastive Intrinsic Control (CIC) For Unsupervised Skill Discovery

In the presence of extrinsic rewards, Deep Reinforcement Learning (RL) is a strong strategy for tackling complex control tasks. Playing video games with pixels, mastering the game of Go, robotic mobility, and dexterous manipulation policies are all examples of successful applications.
While effective, the above advancements resulted in agents that were unable to generalize to new downstream tasks other than the one for which they were trained. Humans and animals, on the other hand, can learn skills and apply them to a range of downstream activities with little supervision. In a recent paper, UC Berkeley researchers aim to teach agents with generalization capabilities by efficiently adapting their skills to downstream tasks.
Unsupervised RL has emerged as a potential approach for constructing RL agents that can generalize to new tasks in recent years. Agents are pre-trained with self-supervised intrinsic rewards in the unsupervised RL scenario and then finetuned to downstream tasks with extrinsic rewards.
Knowledge-based, data-based, and competency-based approaches are the three types of unsupervised RL algorithms. Knowledge-based strategies maximize a predictive model’s inaccuracy or uncertainty. The entropy of the agent’s visitation is maximized using data-based strategies. Competency-based approaches teach skills that result in a wide range of behaviors. This study belongs to the second group of competence-based exploration strategies.
Competence-based algorithms, unlike knowledge-based and data-based algorithms, concurrently solve the exploration difficulty as well as condensing the generated experience into reusable abilities. This makes them especially interesting since the resulting skill-based policies (or talents) can be finetuned to tackle downstream tasks efficiently. While there are numerous self-supervised objectives that can be used, this work belongs to a family of strategies for learning skills that maximize the mutual information between visited states and latent skill vectors.
The team looks at the issues of pre-training agents with competence-based algorithms in this paper. They present Contrastive Intrinsic Control (CIC), an exploration technique that employs a new mutual information objective estimator. CIC combines particle estimation for state entropy with noise contrastive estimation for conditional entropy, allowing it to both produce and differentiate high-dimensional continuous skills (exploration) (exploitation).
CIC is the first exploration technique to distinguish between state transitions and latent skill vectors using contrastive noise estimation. On the Unsupervised Reinforcement Learning Benchmark, the team shows that CIC adapts to downstream tasks more efficiently than previous exploratory algorithms (URLB). CIC outperforms previous competence-based algorithms on downstream tasks by 79 percent and outperforms the next-best exploration method by 18 percent overall.
The RL optimization algorithm and the CIC architecture are the two key components of the practical implementation. The team utilizes the same RL optimization methodology for the method and all baselines in this work for fairness and clarity of comparison. Researchers chose the same DDPG architecture to optimize our method because the baselines implemented in URLB employ a DDPG5 as their backbone.
The team uses the same competency-based method adaptation procedure as in URLB to adapt to downstream tasks. The team fills the DDPG replay buffer with samples during the first 4k environment interactions and leverages the extrinsic rewards acquired during this time to finetune the skill vector z. While finetuning abilities through Cross-Entropy Adaptation (CMA) is typical, the team shows that a basic grid sweep of skills across a DDPG delivers state-of-the-art performance on DeepMind Control and is more reliable than SAC on this benchmark, given the constrained budget of 4k samples (just four episodes).
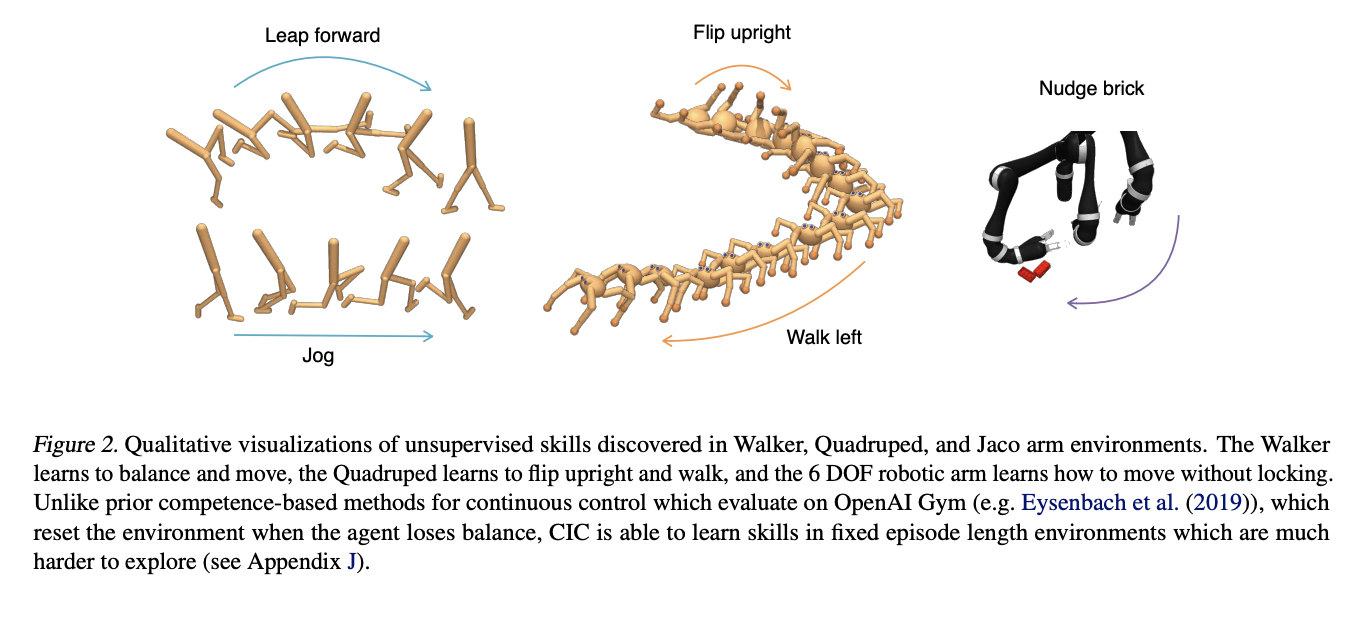
The researchers tested their method on URLB tasks, which include twelve downstream tasks spread among three difficult continuous control domains for exploration algorithms: walker, quadruped, and Jaco arm. To complete locomotion tasks while balancing, a biped must be restricted to a 2D vertical plane. Quadruped is more difficult because of higher-dimensional state-action space, and it requires a quadruped to master locomotion abilities in a 3D environment. The Jaco arm is a six-degree-of-freedom robotic arm with a three-finger gripper for manipulating and moving things without locking. In the absence of an extrinsic reward, all three situations are difficult.
CIC significantly beats past competence-based algorithms (DIAYN, SMM, APS) in expert normalized scores, obtaining a 79 percent higher IQM than the next best competence-based technique (APS) and, more broadly, producing an 18 percent higher IQM than the next best overall baseline (ProtoRL). The team discovers that CIC’s ability to handle far bigger continuous skill spaces than previous competence-based techniques is one of the contributing elements to its performance.

Conclusion
Contrastive Intrinsic Control (CIC), developed by UC Berkeley researchers, is a new competence-based algorithm that allows for more effective exploration than previous unsupervised skill discovery algorithms by explicitly encouraging diverse behavior while distilling predictable behaviors into skills using a contrastive discriminator. They demonstrate that CIC is the first competency-based method to obtain top results on URLB. The researchers believe that this will spur more study towards constructing generalizable RL agents.
Paper: https://arxiv.org/pdf/2202.00161.pdf
Github: https://github.com/rll-research/cic
Reference: https://bair.berkeley.edu/blog/2022/02/23/cic/
Suggested
Credit: Source link
Comments are closed.